A slice of life: table partitioning in PostgreSQL databases



In any successful project, a surge in traffic, accompanied by increasing amounts of data which must be stored and processed, is an inevitability. Accordingly, the database itself is typically one of the main bottlenecks during rapid business growth because data volume directly affects query execution speed.
You might try tolerating this speed degradation for a bit, or you could attempt to scale your system via additional resources (although, let’s be blunt here—this isn’t the most affordable way of solving the problem). Further still, there’s also a cheaper and much more efficient solution available: partitioning.
Partitioning itself is certainly not a one-size-fits-all solution. It only really makes sense in situations where the data in a large table can be divided into groups according to some criteria. That being said, you’ll come across cases like this quite often, since tables frequently contain data fields that allow for easy grouping (a typical example of this would be timestamps). Hence, there are a wide range of situations where you’ll be able to use partitioning.
This article was made with Ruby on Rails developers in mind, but backend engineers of all sorts can feel free to read on, too!
An introduction to partitioning
Partitioning involves splitting large tables into smaller ones according to some attribute (like time ranges, regions, or even user ID groups). This is a logical step, and it can significantly increase your performance. But a botched implementation can have unintended effects, thus losing potential benefits, and turning your work with the database into a complete nightmare (more on this later).
What are the benefits of partitioning? Well, first of all, for us as database users and Ruby developers, almost nothing changes—prior to partitioning, we were working with and referencing one big table to read and write. Afterwards, we still end up working and reference a big (now technically virtual) table, but with many small tables (partitions) inside of it. This leads to the primary benefit: speed! When writing data, although we reference all of the partitions as we would reference a single table, the new record is only inserted into one of the partitioned tables. Plus, reading data also becomes faster, but only if we read data from one or several partitions (otherwise, a search across an unpartitioned table may be faster).
In PostgreSQL, there are 2 ways of partitioning:
- The old method, via inheritance (engineers were using this technique way before partitioning received official PostgreSQL support).
- Declarative partitioning, which we got in PostgreSQL 10. This is a convenient way to create and manage partitions, and is provided by the database management system (DBMS) itself, although it uses the same inheritance mechanism under the hood.
We recommend using declarative partition since this method offers official support and DMBS developers continue to expand its capabilities with each new version. That being said, if, for any reason, you need to implement partitioning using the outdated method, you can read this article: Partition and conquer. (But please keep in mind that this method is trickier to implement in a Rails context and it’s now considered a legacy approach.)
Some hints for getting started
Let’s give some quick background about the scope of our work, and we’ll set up an example which we’ll relate to the topic of partitioning. At Evil Martians, we were the core tech team running the eBaymag project for more than 7 years. In terms of engineering, the product was built entirely around event processing. This means we were always working with events and handlers in order to process every event. We were storing events in the database, processing them in the background using Sidekiq, and marking them as “completed.”
Every week we received and processed over 30 million events. Of course, we cleaned them up when they expired, but some events had to be stored for a very long time because they were logs of what had happened with the user’s products on this ecommerce platform (most commonly these involved sales or quantity changes). Once the table had bloated to 300 million records, queries began running more slowly, and performance started to degrade. What to do? Well, we solved this problem with partitioning!
Let’s take a look! So, there are 2 tables connected by uuid—event_store_messages (with raw event data) and event_store_completions (for data about event processing).
