Big on Heroku: Scaling Fountain without losing a drop


For the past three years, we have been helping Fountain to grow from a Y Combinator graduate to a leading hiring solution for the flexible workforce—all while staying on Heroku for hosting and continuous delivery. We learned how to get the most out of a popular zero-ops platform and now we share our notes with you.
For many engineers, deploying a web application with git push heroku master is somewhat of a guilty pleasure. One might think that it is OK to use Heroku for taking pet projects and proofs-of-concept live, but once your product is ready for prime time, it is a job of a dedicated developer operations team to manage infrastructure: whether self-hosted or in the cloud. Deployment then becomes a sacred (and expensive) ritual, only accessible to the chosen few.
Meet Fountain, an industry leading hiring platform for hourly workers, used by Uber, Deliveroo, and Airbnb, among others. For Keith Ryu (Forbes’ “30 under 30”) and Jeremy Cai who co-founded the startup in 2015 under the name OnboardIQ and put it through the Y Combinator’s summer 2015 funding cycle, Heroku was an obvious choice.
Without the need to manage infrastructure, a small product team could focus all their energy into building features and attracting first customers to a live product.
Evil Martians’ mission was to turn the early version of OnboardIQ (now Fountain), bootstrapped by a co-founder Keith Ryu himself, into a stable platform with clean, performant and maintainable code that is ready to handle the ever-growing demand of modern sharing economy for hourly workers.
The pain that Fountain’s founders have discovered—an average 50% no-show rate of job applicants to interviews and the fact that many hired workers move on after their first month—needed remedy fast, and sticking with Heroku was a calculated bet that paid off. More than 300,000 hourly workers were hired and onboarded through Fountain’s software in the third quarter of 2018 alone, bringing the number of successful hires made through the platform over 1.6 million (with a total of 12.3 million job applications processed).
As a team who helped Fountain to see their Heroku-hosted application through all stages of growth, we are ready to share our observations on scaling a successful startup by relying on what is made available by a popular Platform as a Service and the ecosystem around it. Read on to see which obstacles to expect, and how to overcome them.
Keep your tabs early
A web application, once deployed, is a living, breathing organism. So the first thing you need to do while welcoming your first thousands of users—make sure that you always have your hand on the application’s pulse and you are ready to react to changing trends in your users’ behavior.
That means taking control of two things: application logs and runtime metrics.
Logs and metrics are not only the source of truth about the health of your systems but a powerful business instrument for analyzing user behavior and observing real-world trends to either confirm your predictions or form new ones. It is also the only way to understand the impact of new product features truly.
You will also need comprehensive logging and instrumentation to set up monitoring and alerting systems, crucial for reducing applicantion’s odd behaviour.
With Fountain, we outgrew Heroku’s built-in log system almost right away. Logplex, installed on any Heroku application by default, keeps only 1500 lines of consolidated logs and those expire after 1 week.
So, your first bet would be to opt for a more powerful logging solution, and luckily Heroku ecosystem offers a range of choices for that. We have settled on Logentries that provides a flexible query language and an ability to aggregate and visualize metrics extracted from the logs. You also get necessary alerting capabilities. If you install Logentries as a Heroku add-on, useful alert policies for Heroku’s platform-specific error codes are enabled out of the box so you will get notified on events like Request Timeout or Memory quota exceeded. Fountain generates gigabytes of logs per day in production and Logentries does not even stumble.
You might also improve on Heroku’s built-in metrics dashboard that tracks things like HTTP response times and memory usage, by opting for a Librato add-on. It also uses Heroku logs as a source for metrics but displays them in a more comprehensive way that is easier to explore. You can easily add custom alerts in your dashboard too.

