Open Source Software. What is in a poke?



In this article, I will share my findings on ranking RubyGems using different sources and introduce a new, open source SaaS for ranking Ruby gems.
In our work, we come across plenty of libraries, frameworks, and tools. We have many options and we are supposed to choose the best option—and support existing code that relies on it.
So how do we navigate the endless sea of frameworks and distinguish the useful tools from garbage? How do we measure a framework’s trustworthiness and its current state of development?
Diving into the issue
In the world of Ruby development, choosing between different open source tools has become a routine part of the project development lifecycle. It has become quite a challenge to use many dependencies in a project since the creation of RubyGems and Bundler.
However, it doesn’t occur to us that our app and library code is now mostly third-party library code we’re not even familiar with—not the code we’ve written ourselves.
Like Uncle Ben taught us, “With great power comes great responsibility”. The latter, unfortunately, is slowly vanishing in a sea of plug-and-play open source solutions for virtually any task.
We often don’t even scan the code we want to use: we just plug in a new library and see what happens. With this approach, there’s a high risk we end up using the wrong tool—a hammer instead of a screwdriver.
The team at Thoughtbot has put together this checklist for trying new libraries:
- Evaluate the maintenance quality
- Check the quality and security of the code
- Check the resource consumption under high load
- See how many new dependencies the solution adds
- Inspect the licenses
- Become familiar with the API and DSL
In some cases, following this checklist is the most a person would need to do to get to know the library.
There are about 130 thousand gems posted on RubyGems at the moment. However, if we look at download data, we see that only about 2 thousand gems exceed 500 downloads a day.

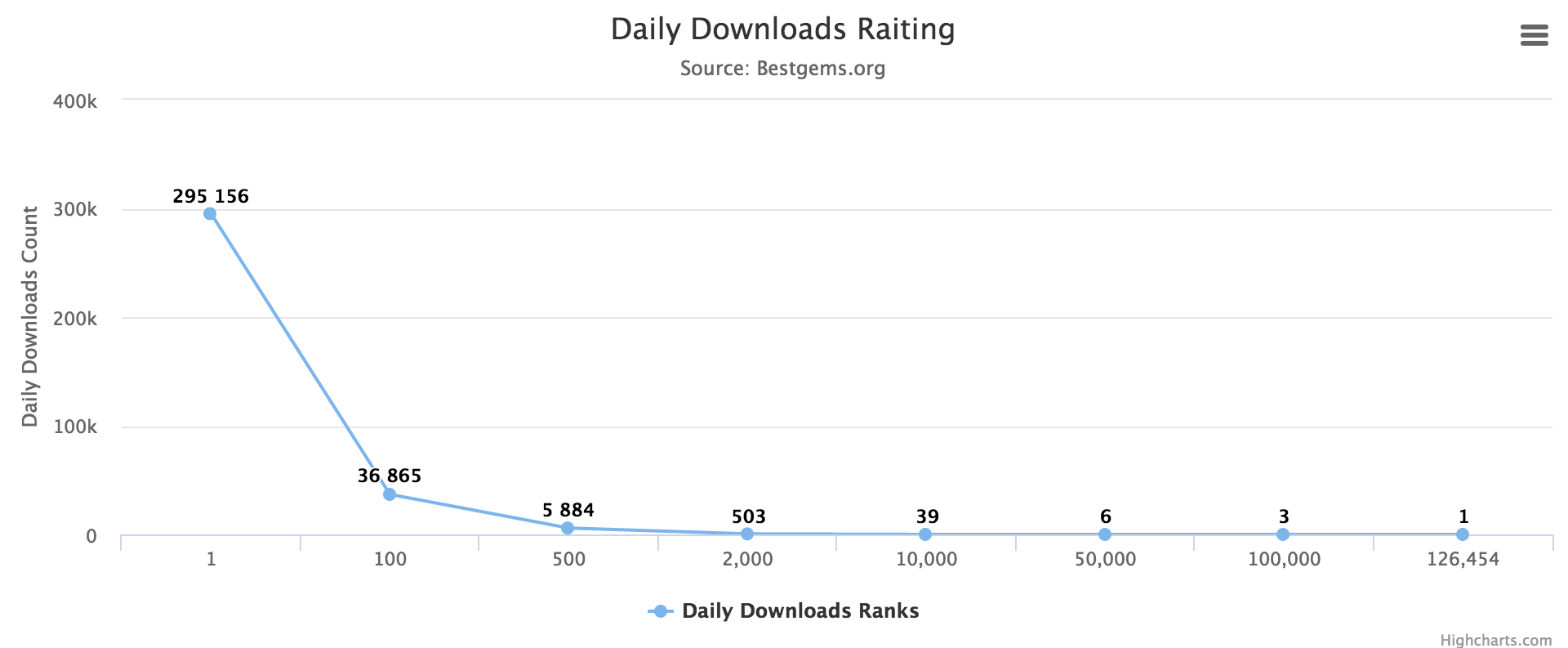
Daily Downloads Rating
Only about 10 thousand gems are in daily active use.

