Logidze 1.0: Active Record, Postgres, Rails, and time travel


Translations
Logidze is a Ruby library to track Active Record changes: whenever a record is updated in the underlying PostgreSQL database, Logidze stores the difference between the old and the new state, allowing you to time travel to any point in the record’s past. It is the fastest gem for auditing models in the Rails ecosystem, has been around for five years, and has just matured to 1.0, becoming even easier to use!
What do Georgian lemonades, Rails, and time travel have in common? For one, there’s Logidze! A library that I created in 2016 has just entered its adulthood with the first major version. In this post, I will highlight its major feature and share a story from our work on a mature commercial product for our customer, as it demonstrates a perfect use case for Logidze. Deal?
From a Rails developer perspective, using Logidze is as simple as installing the gem, running a couple of generators, and adding a single line to your model:
class Post < ApplicationRecord
has_logidze
end
post = Post.find(id)
yesterday_post = post.at(time: 1.day.ago)Under the hood, Logidze is based on just two ideas:
- Use database triggers to track changes. No Active Record callbacks (can be confusing and hard to maintain), Ruby or Rails code (not too fast), just plain old PostgreSQL triggers (fast and robust). MySQL is not supported yet, but it’s a matter of one solid PR.
- Keep the changelog next to the record data (in a
log_dataPostgres’ JSONB column).
If you want to know how this approach compares in speed to other popular Ruby gems like PaperTrail and Audited, check out my post where I introduce Logidze to the world back in 2016.
I’ve been developing Logidze for almost half a decade, but only recently I was able to “dogfood” it properly inside a large Rails codebase. It helped me discover and cut all the rough edges, so keep reading to see what changed.
Contents
Logidze 1.0: From structure to schema
The main feature of the latest release is the support for a default Rails way to store a database schema: the schema.rb. In the past, Logidze could only work with an SQL format for schemas, the structure.sql. If you have never felt the need to use plain SQL format for schema or never saw in the wild: here’s the great post from AppSignal that explains everything about the two formats.
I’ve always seen opting for structure.sql instead of schema.rb as a necessary evil: yes, it’s not fun to resolve merge conflicts in SQL, and schema.rb is way more concise, but it does not support some PostgreSQL features like triggers, sequences, stored procedures or check constraints (only added in Rails 6.1). No triggers mean no fast model tracking and no Logidze. Well, it used to mean that.
Everything changed when I discovered a real gem—F(x). It is a Rails-only library that allows you to declare your SQL functions and triggers in separate .sql files and provides an API to “load” them into your Ruby migrations and the schema.rb. Isn’t that brilliant?
So I decided to integrate F(x) into Logidze, and it solved the main problem: no matter if you use
schema.rb, orstructure.sql, Logidze has got you covered!
Now, if you have the fx gem installed in your project, Logidze generates functions and triggers using F(x) under the hood automatically. Check it out yourself:
Logidze ❤️ F(x)
Active Record time travel in the wild
Now it’s time to talk about some real stuff. You know, the one you do for a living, not just because your love to write code.
The problem
For the last few months, Martians and me have been helping the core tech team of Retail Zipline, a retail communications platform, to enhance key features for their customers, build new functionality, improve the overall performance, and improve the developer experience.
The feature that brought Logidze back into my life was one of the most critical for the platform: the “Surveys”.
In the simplest terms, the feature allowed:
- for managers to create questionnaires with different question types (single or multiple-choice, boolean, short answer, etc.);
- for users to submit their responses;
- for managers to generate reports and analyze historical data.