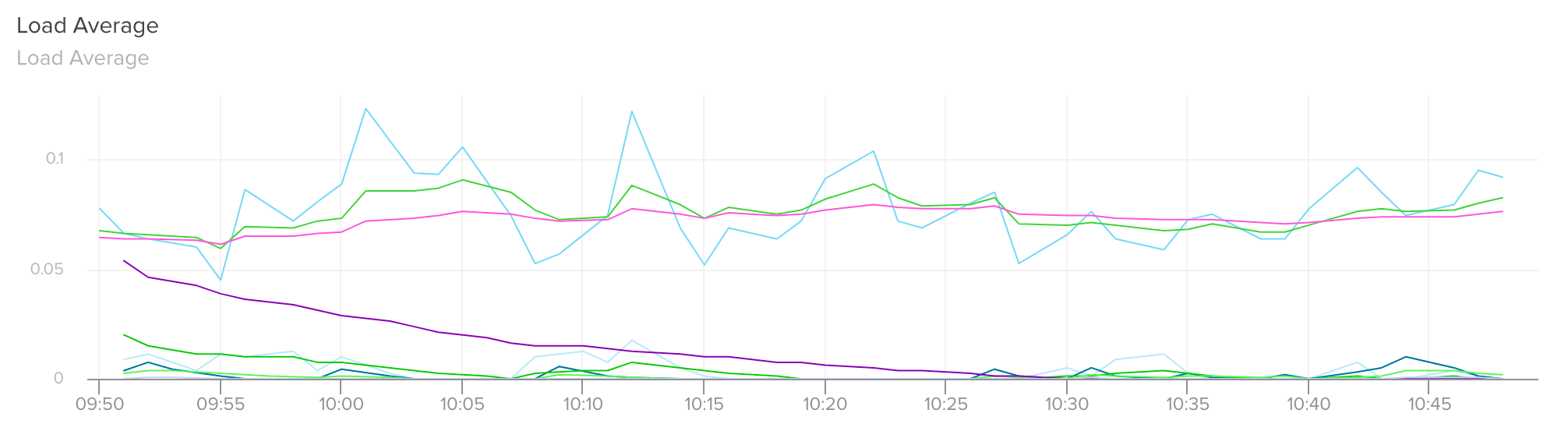
Load average graph presented with Librato
We have also gained valuable insights regarding Fountain’s application from Heroku’s built-in Language Runtime Metrics. This feature, still in public beta, allows you to track and make sense of language-specific parameters like heap objects count or garbage collections. We have used available metrics for Go and Ruby to find a room for finer performance optimizations.

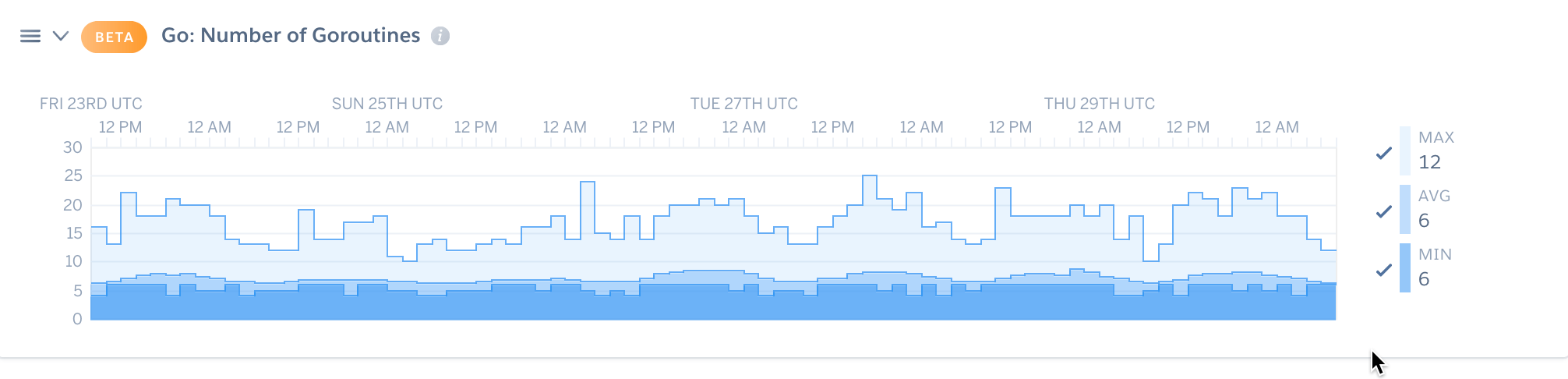
One of Language Runtime Metrics available: number of goroutines for Golang
For even more granular control over your runtime metrics, opt for New Relic—think of it as an intensive care unit for your code and keep in mind that it is priced accordingly. Fountain started out as a monolithic Rails application, and New Relic allows us to track everything from database queries and controller actions to Ruby VM internals and network accessibility. For a big mission-critical application New Relic is definitely worth its price.