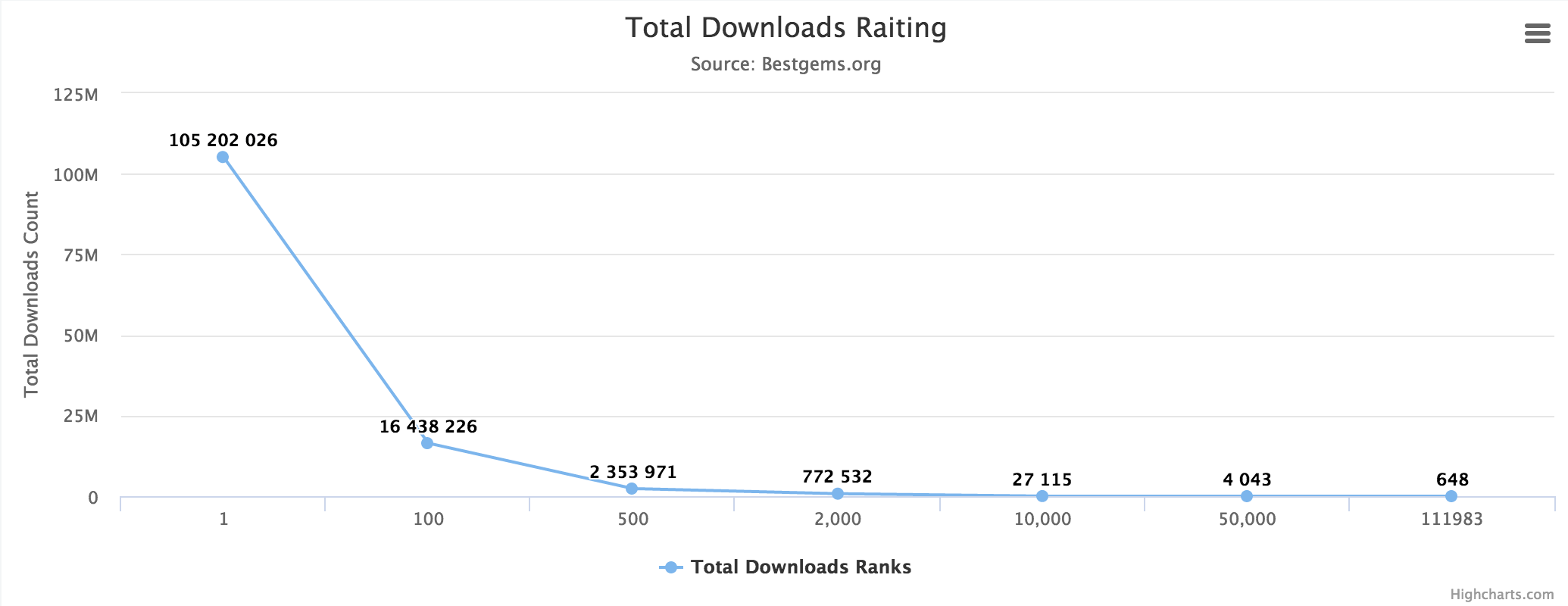
Total Downloads Ranking
So, if we pick a random project from RubyGems, there’s about 90% probability it hasn’t been well tested in production!