Here’s the event_store_messages schema:

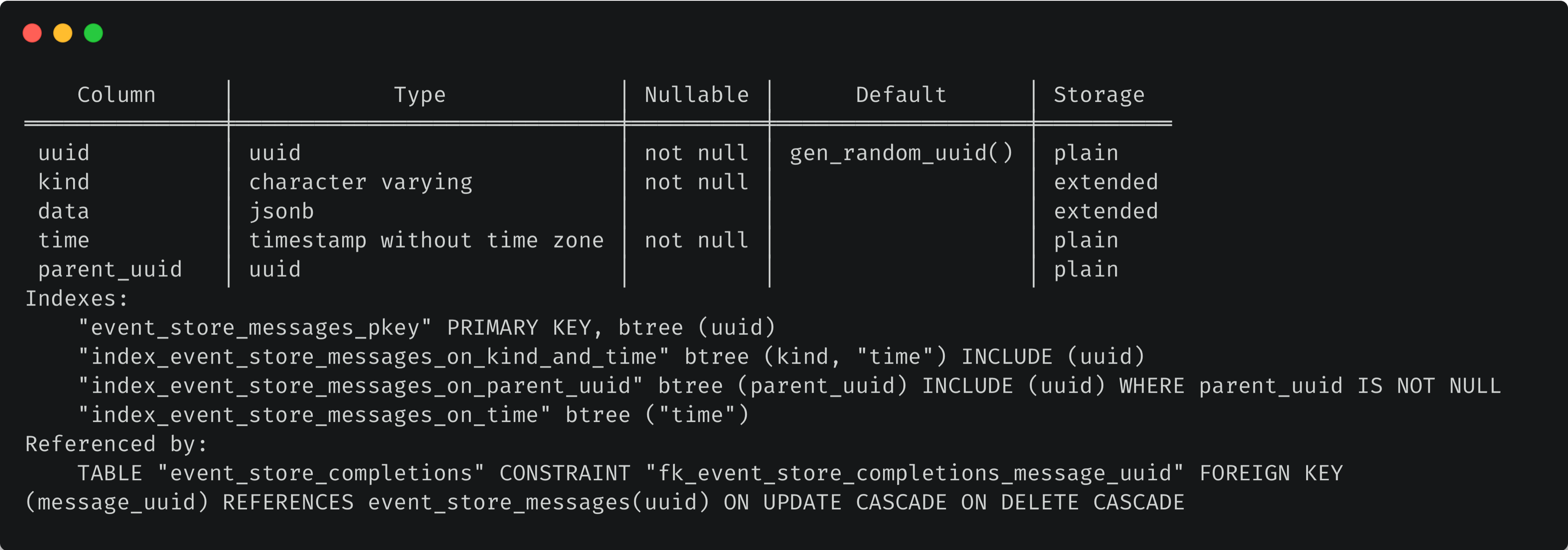
And the schema for event_store_completions:

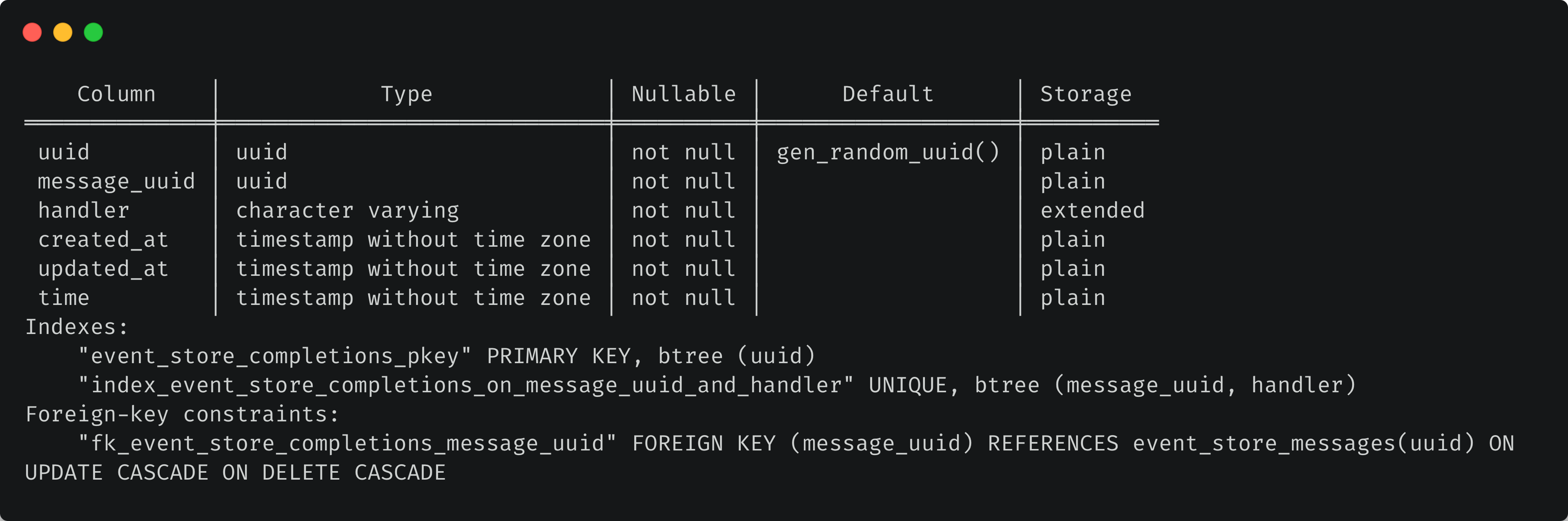
Since these tables are interconnected, and as both contain a huge amount of data, we’ll partition them both.