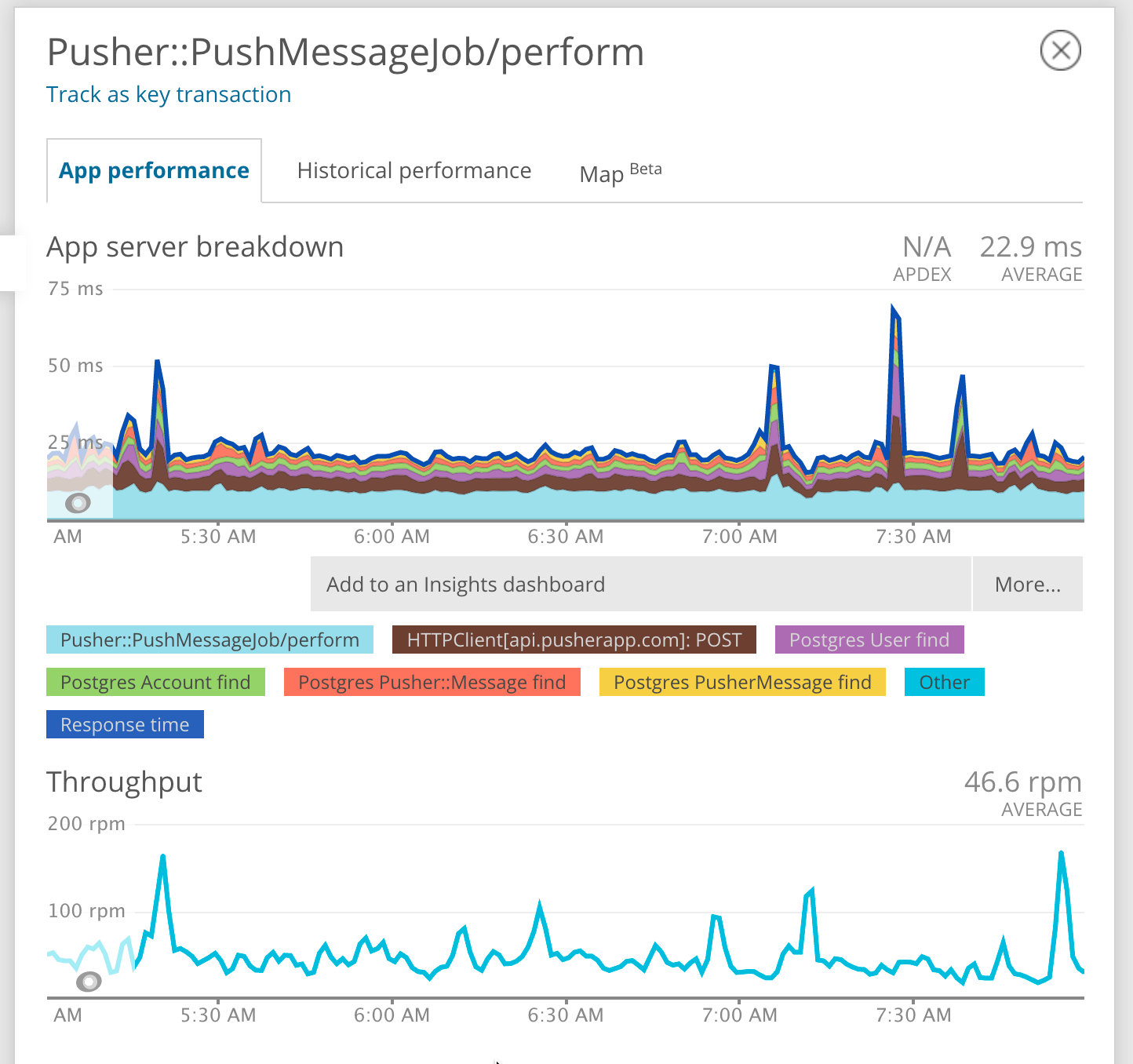
Sidekiq job performance breakdown in New Relic
Embrace the workflow
Using Git remote to push your application’s code to Heroku is just the tip of the iceberg: it makes sense to spend time studying all the possibilities that the platform has made available for continuous delivery with its Heroku Flow.
GitHub integration is the first thing you might want to take a look at if you plan to build your product on Heroku.
Frankly, you don’t need any third-party solutions for CD/CI, you can go all-in on tools built into the platform, and this is precisely what we did with Fountain.