According to Module Counts, about 50 new gems are created every day. That is 1,500 new gems every month! This problem, as it turns out, is not unique to the Ruby community. In fact, the Ruby community isn’t even the fastest growing out of all the communities.

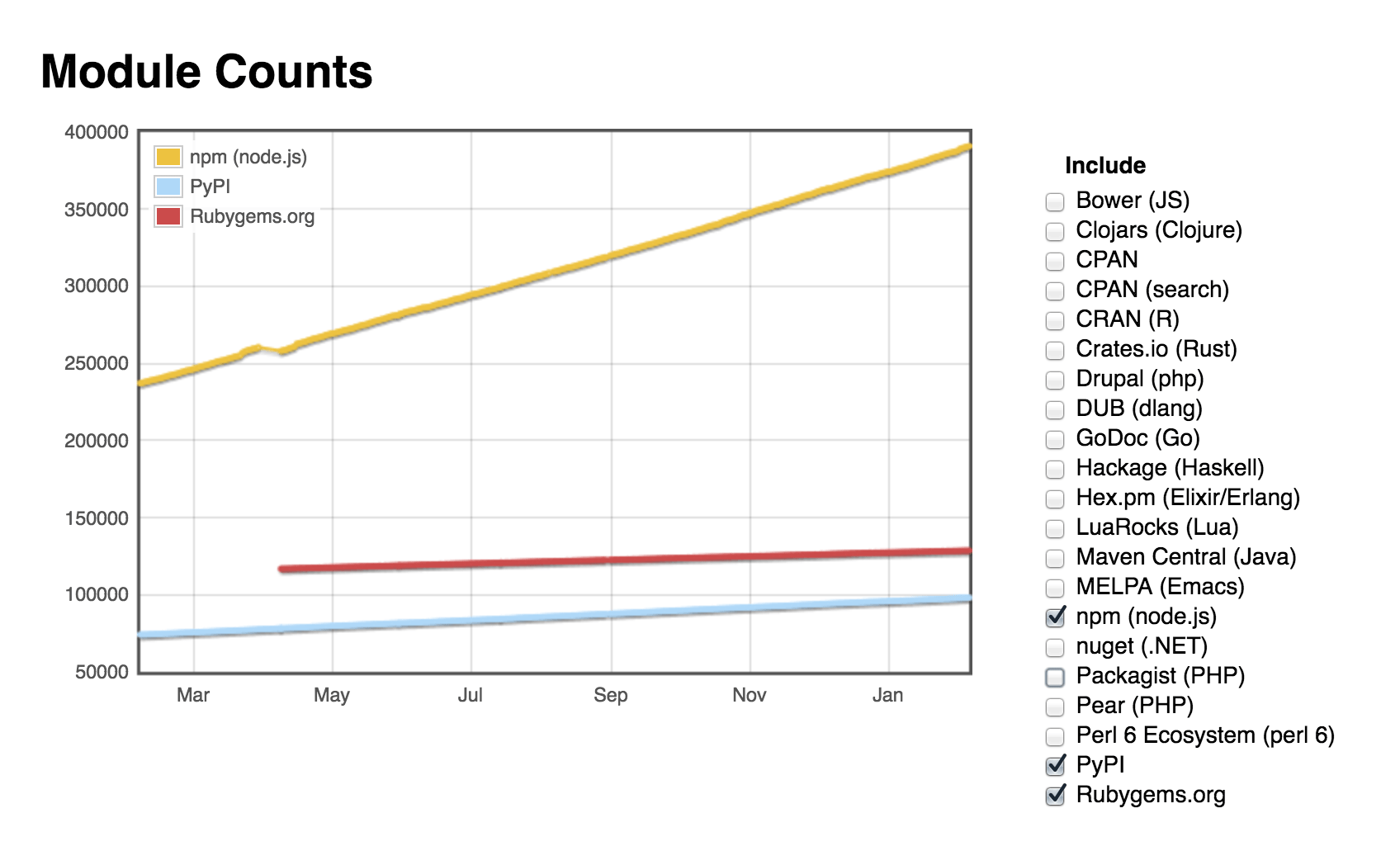
Module Counts
Let’s assume that the obvious solution is sticking to the most popular project. However, here’s another twist: according to my measurements, (based on GitHub data, more on that later) only 33% of the Top 5000 projects are well maintained!

