How to make complex serverless file processing a piece of cake


Topics

Translations
- Japanese複雑なファイル処理をサーバーレスでシンプルにする方法
Complex file processing can be made easy with serverless solutions, but when it comes to performing various manipulations on the uploaded files, you also need a robust system that’s easy to integrate. Yet, if you want to create a complex service, you’ll need to know some file processing tools and techniques. To illustrate, we’ll look at Playbook, a platform that handles tons of files every day, and, as a bonus, you’ll see an example serverless app for Google Cloud Platform with a small framework for asynchronous file processing and storing of the results.
What is complex file processing?
Let’s explain complex file processing with an example: Ben opens his favorite browser and navigates to your site, a web app for sharing photos. He uploads a picture of his dog and sees a small thumbnail, GPS location, the image dimensions, and an AI-generated description of the picture.
In essence, this is file processing in action: this can be straightforward, like showing EXIF info and file size, or it can be something more sophisticated, with image recognition, scaling, color adjustment, and many other AI-inspired operations that can stretch beyond the imagination.
However, for those seeking to build a complex service like that, you’ll need to have some file processing tools and techniques in your toolkit.
Additionally, you’ll want your users to be happy and you’ll want them to stay happy, too. This is possible when a solution is fast, cheap, and extensible, so it’s worth it to thoroughly think out the infrastructure.
It’s very important to make file processing fast and stable if you’re planning to sell it as one of the main features of your application.
It’s possible to build a unique system based on modern technologies (like the NoSQL database, retriable queues, and asynchronous code execution) and there are a lot of solutions for every task, you just have to connect them in one app.
Serverless functions to the rescue!
These functions encapsulate different APIs and technologies within a common interface, and this approach makes development faster and prevents obvious mistakes that would otherwise cause frustration when trying to connect a bunch of services within an app.
Serverless selling points