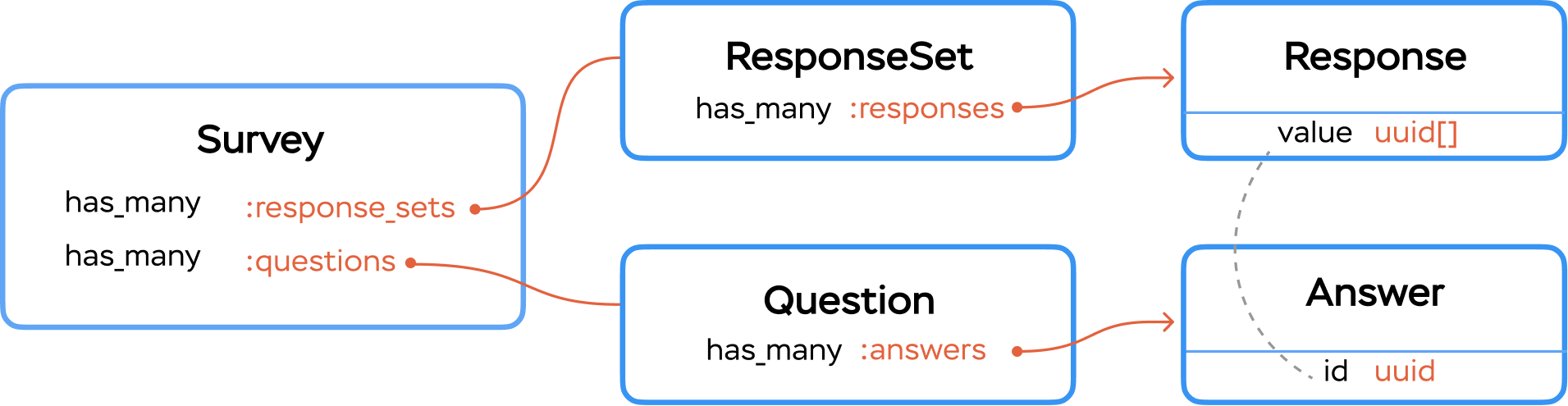
Surveys data model
Whenever a user submits an answer for a multiple-choice question, we create a Response record with the #value field (backed by the PostgreSQL array) that contains IDs of the chosen answers. To display those responses later, we would do something like this:
# approximate code
module Surveys
class Response < ApplicationRecord
def display_value
# Build a Hash of a form {answer.id => answer.value}
id_to_val = question.answers.index_by(&:id).transform_values!(&:value)
# Extract values by IDs and form a string
value.map(&id_to_val).compact!.join(", ")
end
end
endSo, what’s the problem?
The problem is that the answers are not immutable. They can be deleted or changed by survey creators. In fact, when editing surveys, users prefer to completely change an already created answer instead of deleting the old one and creating a new one. So the answer with ID 1 and value “Very important” can easily change its value to “Not important at all” over time. It’s a problem.
That makes historical data completely unreliable. We are never sure that the answer we see now used to mean the same thing in the past.
I’m sure you can see where I’m going.
The solution
We considered different approaches to solve the problem.
The most naive and straightforward option is to store raw values instead of IDs. This approach was rejected almost immediately: it breaks the data integrity. An improved version that stored raw values along with IDs also didn’t work out: surveys can have multiple translations, and we needed to show the responses in the current users’ locale. That required storing all the translated values, and that’s a lot of overhead from the storage perspective.
Another idea was to bring back immutability. Every time an answer is updated, we would create a new record with the same #reference_id and soft-delete the previous one (keep it in the database as hidden instead of removing the record). We can then use the real (not reference) IDs of responses to read values. Basically, this approach implements the snapshot-based versioning for the Answer model. The pseudo-code for this solution could look like this:
# app/models/surveys/answer.rb
module Surveys
class Answer < ApplicationRecord
# We used the paranoia gem
acts_as_paranoid
before_create :assign_reference_id
after_create :discard_previous_version
private
def assign_reference_id
# I like to use Nanoid for generating unique identifiers
self.reference_id ||= Nanoid.generate(size: 6)
end
def discard_previous_version
self.class
.where(reference_id: reference_id)
.where.not(id: id)
.update_all(deleted_at: Time.current) # Marked as deleted but still in DB!