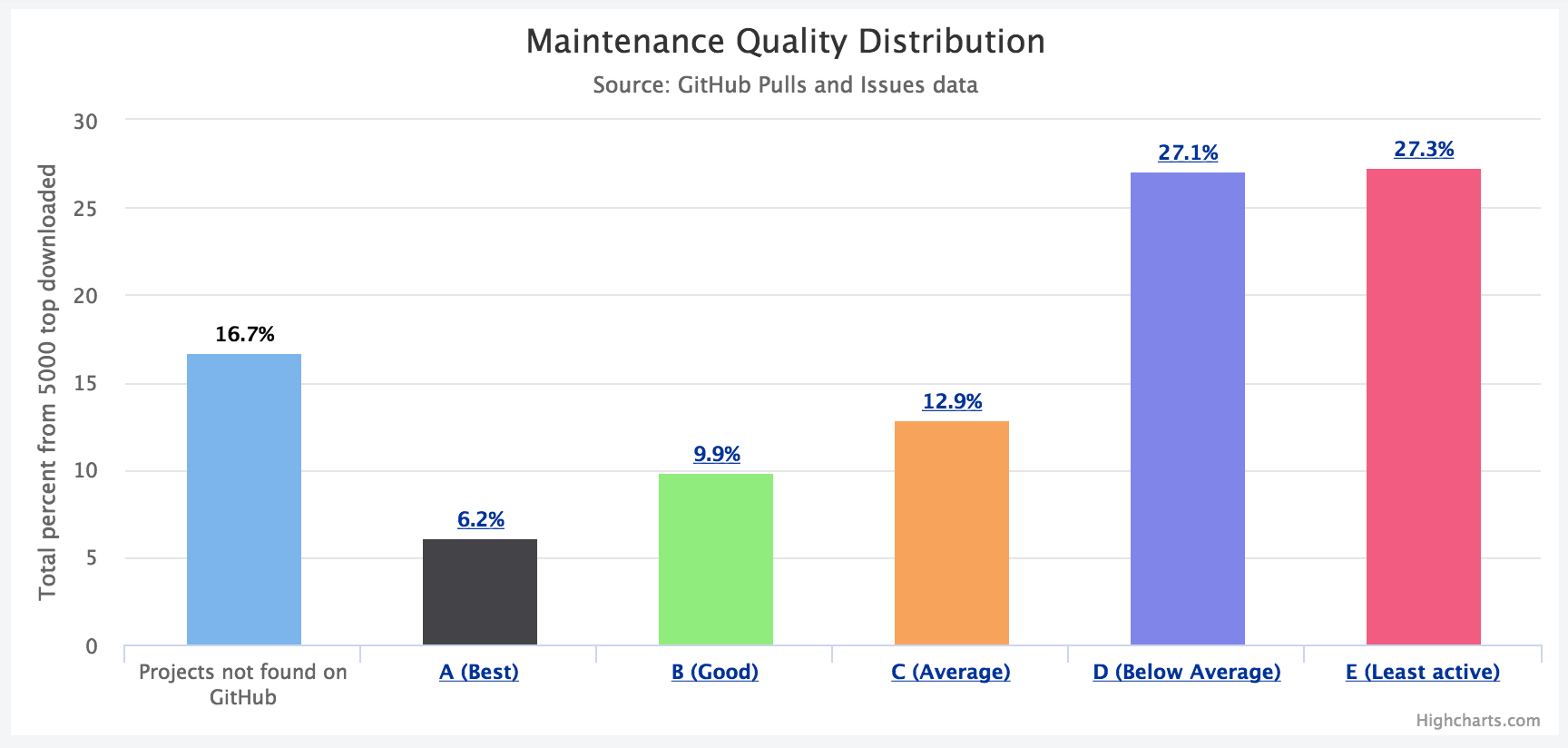
Maintenance Quality Distribution
This means we need to be more selective when it comes to picking gems for our projects.