But how will we do that? Considering that we work with events, it would be quite convenient to use time (via the time column) as the criterion to split our table. For instance, partitioning by weeks will speed up query execution and, in general, make event processing more convenient since we need the most recent events for SQL operations. Over time, old entries lose their relevance and can be removed. Therefore, we’ll choose partitioning by range.
First, we need to create a partitioned table: its schema will be identical to our original schema table, and the original table will become the first partition. Why? This is because it’s impossible to turn an ordinary table into a partitioned table (and vice versa).
We’ll create our partitioned table, event_store_messages_partitioned:
CREATE TABLE event_store_messages_partitioned
(
uuid uuid DEFAULT gen_random_uuid() NOT NULL,
kind character varying NOT NULL,
data jsonb,
"time" timestamp WITHOUT TIME ZONE NOT NULL,
parent_uuid uuid
) PARTITION BY RANGE ("time");Now we’ll add the primary key, and note that it must contain the “time” partition key (it is one of PostgreSQL’s requirements for partitioned tables, see: declarative partitioning limitations):
📝 Note: The primary composite key allows us to create entries with the same uuid. At the same time, since unique constraints must include a partition key, we cannot ensure that the uuid is unique.
Adding the primary key:
ALTER TABLE event_store_messages_partitioned
ADD CONSTRAINT event_store_messages_partitioned_pkey PRIMARY KEY (uuid, "time”);Now we’ll create the indexes:
CREATE INDEX index_event_store_messages_partitioned_on_parent_uuid
ON public.event_store_messages_partitioned USING btree(parent_uuid) INCLUDE (uuid) WHERE ( parent_uuid IS NOT NULL );
CREATE INDEX index_event_store_messages_partitioned_on_time
ON public.event_store_messages_partitioned USING btree("time");
CREATE INDEX index_event_store_messages_partitioned_on_kind_and_time
ON public.event_store_messages_partitioned USING btree(kind, "time") INCLUDE (uuid);And let’s repeat the process above to create the event_store_completions_partitioned table:
CREATE TABLE public.event_store_completions_partitioned
(
uuid uuid DEFAULT gen_random_uuid() NOT NULL,
message_uuid uuid NOT NULL,
handler character varying NOT NULL,
created_at timestamp WITHOUT TIME ZONE NOT NULL,
updated_at timestamp WITHOUT TIME ZONE NOT NULL,
"time" timestamp WITHOUT TIME ZONE NOT NULL
) PARTITION BY RANGE ("time");We should underline that we want to maintain data integrity, so to that end, we won’t get rid of foreign keys. But the foreign keys, in turn, must refer to some field with a unique constraint containing the partition key. Therefore, to create the desired foreign key for the event_store_completions and event_store_messages tables, we need to store the “time” partition key in the event_store_completions table.