Let’s talk about the good stuff first: with a serverless solution, the actual code of your app can be simpler since you don’t need to worry about all the peripheral logic like authentication, authorization, or server auto-scaling. Instead, you can just focus on what matters for a particular function; you write the function code and tell the serverless provider when and how to execute it.
Naturally, you also don’t need to pay for server wait time because you’re not implementing a server. Instead, you only need to pay for the resources allocated when your code actually runs.
This approach can be cheaper because, unlike a dedicated server solution, it completely depends on usage.
Further, it’s easy to fit a serverless solution into a provider’s pre-existing infrastructure: for example, you can receive events in AWS Lambda from AWS S3. AWS Lambda will call your functions directly after a file has been uploaded to your S3 storage. In other words, you don’t need to care about delivery because the cloud provider takes care of it for you.
Extending and improving Playbook’s file processing service
Some background: Playbook works with uploaded files and performs various processing, including AI-based image recognition, metadata parsing, file conversion, and thumbnail generation.
Evil Martians helped the Playbook team extend and improve their existing file processing service, and we’re ready to share some of the knowledge we gained during this process.
The file processing system is deployed as a serverless application that runs on Google Cloud Platform (GCP).
Every file upload triggers a processing flow that does some magic with the files and stores the results. Later, these results are fetched and used in the application.

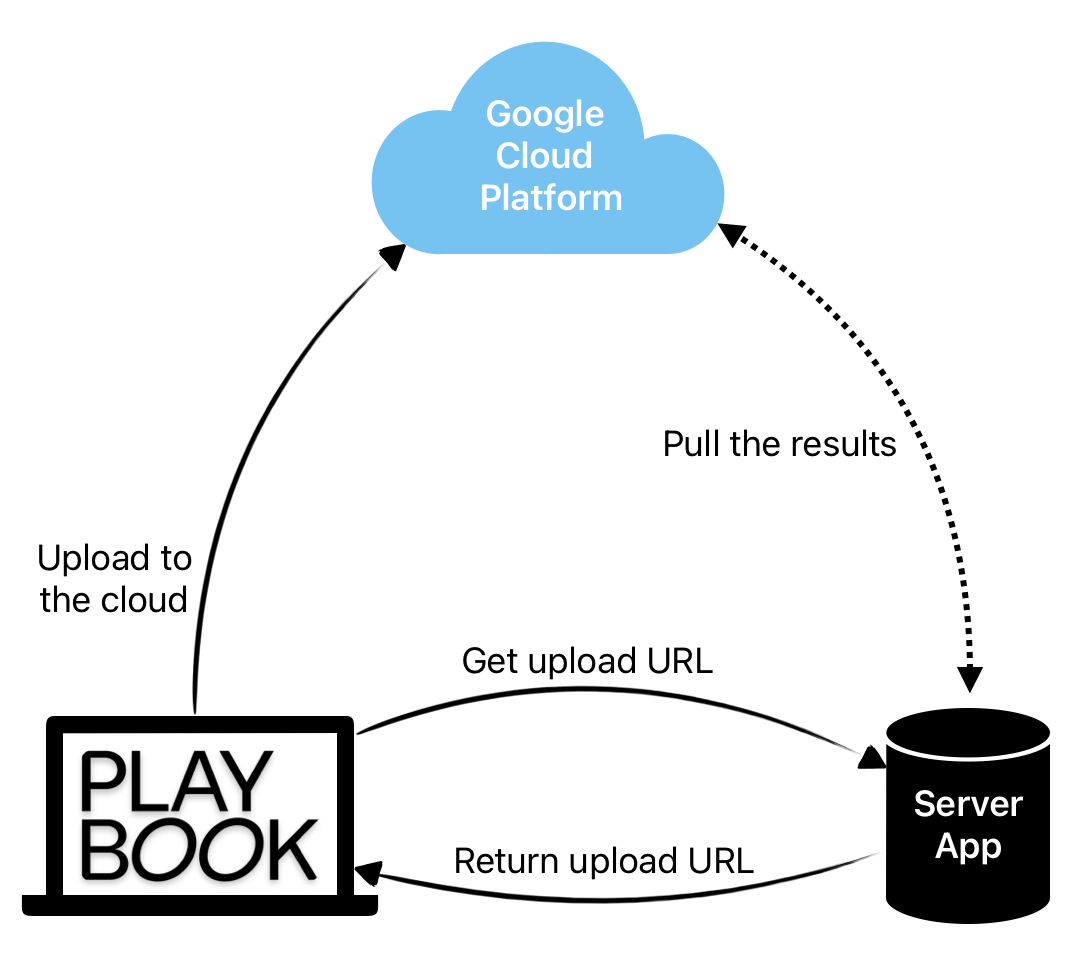
Here’s the flow:
- The client requests that the web server generate and sign a unique GCS upload URL.
- The client performs a sequential upload to GCS.
- The cloud functions process the file.
- A scheduled worker fetches the processing results from GCP.
To facilitate this, a small framework was built on the GCP services which provides a convenient and scalable file processing solution; each file upload triggers the processing pipeline.

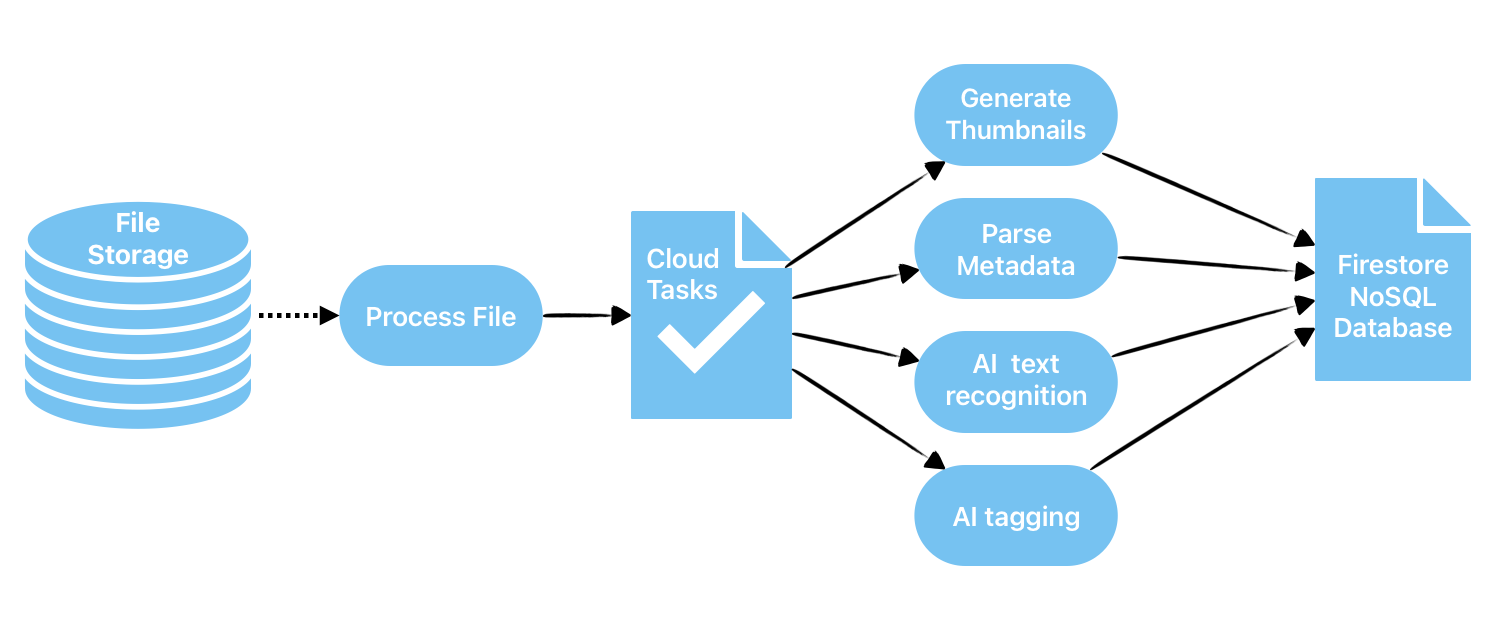
Here’s how this works:
- The cloud function is triggered with every uploaded file and creates a task in the Cloud Tasks service for asynchronous processing.