I started thinking about automating the selection process in the middle of my typical sequence of picking a gem:
Google → КubyToolbox, RubyGems → GitHub → decision.
Research
Where do we start?
To automate the selection process, we need to understand what data we have, and how we are going to make a final decision about whether the project is trustworthy and stable or not. I made the assumption I could collect all the necessary data with HTTP APIs.
What do we have?
Following my standard algorithm, I decided to look for the data on RubyGems, RubyToolbox, and GitHub. Let’s see how these can be useful for us and how we can extract data for our research.
RubyToolbox
I usually check Ruby Toolbox first because it is an excellent project catalog. Here, the developers look for big projects solving particular problems, such as ActiveRecord nesting.

Ruby Toolbox Home
The users also receive a brief project status: total downloads, development activity, last commit, and release dates.

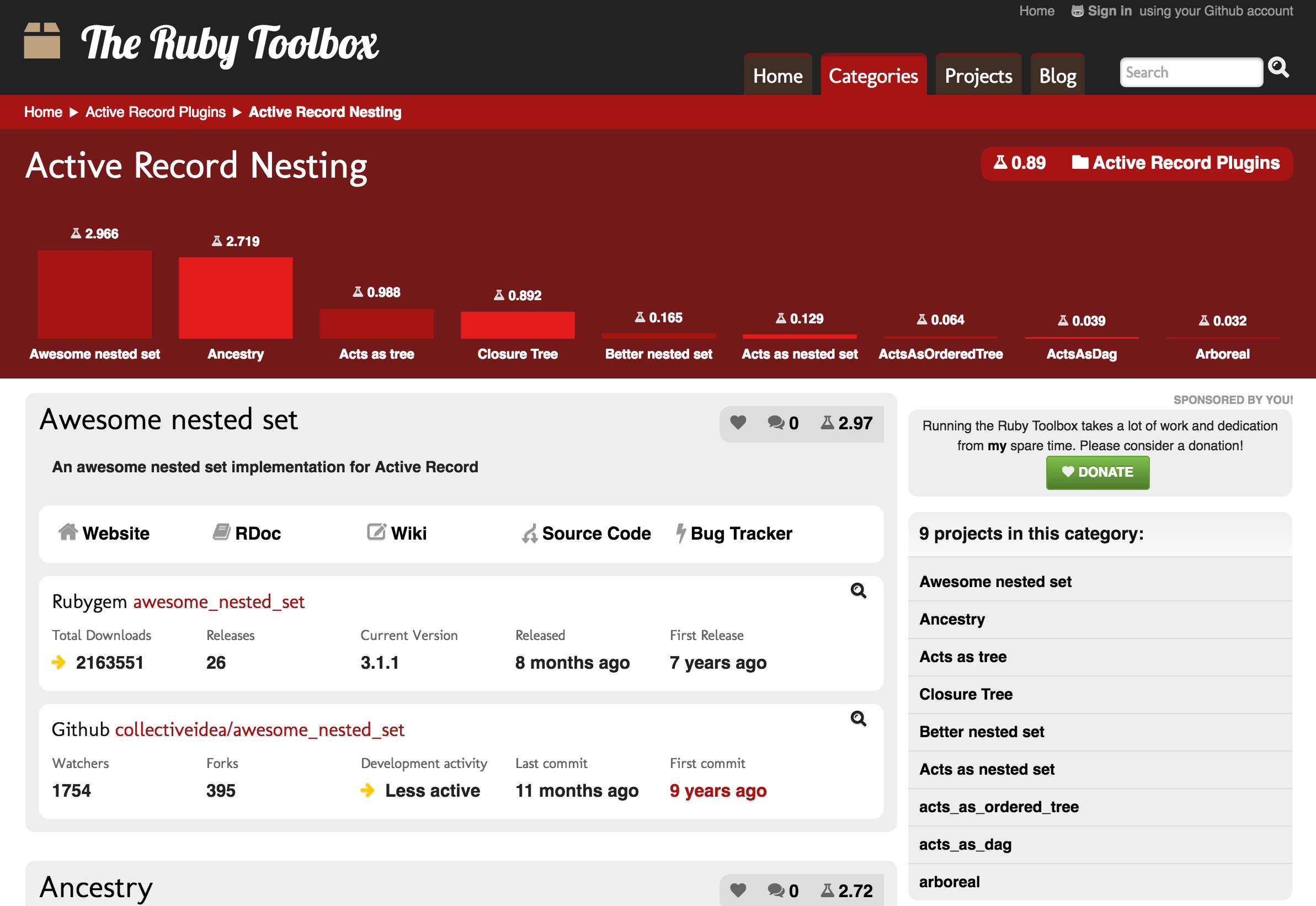
Ruby Toolbox Show