ALTER TABLE public.event_store_completions_partitioned ADD CONSTRAINT event_store_completions_partitioned_pkey PRIMARY KEY (uuid, "time");
ALTER TABLE public.event_store_completions_partitioned
ADD CONSTRAINT fk_event_store_completions_partitioned_message_uuid FOREIGN KEY (message_uuid, "time")
REFERENCES public.event_store_messages(uuid, "time") ON UPDATE CASCADE ON DELETE CASCADE;And let’s create the indexes:
CREATE INDEX event_store_completions_p_handler_message_uuid_idx ON public.event_store_completions_partitioned USING btree(handler) INCLUDE (message_uuid);
CREATE UNIQUE INDEX idx_escp_on_message_uuid_time_and_handler ON public.event_store_completions_partitioned USING btree(message_uuid, handler, "time");The tables have been created! However, there is still more to do: before connecting our original tables, we need to change their primary keys. If we do this by just using a simple ADD PRIMARY KEY statement, then PostgreSQL will use the strongest lock possible—ACCESS EXCLUSIVE—likely ensuring that your application will stop functioning for an undesirable amount of time. We don’t want to allow this to happen, so we’ll use a different approach to change the primary key—we’ll prepare unique indexes beforehand, in a non-blocking way:
CREATE UNIQUE INDEX CONCURRENTLY event_store_messages_unique_idx
ON event_store_messages (uuid, "time");
CREATE UNIQUE INDEX CONCURRENTLY event_store_completions_unique_idx
ON event_store_completions (uuid, "time");Bonus: adding indexes to the partitioned tables
We cannot create an index concurrently for an entire partitioned table, but there is a solution: we can add an index concurrently for each partition. After doing this, we’ll add an index for the partitioned table with the ONLY flag. Finally, we’ll link the partition indexes with the indexes of the partitioned table by running the ATTACH PARTITION command for each partition index.
And with that, we’ve completed all the necessary preparations: let’s create a partition for real; old_event_store_messages will be our first:
ALTER TABLE public.event_store_messages
RENAME TO old_event_store_messages;
ALTER TABLE public.event_store_messages_partitioned
RENAME TO event_store_messages;
ALTER TABLE public.event_store_completions
DROP CONSTRAINT fk_event_store_completions_message_uuid;
ALTER TABLE public.old_event_store_messages
DROP CONSTRAINT event_store_messages_pkey;Since we have already created a unique index, we can easily create a primary key based on it in a matter of seconds! A table can have only one primary key, so we delete it first and then create a new one:
ALTER TABLE old_event_store_messages
ADD CONSTRAINT event_store_messages_pkey PRIMARY KEY USING INDEX event_store_messages_unique_idx;Everything is ready now, and we can simply attach old_event_store_messages to event_store_completions_partitioned.
Or can we?
There’s another nuance to consider here, and not paying mind to this one can cost you additional downtime: when we attach a partition with data, PostgreSQL checks if the data aligns with the section constraints. We can avoid this situation by creating a CHECK before the attachment with the NOT VALID option. This allows us to skip the data check. That being said, you should only do this if you are certain that your data is valid:
ALTER TABLE old_event_store_messages
ADD CONSTRAINT first_partition_integrity CHECK ( "time" BETWEEN ( '-infinity' ) AND ( DATE_TRUNC('week', CURRENT_DATE::timestamp) + '7 days'::interval )) NOT VALID;After attaching a partition, we won’t need this constraint anymore, so we can remove it:
ALTER TABLE event_store_messages
ATTACH PARTITION old_event_store_messages FOR VALUES FROM ('-infinity') TO (DATE_TRUNC('week', CURRENT_DATE::timestamp) + '7 days'::interval);
ALTER TABLE old_event_store_messages
DROP CONSTRAINT first_partition_integrity;We’ll run the same process for the second table:
ALTER TABLE public.event_store_completions
RENAME TO old_event_store_completions;
ALTER TABLE public.event_store_completions_partitioned
RENAME TO event_store_completions;
ALTER TABLE public.old_event_store_completions
DROP CONSTRAINT event_store_completions_pkey;
ALTER TABLE public.old_event_store_completions
ADD CONSTRAINT event_store_completions_pkey PRIMARY KEY USING INDEX event_store_completions_unique_idx;
ALTER TABLE public.old_event_store_completions
ADD CONSTRAINT first_partition_integrity CHECK ( "time" BETWEEN ( '-infinity' ) AND ( DATE_TRUNC('week', CURRENT_DATE::timestamp) + '7 days'::interval )) NOT VALID;
ALTER TABLE public.event_store_completions
ATTACH PARTITION public.old_event_store_completions FOR VALUES FROM ('-infinity') TO (DATE_TRUNC('week', CURRENT_DATE::timestamp) + '7 days'::interval);
ALTER TABLE public.old_event_store_completions
DROP CONSTRAINT first_partition_integrity;And… our table partition is complete. Hooray! 🥳
Bonus: how to create partitions
There’s no use in partitioning if we have only a single partition attached. But it’s often tiresome and dangerous (as a human being may simply forget about it) to create new partitions manually. So, we have to automate partition creation, and here are a couple of ways to do that:
- Using cron jobs. For example, if you partition by weeks (like we did here with event tables), then you can prepare partitions beforehand. Although this isn’t the safest option because if you somehow fail to create a new partition, all the SQL queries using it will fail.