-
Review apps. For every pull request you open in your project’s GitHub repository, Heroku can create a complete, disposable application. Those are perfect for performing quality assurance for newly added features. After enabling review apps in your Heroku dashboard, all you need to do is to keep your
app.jsonanddb/seeds.rbfiles up to date. No need to worry about costs: Heroku add-ons that your primary application relies on usually have free plans that should be more than enough for a QA process, just remember to get rid of the disposable app after you’re done. There is also a possibility to destroy review apps automatically after 5 days of inactivity or once PR is closed. -
Pipelines. Although historically not a part of the Fountain workflow, they allow pushing the convenience of review apps even further: after the PR is merged, Heroku can create a slug out of a master branch and deploy it to the staging application that has the same codebase as your production app. Once further testing is complete, you can promote the slug to production in just one click.
-
Heroku CI. A disposable test environment for your application closely resembles those used for staging and production: there is no need to set up everything from scratch in a third party CI service. It is also convenient to pay all your bills together. Since recently, you can also run your test in parallel across as many as 16 dynos (32 in private beta). When we started with Fountain, this feature was not yet available and it pushed us to find novel ways to speed up out tests suites. This is how TestProf profiling and optimization toolbox for RSpec and Minitest came to life and allowed to make our Ruby tests four times faster. It still makes sense to find bottlenecks in your large testing suites before opting for parallel test runs on Heroku, as it will allow you to save money on dyno usage (Performance-M dyno cost of $250/month, prorated to the second).
Optimize before scaling
You have set up the perfect workflow and the changes that your developers introduce make their way to production quickly and safely. Your logging, instrumentation, and alerting solutions are ready to report on anything out of the ordinary.
Naturally, as your application attracts more users, alerts start coming: time to finally handle the increased load.
No need to touch that dyno slider just yet—as a startup you are looking for ways to make the most out of the limited budget, not indulge in overspending at any sign of trouble.
First problems you are going to encounter will probably have to do with RAM usage. With any Rails application, Fountain not being an exception, memory bloat becomes an issue as you start handling more requests.
From our experience, fine-tuning Ruby’s garbage collector once you start experiencing speed issues almost never hurts and it is easily adjustable through environment variables. Here are the settings we usually use that take care of most of the small problems:
RUBY_GC_HEAP_GROWTH_FACTOR=1.10
RUBY_GC_MALLOC_LIMIT_GROWTH_FACTOR=1.10
MALLOC_ARENA_MAX=2Note that it is not a silver bullet and your mileage may vary. While investigating your memory problems, try first to determine if the bloat is experienced by the web process or any of the background workers.
As memory allocation is expensive, significant memory allocations take considerable time. If you track down bloat in your web process—scan your logs for slowest requests!
Once the slow request is located (the easiest way is to query your logs in Logentries advanced search mode for requests longer than expected, e.g., WHERE(service > 1000)), replay it, dissect in Newrelic Traces, then reproduce it in the local environment and start looking for a underlying issue. From our experience, more often than not a problem is tied to instantiating an excessive amount of Active Record objects.

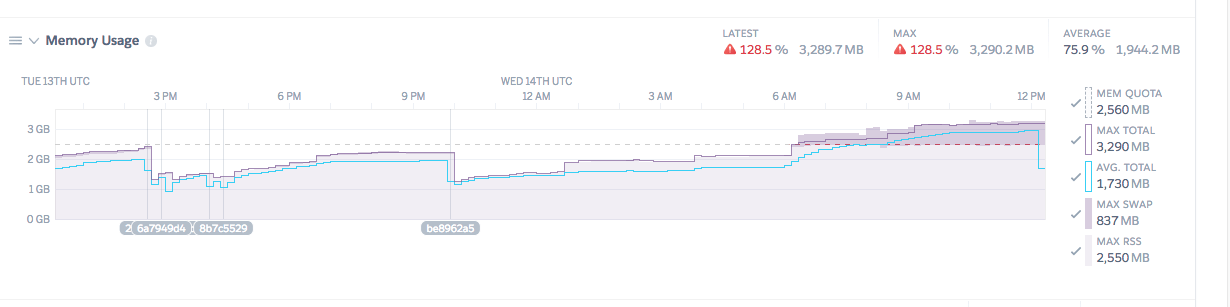
Typical memory consumption in a bloated application
Tracking down memory problems caused by background jobs is less straightforward: they take more time, use more resources, and run in parallel, which makes debugging harder. Running memory profilers in a production environment to gauge Sidekiq’s concurrent performance (at Fountain, we use Sidekiq heavily) will add even more overhead, so we usually resort to a divide-and-conquer solution.