Unfortunately, RubyToolbox does not have an API, and I have decided not to extract data straight out of the page. RubyGems and GitHub, however, both have APIs I can use to gather data for further research.
RubyGems

RubyGems API
RubyGems is the Ruby community gem hosting service. It has an API that gives some basic information about any given gem. For our experiment, we can use total downloads and release info. Due to the latest changes in API, we do not have the opportunity to request the number of downloads for a particular period, so we need another way to figure it out.
BestGems

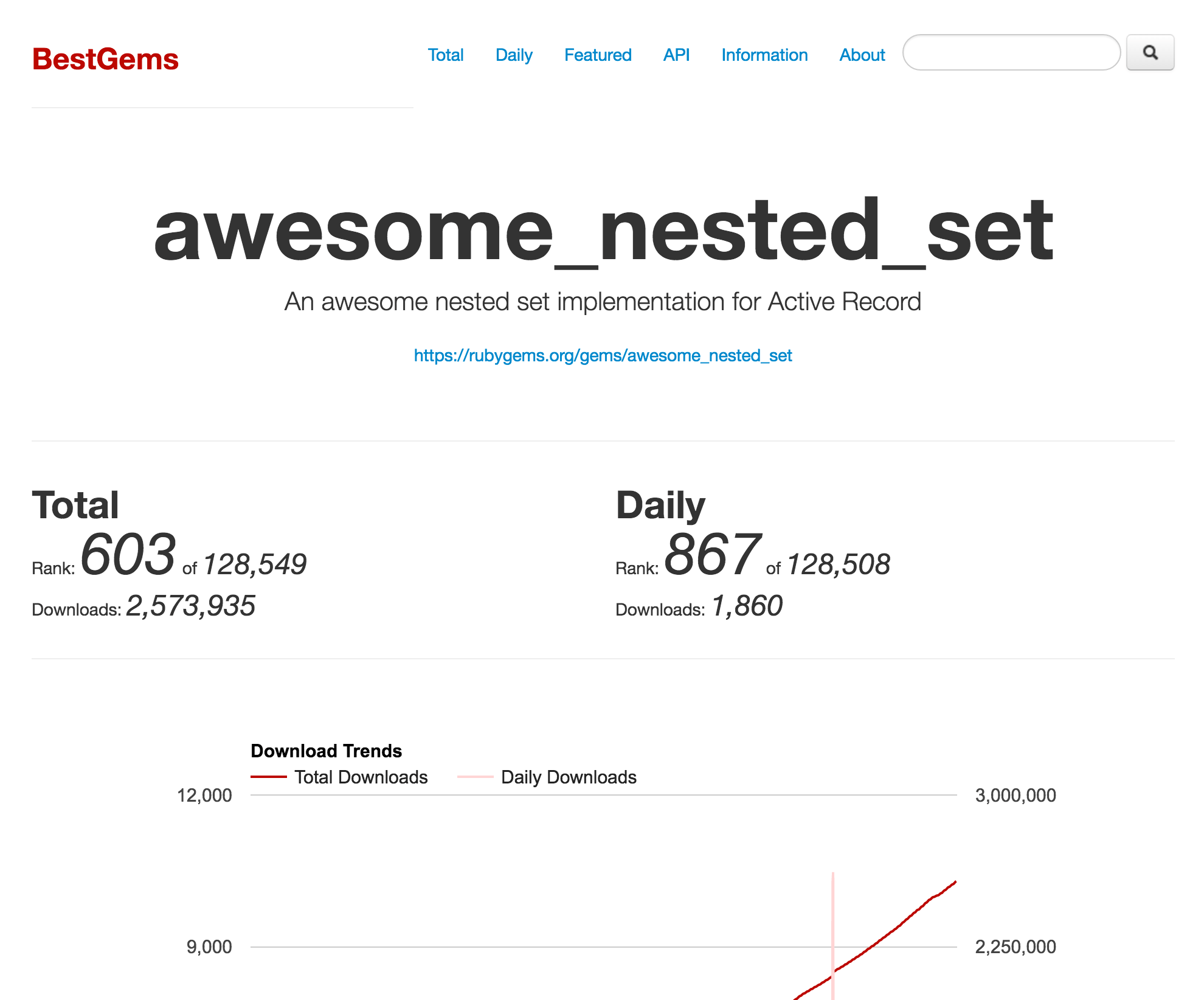
BestGems.org
BestGems.org is a Ruby gems downloads ranking site. It’s very simple but very useful. It has the Trends API that can give valuable information about the number of downloads on any given day since the gem has been posted.
Also, BestGems.org has a gem rating by downloads count. This means we can see how many projects have enough downloads to be considered a stable solution.
GitHub

GitHub
My next step would usually be looking through each solution’s GitHub repositories. Since I am not able to compare full statistics, I will check if there were any Issues or Pull Requests recently, and if any of these were closed. Then, I will look through the documentation to see how the solution works and if the API and DSL are right for me.
It seems like, when it comes to choosing a project, it would have been more useful if we processed the data than if we looked at it from GitHub’s UI. Let’s try to get data from the API.
API
First, we have information about Issues and Pulls—by who they were created and when they were opened and closed. Secondly, if we are talking about open source projects, we need to talk about their communities.
From the API, we can get Contributors, Watchers, Stargazers, and the users who created Issues or Pull Requests or added comments.
However, what about commits? GitHub has restricted information about commits to the previous year’s data, but it’s not a big deal for our research. Let’s move on.
What are we looking for?