- The Cloud Tasks service calls the processing functions. If an unexpected error occurs, Cloud Tasks retries the function call.
- Cloud Functions performs text recognition, tag generation, thumbnail generation, NSFW detection, and numerous other tasks.
- Each function either triggers another in the pipeline or writes the processing results to the Cloud Firestore, which is a NoSQL cloud database.
Once the processing has finished, it’s time to handle the results: the main application runs a Sidekiq worker that fetches the results via a cloud function call, queues up the Sidekiq worker that handles the results, and clears the processed results with one more cloud function call.
If some functions haven’t yet processed the file, their results will be fetched on the next worker run. Each processing result is independent and complete, so it’s already safe to handle and clean it.
Conducting file processing in Cloud Functions helped Playbook save resources from the main application and delegate processing resources management and scaling to GCP.
This division also allowed them to encapsulate the processing logic and reduce the binding between the application and the file processing system.
Now, the code
In our example, a small serverless application, we’ll write two functions: one that handles newly created assets on storage and another that processess them. If you want to look at the complete example repository you can find it here: github.com/mrexox/serverless-file-processing-example
For the processing, we’ll write a small framework that utilizes the Google Cloud Tasks API and Firestore database for running the processing jobs and storing the results. This will make our solution scalable, so we could call asynchronously lots of processing functions.
Setup
We need to enable the APIs that we’ll use in GCP. So, in a blank project we’ll do the following in the Google Cloud Console:
- Create a Storage bucket; this will store the uploaded files.
- Enable Cloud Functions API; this is one of the main APIs we will use.
- Enable Cloud Tasks API; this API will be used in our asynchronous framework for triggering processing functions.
- Enable Cloud Deployment Manager API; this API is used for the code deployment.
- Generate a JSON key for our main service account; these credentials are required for the deploy. This setting lives in IAM & Admin -> Service Accounts.
If something fails deployment later, it can probably be easily fixed by granting the correct permissions or enabling extra APIs.
Configuration
Let’s configure the serverless framework for use with GCP and TypeScript.
We’ll store secrets in .env file for convenience and security.
Google Cloud Functions only know NodeJS runtime, so we will have to use a special plugin serverless-plugin-typescript for converting the code into JavaScript.
# serverless.yml
service: file-processing
useDotenv: true
frameworkVersion: "3"
plugins:
- serverless-google-cloudfunctions
- serverless-plugin-typescript
provider:
name: google
runtime: nodejs18
region: us-central1
project: my-project-0172635 # your real project ID
credentials: ${env:GCLOUD_CREDENTIALS}
environment:
BUCKET: ${env:BUCKET}
FIRESTORE_DATABASE: ${env:FIRESTORE_DATABASE}
GCLOUD_SERVICE_ACCOUNT_EMAIL: ${env:GCLOUD_SERVICE_ACCOUNT_EMAIL}
GCLOUD_TASKS_QUEUE: ${env:GCLOUD_TASKS_QUEUE}
PROJECT_ID: ${self:provider.project}
REGION: ${self:provider.region}
STAGE: ${opt:stage}
functions:
# Event-triggered function.
# Function is triggered when the file uploads successfully.
process_file:
handler: processFile
events:
- event:
eventType: google.storage.object.finalize
resource: projects/${self:provider.project}/buckets/${env:BUCKET}
# HTTP request-triggered function.
# Function is triggered from the Google Tasks.
parse_metadata:
handler: parseMetadata
events:
- http: parse_metadataCloud functions
We’ll now implement two cloud functions: the processFile function will start the processing flow and parseMetadata function will do the processing:
// src/processFile.ts
import enqueue from './lib/enqueue';
interface EventFunction {
(data: Record<string, any>, context: any, callback: Function): Promise<void>;
}
export const processFile: EventFunction =
async (data: Record<string, any>, _context: any, callback: Function) => {
const { name } = data;
// Does the asynchronous call to parse_metadata function
await enqueue('parse_metadata', { name });
callback(); // success
};For the parseMetadata function, we’ll assume that there can be many different processing steps, so we can run some processes in parallel, and then enqueue a different cloud function for further processing based on our results.