Sidekiq is highly configurable, so you can easily split your job queues to be handled by two different processes by modifying your Procfile:
# Procfile
sidekiq: bundle exec sidekiq -C config/sidekiq.yml
sidekiq_secondary: bundle exec sidekiq -C config/sidekiq_secondary.ymlInside your YAML configuration files, don’t forget to give different queues to different processes. Then it is just a good old binary search that you have to execute manually: split your processes and queues in half until you find a culprit. Then you can split jobs inside the guilty queue as you close down on the source of the problem.
Using multiple Sidekiq instances is also a good practice if you want to isolate resource-hungry jobs (imports, exports, file processing) right away.
Scale smart
Even with all optimizations in place, sooner or later you are going to hit the hardware limitations of your dynos, and you will have to scale. Heroku makes it as easy as dragging a slider in a dashboard, but then your bill will increase accordingly.
Before scaling, always make sure that your application server is configured correctly. The best available resource for that is “Configuring Puma, Unicorn and Passenger for Maximum Efficiency” by Nate Berkopec, an expert in Rails performance.
Then get ready to increase your spending budget by choosing more performant dynos with better memory or CPU characteristics.
If you notice request queuing, scale horizontally. Observe patterns in your weekly load: often you don’t need extra resources constantly available, but only at certain times during working days.

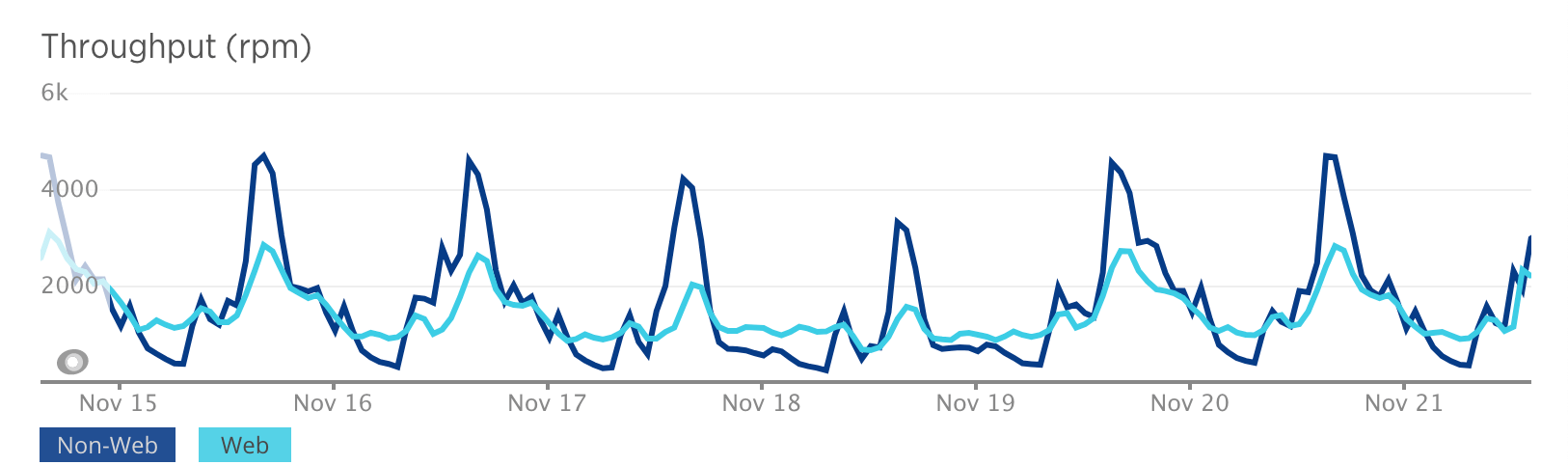
Spikes in requests throughput correlate with working days and hours
Implementing on-demand performance increase on Heroku is a no-brainer with their Autoscaling feature. Note, however, that it only works for web dynos.
Autoscaling background workers is also possible: you can observe the state of your queues from a script and send automated requests to the platform’s Formation API to adjust the number of
worker processes or dyno sizes. You can schedule it to run periodically with a clock process.
dyno_count = calculate_dyno_count(sidekiq_queues_size)
# updates via
# PATCH https://api.heroku.com/apps/{app_id_or_name}/formation/{formation_id_or_type}
update_formation(
app: 'fountain',
formation: 'sidekiq',
quantity: dyno_count
)Mind your data
When it comes to primary data storage, PostgreSQL is our weapon of choice at Evil Martians, and, luckily, Heroku supports the world’s most advanced open source database naturally.