- Using triggers. Here’s an example for the case when the table you want to partition has a
user_idfield which references anidfield of thepublic.userstable. In the code below, we create a new partition for every 1000 users.

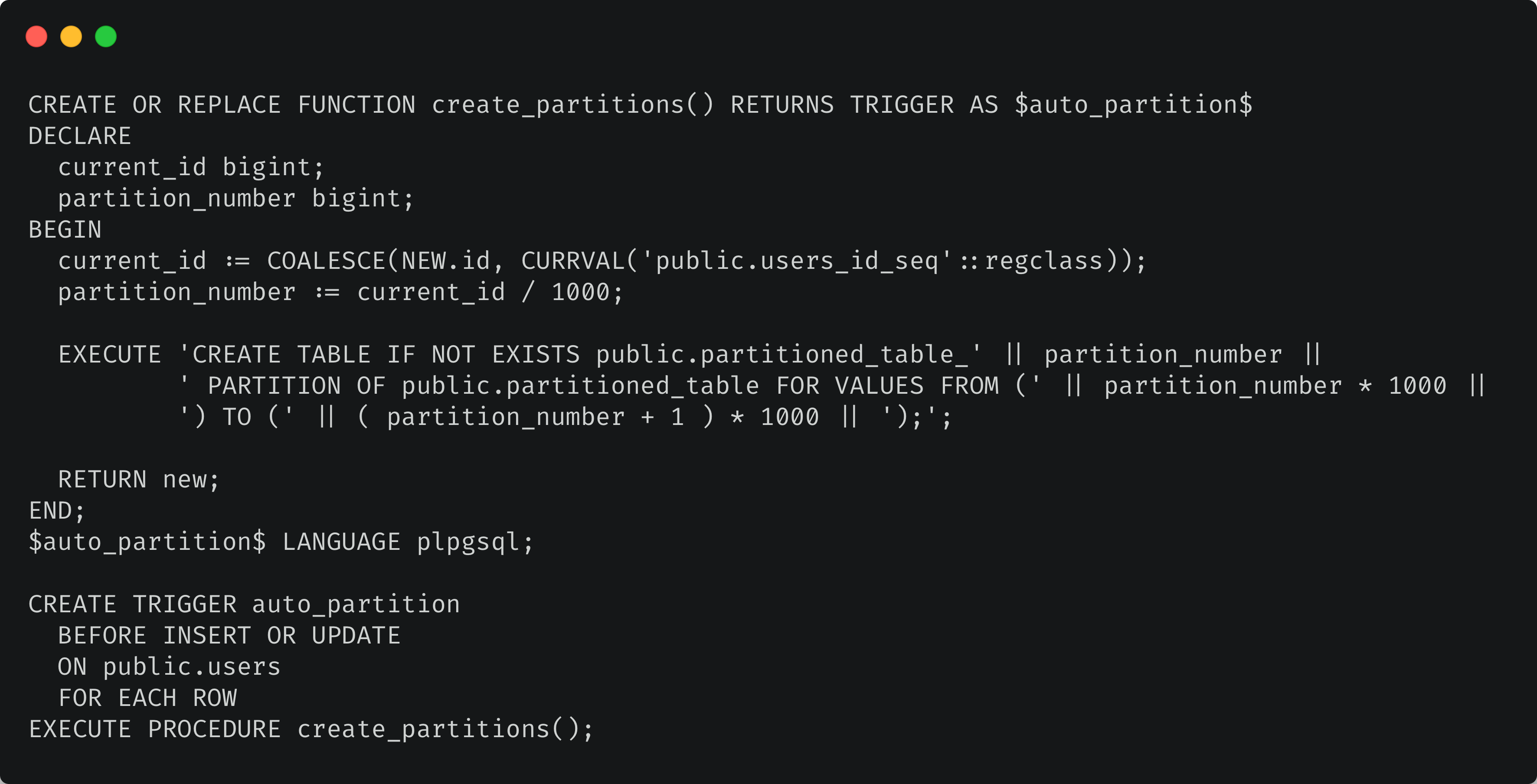
Examining some possible partitioning pitfalls
The partitioning process we described above is all very pretty in theory, but there’s almost always a need to take some additional steps when working in a real-life Rails scenario.