But for our small example let’s add just one simple processing step, parsing file metadata:
// src/parseMetadata.ts
import { Request, Response } from 'express'; // used here only for types
import * as processors from './processors';
interface HttpFunction {
(request: Request, response: Response): Promise<void>;
}
export const parseMetadata: HttpFunction =
async (request, response) => {
const { name } = request.body;
// Runs the processors in parallel
const result = await processors.call({
name,
processors: [processors.metadataParser],
tag: 'metadata',
});
response.status(200).send(result);
return Promise.resolve();
};The framework
We’ll build a small framework to allow our functions to be called asynchronously and to store their results somewhere.
With this framework, we’ll be able to create any pipeline because it will support both piped and parallel flows.
The piped flow is implemented by enqueueing a call to a cloud function from another cloud function.
The parallel flow uses Promise to grab the results from async functions that run concurrently.
The enqueue function uses Cloud Tasks API to do an asynchronous call to the Cloud Functions. It handles uncatched exceptions and retries the call in this case. This helps with accidental issues not related to the code (for instance, any uncaught network issues if we call other servicess from a cloud function).
// src/lib/enqueue.ts
import { CloudTasksClient } from '@google-cloud/tasks';
const client = new CloudTasksClient();
// ... CLOUD_FUNCTIONS_URL, QUEUE, GCLOUD_SERVICE_ACCOUNT_EMAIL definitions
export default function enqueue(functionName: string, args: any) {
const url = CLOUD_FUNCTIONS_URL + functionName;
const message = {
httpRequest: {
httpMethod: 1, // "POST"
url,
oidcToken: {
serviceAccountEmail: GCLOUD_SERVICE_ACCOUNT_EMAIL,
},
headers: {
'Content-Type': 'application/json',
},
body: Buffer.from(JSON.stringify(args)).toString('base64'),
},
};
return client.createTask({ parent: QUEUE, task: message });
}The processors.call function runs all steps in parallel using promises, then stores the results to Firestore database; these results can potentially be used to enqueue another cloud function.
import { Firestore } from '@google-cloud/firestore';
// FIRESTORE_COLLECTION and STAGE definitions
const firestore = new Firestore({
projectId: PROJECT_ID,
timestampsInSnapshots: true,
ignoreUndefinedProperties: true,
});
const collection = firestore.collection(FIRESTORE_COLLECTION);
export interface ProcessorFunc {
(file: StorageFile): Promise<any>;
}
interface ProcessorOptions {
name: string;
processors: Array<ProcessorFunc>;
tag: string;
}
export async function call({ name, processors, tag }: ProcessorOptions): Promise<any> {
const file = await getGCSFile(name);
let attributes: any = {};
await Promise.all(
processors.map(async (process) => {
const result = await process(file);
attributes = {
...attributes,
...result,
};
})
);
if (Object.keys(attributes).length === 0) {
return {};
}
const res = await collection.add({
tag,
name,
createdAt: Date.now(),
environment: STAGE,
attributes,
});
return attributes;
}For the sake of simplicity, I’ve omitted the code for getGCSFile. You can go to the sources if you want to check the implementation.
The stored results can be fetched later and used in the app. A scheduled Sidekiq worker can be used for this task. This approach allows to fetch the results in a batch and control the load to the database.
The parsing is done by metadataParser function. It uses sharp package to get the metadata from a file assuming it is a media file.
import * as path from 'path';
import * as fs from 'fs';
import sharp from 'sharp';
interface Metadata {
width?: number | string;
height?: number | string;
format?: string;
channels?: number | string;
hasAlpha?: boolean;
orientation?: number;
}
export const metadataParser: ProcessorFunc = async function (file): Promise<Metadata> {
// Destination path without nesting.
const destination = `/tmp/${path.parse(file.name).base}`;
try {
await file.download({ destination });
const { width, height, format, channels, hasAlpha, orientation } =
await sharp(destination).metadata();
return {
width,
height,
format,
channels,
hasAlpha,
orientation,
};
} catch (e) {
console.error('Error working with file', e.message);
return {};
} finally {
if (fs.existsSync(destination)) {
fs.unlinkSync(destination);
}
}
};This is a simplified example of how file processing can be organized using serverless and Google Cloud Platform. The basic idea here is the processing framework: it’s scalable and capable of supporting quite sophisticated processing flows.
The results
A few moments after uploading the file through the Google Cloud Storage web interface, I see the following record in the Firestore database.
Live file processing demonstration
I can fetch it later and delete as soon as my application handles the results. See the functions for fetching and deleting processed results in the example app on Github.

At Evil Martians, we transform growth-stage startups into unicorns, build developer tools, and create open source products. If you’re ready to engage warp drive, give us a shout!