For Fountain, we went with a standard Heroku managed Postgres. It is provided out of the box once you push a Rails/Postgres application to the platform and offers both encryption and continuous protection.
Besides the ability to schedule regular backups, you also get a rollback functionality that allows restoring the state of your database to any point in time in the last four days to a week, depending on the account plan. Also, rollback does not affect the primary database, but provisions a new database, that can be easily promoted to primary.
Lost or corrupted data is no longer a catastrophe for your engineering team.
Another Postgres-related Heroku feature we use at Fountain is Follower Databases. It comes out of the box and allows you to create a read-only copy of your primary database that stays up-to-date with the data. This takes the heat off the production database when you are ready to perform heavy read operations: either when ingesting into a data warehouse or performing complex analytics.
Having a database in the cloud also means you do not have full control over the hardware it is installed on. In reality, Heroku provisions Postgres databases from Amazon EC2. To understand the health of your database hardware you have to rely on built-in metrics that Heroku writes directly to application logs in the following format (line breaks added for clarity):
2013-05-07T17:41:06+00:00
source=HEROKU_POSTGRESQL_VIOLET
addon=postgres-metric-68904
sample#current_transaction=1873
sample#db_size=26219348792bytes
sample#tables=13
sample#active-connections=92
sample#waiting-connections=1
sample#index-cache-hit-rate=0.99723
sample#table-cache-hit-rate=0.99118
sample#load-avg-1m=1.42
sample#load-avg-5m=1.45
sample#load-avg-15m=1.34
sample#read-iops=0
sample#write-iops=2.875
sample#memory-total=1692568kB
sample#memory-free=73876kB
sample#memory-cached=1344128kB
sample#memory-postgres=22388kBWith the help of Librato’s Heroku add-on, you can present all that information nicely on a dashboard and set up alerts for desired thresholds.

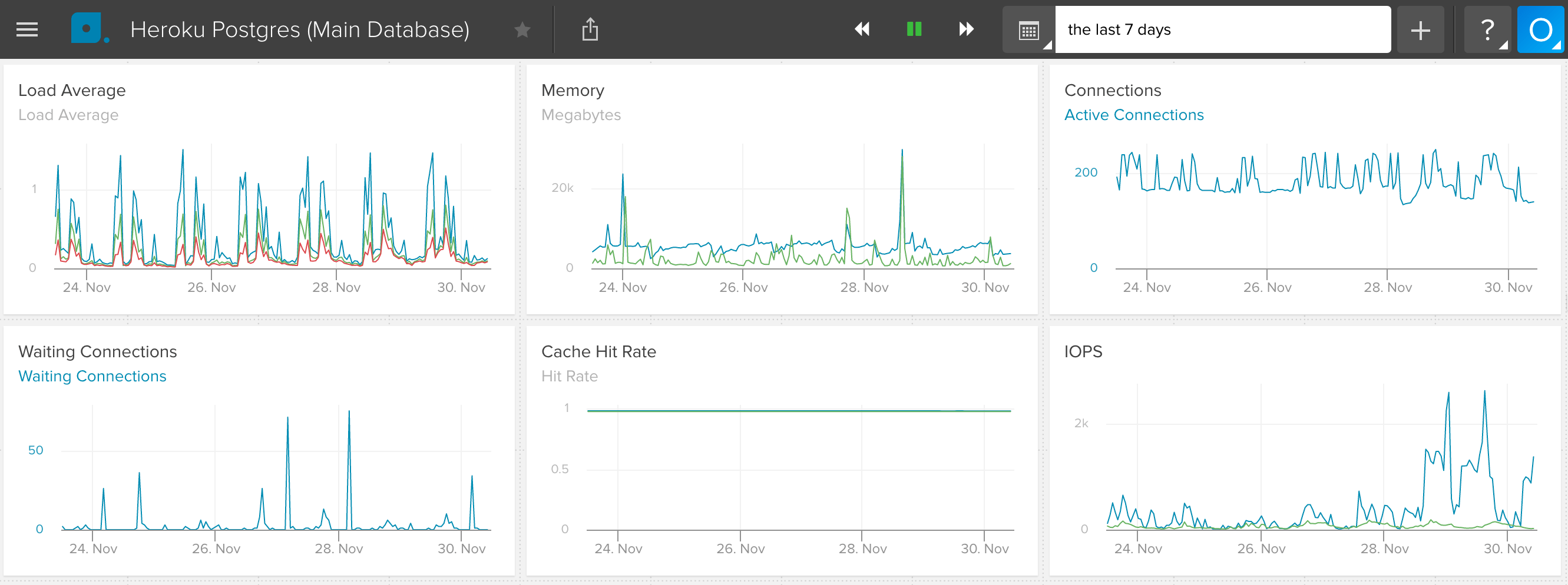
PostgreSQL metrics displayed in Librato dashboard
Besides obvious metrics like load averages or memory usage, we strongly suggest keeping a close eye on index-cache-hit-rate parameter. When it’s significantly lower than 1 on your production system, it means queries resort to slow sequential scans instead of using an index.