Pitfall #1: Rails itself
First of all, Rails cannot work with composite primary keys. But, nonetheless, you’ll need to use them, for two reasons:
A partitioned table already uses a composite primary key (which includes the partition key). Of course, you can still use queries without a partition key and write your SQL manually for UPDATE and some other things. But… there are also associations to deal with. Moreover, related tables are often partitioned; accordingly, you’ll need a convenient tool to work with them.
Luckily, we have some ready-made solutions: for instance, the composite_primary_keys gem. However, it’s best to keep in mind that this gem solves the problem of supporting composite primary keys for different ORMs. Therefore, in some cases, queries collected by the gem can be extremely complex (with many levels of nesting). Here, you’ll have to decide: will you sacrifice performance in favor of beautiful code, or will you avoid extra complexity by manually writing a portion of the SQL queries?
📝 Note: Some queries (as of gem version 12) may be invalid due to query nesting and sorting. For example, a construction like this…
scope = EventStore::Message.where("time > ?", 1.day.ago).order(:time)
scope.update_all("...")…will give us the following response (note the two ORDER BY clauses; the second one is obviously redundant):
UPDATE "event_store_messages" SET ... WHERE ("event_store_messages"."uuid", "event_store_messages"."time") IN (SELECT "event_store_messages"."uuid", "event_store_messages"."time" FROM "event_store_messages" WHERE (time > '2022-01-19 14:33:16.239683') ORDER BY "event_store_messages"."time" ASC) ORDER BY "event_store_messages"."time" ASCPitfall #2: locks
Ruby on Rails (still) accepts the partitioned table as a single table (and that’s great!), but we are dealing with several small ones. That’s OK when we have just a dozen or so of them, but what to do with a hundred, or even several hundreds of them? Houston, we have a problem. 🧑🚀
Imagine that you have one large table, and for instance, you run a simple query to select N records according to some conditions, and accordingly, PostgreSQL creates ACCESS SHARE locks in this table, and its sequences and indexes. But if you have 100 partitions and your query doesn’t specify the range of partitions that should be used, locks will be created for each of the partitions. In general terms, (N + 1) * M, where N is the number of partitions (don’t forget about the partitioned table!), and M is the number of entities in one table that PostgreSQL wants to lock. As a result, a query that typically takes 10 locks, in the case of 80 partitions, takes more than 800.
Let’s add transactions to this process. Suppose that we have a typical service that works with records in partitioned and related tables (and some of these may also be partitioned). Locks created during a transaction will not be released until the very end of the transaction—that is, until COMMIT/ROLLBACK. This means that if you have many similar transactional operations per unit of time, PostgreSQL will inevitably report: out of shared memory, and it will accompany this notification with an urgent request to increase max locks per transaction.
That is why, before partitioning, you must check all (literally all) queries to see if they use a partition key. Because even a harmless find_by_id can cost you downtime and result in fried nerves later on.