end
end
end
# app/controllers/surveys/answers_controller.rb
module Surveys
class AnswersController < ApplicationController
# Update should create a new answer instead of updating the old one
def update
answer = Answer.find(params[:id])
# A duplicate would contain the old reference_id
new_answer = answer.dup
new_answer.assign_attributes(answer_params)
new_answer.save!
redirect_to new_answer
end
end
endAlthough this is a perfectly sane solution, it has its downsides. Text values are not the only thing that can change on an Answer; there are some utility fields (for instance, scoring parameters) that are, in fact, updated even more often. And updating them is completely fine from the business logic perspective, contrary to updating a text. That means more checking in the model for the soft-deletion logic, and there could be a race condition when the same answer is updated concurrently (could be fixed with a database lock). Certainly, there were even more edge cases lurking around, so we needed a more robust version tracking.
Enter Logidze! Here’s the example implementation:
module Surveys
class Question < ApplicationRecord
has_many :answers
# Add a specific association to load all answers, including the deleted ones,
# along with Logidze log data (which we ignore by default)
has_many :answers_with_deleted, -> { with_deleted.with_log_data },
class_name: "Surveys::Answer",
inverse_of: :question
# ...
end
class Response < ApplicationRecord
# Adds .with_log_data scope
has_logidze
def display_value
# We added .with_deleted_answers scope to handle soft-deleted answers.
# And now we can use Hash#slice to return only the required answers.
# See https://api.rubyonrails.org/classes/Enumerable.html#method-i-index_by
# for ActiveSupport:Enumerable#index_by
answers = question.with_deleted_answers.index_by(&:id).slice(*value).values
# The above gives us a nice hash with all text values that were used for each answer, grouped by ID.
answers.map do |answer|
# Fallback to the current state if response was created before we added logs
answer = answer.at(time: created_at) || answer
answer.value
end.join(", ")
end
end
endThat’s it! We don’t need to change anything else. Just add a few lines of code (and, of course, don’t forget to generate Logidze migrations).
Logidze-backed implementation got a green light from the Retail Zipline team and was successfully shipped to production.
Yesterday, today, and tomorrow too
Four years into the gem’s life, I have finally shipped a production feature that relies on it.
Why did I build a gem and never used it seriously myself? Unlike AnyCable, Logidze wasn’t built as an open-source experiment—it was my test task to become an Evil Martian! (Now you see why we call ourselves “evil” 🙂)
The evolution of Logidze was driven mainly by bug reports and feature requests. With version 1.0, we have reached stability and have dotted all the “i”-s. Logidze, in its original design, is done.
What about the future?
While working on the release, I put a lot of effort into improving the code and tests related to PostgreSQL procedures. Logidze is, actually, 70% PL/pgSQL and 30% Ruby/Rails. The obvious first step towards 2.0 is to drop the Rails dependency completely (remember, Ruby != Rails).
We can then go further and transform Logidze into a PostgreSQL library (extension/helper/whatever). Besides separating SQL and Ruby, I would also like to move diff calculation to the database:
SELECT posts.*,
logidze_diff_from(
'2020-10-09 12:43:49.487157+00'::timestamp,
posts.log_data
) as logidze_diff
FROM postsAlso, we can add some helper functions to query against the log data. One common use-case is to fetch all the records that had a specific value for a particular field at any given point in time:
SELECT posts.*
FROM posts
WHERE logidze_log_exists(
posts.log_data,
'moderation_status',
'suspicious'
)With the recent addition to PostgreSQL, SQL/JSON Path Language added in version 12, that would be just syntax sugar for:
SELECT posts.*
FROM posts
WHERE jsonb_path_exists(
posts.log_data,
'$.h[*].c ? (@.moderation_status == "suspicious")'
)Moving responsibility from the application code to the database might sound like driving on the wrong side of the road, but it does not have to be. In my opinion, implementing product features at the database level is not a good idea, while moving some number crunching or another utility code to the DB is absolutely 👌.
Thank you for reading, enjoy your model tracking and PostgreSQL triggers responsibly. If you face any of the challenges that we described at your company, don’t hesitate to start a conversation to see how we could be of help with your product.