All SQL statements that take longer than 2 seconds will be additionally logged by Heroku, so it is easy to identify them, run EXPLAIN and add indexes to tables, if necessary.
Consider adding a heroku-pg-extras CLI plugin that allows you to monitor your database health from the console with handy snippets that allow you to glance at important statistics like index sizes, vacuum details or table bloat:
$ heroku pg:table-indexes-size
table | indexes_size
learning_coaches | 153 MB
states | 125 MB
charities_customers | 93 MB
charities | 16 MB
grade_levels | 11 MBFor write-heavy operations, you should also mind the number of PIOPs in order not to hit the hardware limitations of underlying disk storage. You can think of this characteristic as regular IOPS but in the context of Heroku. You can find out how many input/output operations per second your current Postgres production-tier plan supports here, and upgrade if necessary.
Also, feel free to experiment with databases alternative to Postgres to solve more specific problems. At Fountain, we are using Elasticsearch for our Analytics Dashboard feature. There are at least three Heroku add-ons from different vendors that can enable Elasticsearch for your application and we opted for Elastic Cloud, developed by Elastic themselves.
With time, we found more interesting use cases for Elastic: for one, it allows us to perform fast counts of database records. Postgres’ COUNT tends to become super slow on big tables since it almost always uses sequential scan, so delegating this job to Elasticsearch saves you a lot of time if you can deal with a couple of second of lag in your indicators.
Whenever you are using third-party solutions, take time to isolate their usage in your code so that your application does not fall victim to outages for which Heroku cannot be held responsible. The simplest safeguard for our Elastic fast-count functionality would look something like that:
def my_super_fast_counter
calculate_with_elastic
rescue ElasticsearchException => e
notify_honeybadger(e)
0
endDive into the ecosystem
Here are some other features of Heroku platform that we found extremely useful. They are very platform-specific, and if you want to implement something similar in another cloud or hardware, your approach will be different. Once you are already on Heroku, why don’t give them a try?
Multiple add-on instances
A great thing about the universe of Heroku add-ons is that with the most of them you can attach as many instances to your application as you want. Your add-ons can be completely independent of each other and have different settings.
At Fountain, we use multiple instances of Heroku Redis with one instance used entirely for caching purposes (it has more memory and implements LRU eviction policy), while another one is used only for Sidekiq queues with no eviction policy in place to guarantee that no data is ever lost.
Zero-time deployments with Preboot
Preboot is a feature that allows you to enjoy the so-called “blue-green” deployment process. It makes sure that the new web dynos are started before the existing ones are terminated, allowing you to have a zero-downtime deployment.
However, you should be careful with this approach as it allows for a short window where requests coming to an application are treated with both the old and the new code, leading to inconsistent behavior. In our case, it led to a situation where old dynos failed to return assets requested from the new code, and the CDN had cached the 404 response.
Heroku support is well aware of those kinds of issues, and one possible fix is to use a Session Affinity feature that makes sure that requests from the same client always come to the same dyno. It has it’s own downsides though, leading to sometimes unpredictable routing behavior.
The best way to avoid assets problem is to upload them directly to S3 or CDN. With that, you can always be sure that you have all versions of assets, including previous releases. There are libraries like asset_sync for Sprockets and webpack-s3-plugin for Webpack which do this job for you automatically right after your assets are compiled. Alternatively, you can upload your assets manually during the Heroku release phase: after the slug is compiled but before the launch.