Here is an example solving the same challenge with queries on the fly (but after the implementation of partitioning):

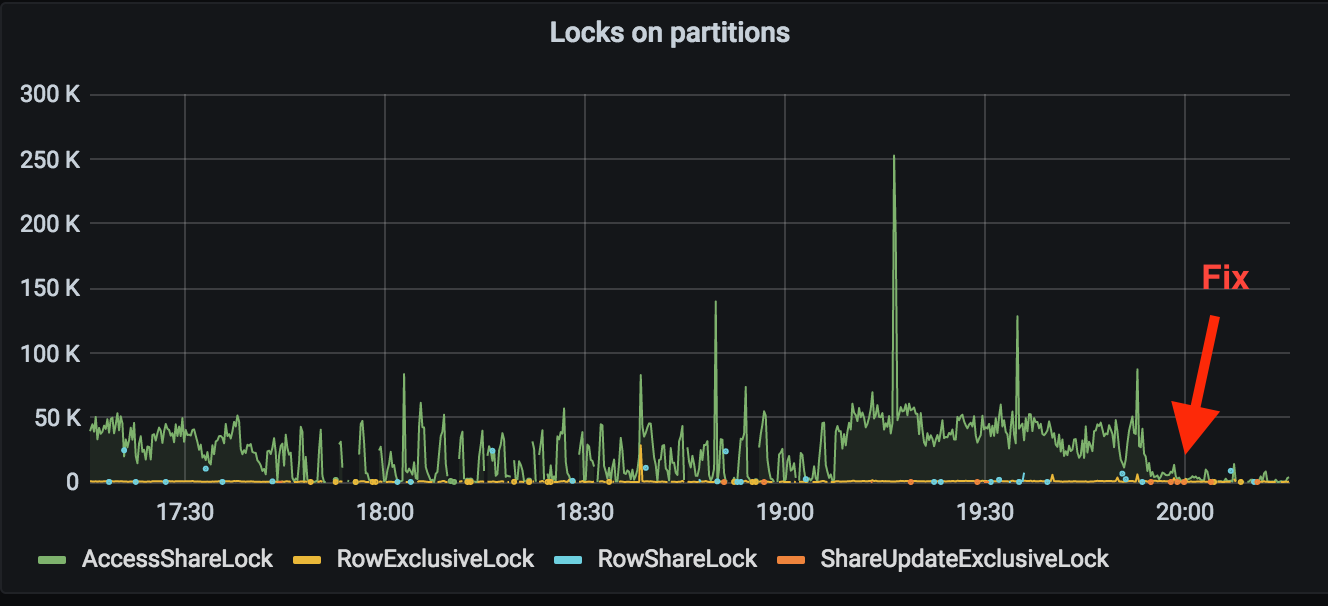
Pitfall #3: indexes
When you’re working with a huge amount of data (exactly the type of situation where you’d need partitioning), it is critical to understand that the indexes you create should speed up your work with the table, not slow everything down. For example, a primary key of the (time, uuid) type will decrease the efficiency of selecting events by uuid in a wide range of time (for one or two partitions):
Index Scan using event_store_messages_08112021_pkey on event_store_messages_08112021 (cost=0.43..38480.54 rows=1 width=337) (actual time=166.344..166.345 rows=0 loops=1)
Index Cond: (("time" > '2021-11-08 00:00:00'::timestamp without time zone) AND (uuid = '53400a2c-3654-411b-9247-288247406087'::uuid))
Planning Time: 0.549 ms
Execution Time: 166.366 ms
(4 rows)For comparison, let’s look at the same operation with (uuid, time):
Index Scan using event_store_messages_pkey on event_store_messages_08112021 (cost=0.43..2.65 rows=1 width=337) (actual time=0.008..0.008 rows=0 loops=1)
Index Cond: ((uuid = '53400a2c-3654-411b-9247-288247406087'::uuid) AND ("time" > '2021-11-08 00:00:00'::timestamp without time zone))
Planning Time: 0.425 ms
Execution Time: 0.017 ms
(4 rows)This may be a reasonable compromise if time samples are more critical for you; you can create an additional index for selections by uuid in this case. But, in any case, it will be helpful if you alway consider such nuances when planning a partitioning scheme.
The grand finale
Partitioning has become much more convenient for engineers. You can (and sometimes must) partition. For instance, in cases where the volume of data is hampering your work (or where it could complicate it in the future) and in cases when data can be easily divided into groups. But, still, despite the method’s simplicity, partitioning has a lot of nuances that can lead to the opposite intended effect, so be careful! Feel free to use this article for reference, and keep the documentation handy for when any questions might arise.

And, if you’ve got a problem on the backend, frontend—or beyond—Evil Martians are ready to help! We’ll detect it, analyze it, and to zap it out of existence! (Or, if you’re missing something, we’ll zap it in to existense!) Drop us a line!