SSL management
Heroku can save you a headache of managing SSL certificates. With a couple of clicks or a few CLI commands you can enable Automated Certificate Management that uses Let’s Encrypt under the hood and forget about manually renewing your certificates once and for all.
If for some reason, you need to deal with custom certificates from certain authorities, that is also possible. Read our blog post about domain migration with Heroku for SSL management details.
Microservices
With Heroku, you are not tied to Ruby and Rails. Thanks to multi-language support, you are free to experiment with microservices written in Node.js, Golang, Elixir or any other language.
Just deploy a separate application and choose a suitable dyno plan depending on the load. With the recently implemented Docker support, the process became even easier: you can develop and test your containers locally and then simply push them to the cloud.
For Fountain, we were able to separately host such an extravagant solution as Nginx with embedded mruby to add some custom headers to requests: it allowed us to lower memory consumption in the main application and achieve higher durability.
Buildpacks
Don’t be intimidated by the notion of buildpacks. After all, it is just a number of scripts that configure your slug in a certain way: by adding binary dependencies missing from default environment or enabling a multi-language runtime.
You can find open source buildpacks readily available at GitHub or roll your own. At Fountain, we’ve created one to add pdftk binary support for working with PDFs. Buildpack for the Node.js support to build your frontend with Webpack is another obvious choice.
With buildpacks, you can also invoke custom scripts during the build process. For Fountain, we attached a Slack webhook that notifies the team when a new deploy starts. For that, we used a simple shell script that invokes curl through heroku-buildpack-shell.
Even though buildpacks are a powerful tool, today it perhaps makes more sense to gradually migrate to Docker containers, as Heroku now supports them out of the box.
Brace for things you cannot control
Heroku makes your life easier in many regards, but you also need to embrace the fact that you have no control over the underlying hardware. Prepare to get in touch with Heroku’s support team in case of emergency.
In our three years with Fountain, we only had a single problem that we were not able to resolve entirely by ourselves, and it was a puzzling one. To meet the growing demand from our users, we have upgraded the primary database to an upper plan. We did it well in advance, and our current plan still had enough capacity. Imagine our surprise when the performance took a hit after the upgrade.
Our engineering team went into “all hands on deck” mode in an attempt to troubleshoot a problem, but nothing made sense. Turns out, our database before an upgrade was hosted on a legacy infrastructure where isolation problems allowed us to burst the limits and achieve better performance for free, so the new plan turned out to be actually less performant than the old one. We had to upgrade to an even better plan and then we were able to meet our requirements finally. These kinds of problems are impossible to figure out without relying on the platform’s support team.
Another limitation of the Heroku platform is a stateless nature of dynos and their ephemeral filesystem. That makes working with files coming from the users especially tricky, as you always need to rely on direct upload to separate cloud storage that guarantees persistence.
Direct upload for user-generated assets is, however, a generally good idea, Heroku or not, as it shifts the burden of dealing with files from a server to each individual client.
For more complex file processing pipelines you need to invent more complex workarounds, as on Heroku you don’t have a filesystem to rely on.
Everything on Heroku serves one purpose and one purpose only: hosting a web application.
If you ever need anything other than HTTP, your life becomes harder. For instance, you cannot choose GRPC as a means of communication for your microservices. Unfortunately, Heroku still does not support HTTP/2. You are stuck with good old REST APIs to communicate between services (in this case you would use several separate Heroku instances), or you can an use asynchronous communication pattern using an event-driven approach and background processes (single instance with add-ons).

Today, nearly one million applicants per month are sourced, screened, hired and onboarded through Fountain’s software. Sticking with Heroku for hosting allowed us to grow naturally, without having to change our deployment stack midstream.
As our application expanded in the past three years, Heroku evolved too: now we are able to perform Docker deploys and run our test suite in parallel—features not available at the time we started out. We recommend subscribing to Heroku Blog to be notified of new features as they arrive: this way you can opt for beta-testing and get the upper hand even before the improvement becomes officially available.
Tight integration between Heroku and GitHub allowed us to deliver new features continuously and test them out thoroughly before deploying to the production environment. The universe of add-ons allowed us to experiment with new functionality in a plug-and-play fashion and keep our hand on the applications pulse with flexible monitoring solutions.
If you care enough about the code quality and instrumentation and optimize early to save money on hardware scaling, none of the inherent limitations of Platform as a Service should hold your startup back.