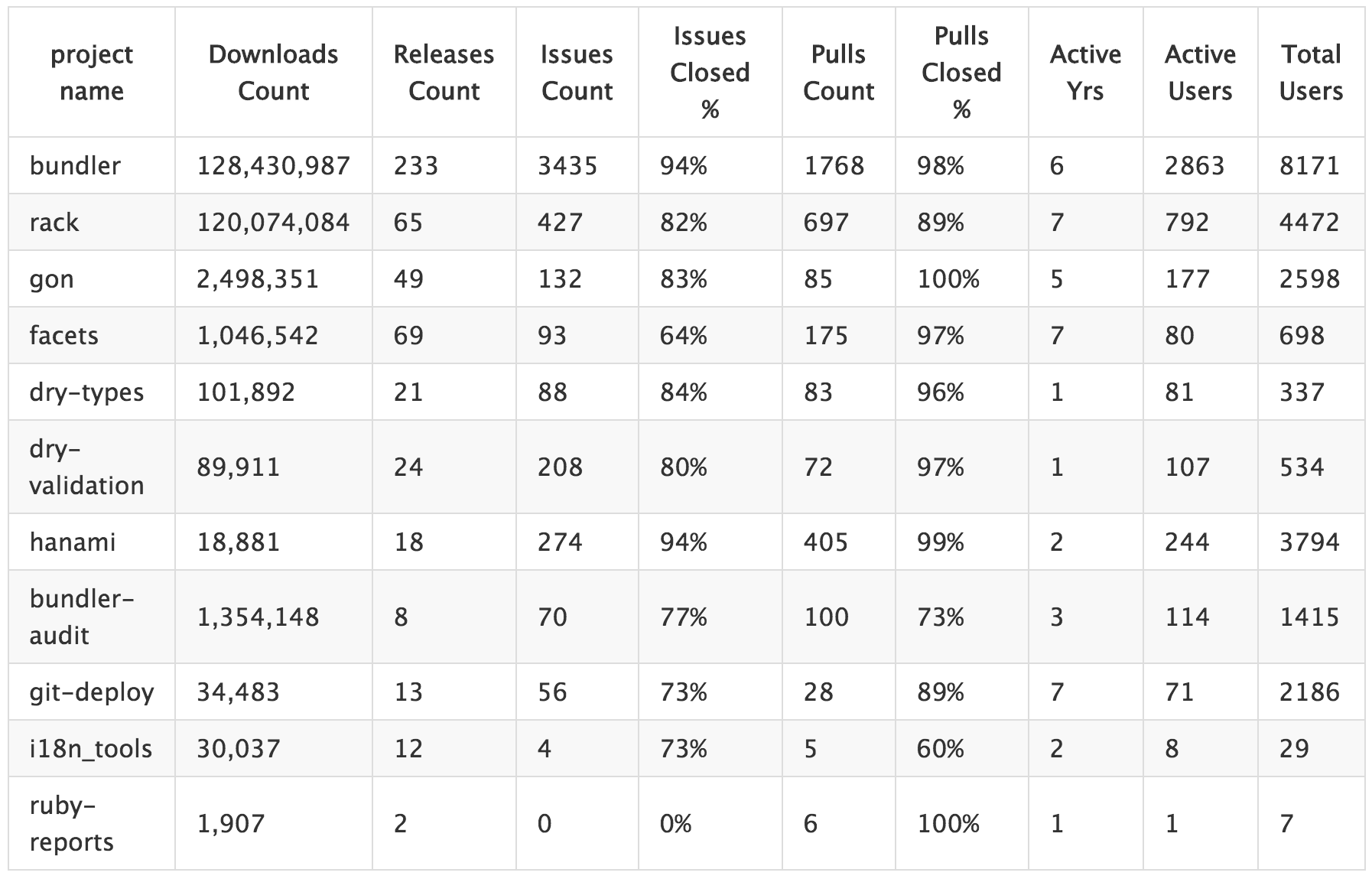
For comparison, I decided to pick several projects with a different number of downloads from RubyGems and chose these parameters:
- Total downloads
- Total releases
- Issues and Pull Requests quantity
- % of closed Issues and Pull Requests
- Activity time—from creation of the first Pull Request or Issue to creation of the latest
- Number of commits
- Number of people creating Issues and Pull Requests
- Number of people interested in and participating in the project on GitHub
To get the full picture, we’ll need to look at both all time data and data from the previous year only.
For the research I picked the following projects:
- bundler, rack (from RubyGems Top 10)
- gon, facets, dry-types, dry-validation, hanami (popular projects, lower than Top 500)
- bundler-audit, git-deploy, i18n_tools, ruby-reports (little-known projects)
All-time data

Comparison Table (Total)
Data for the past year

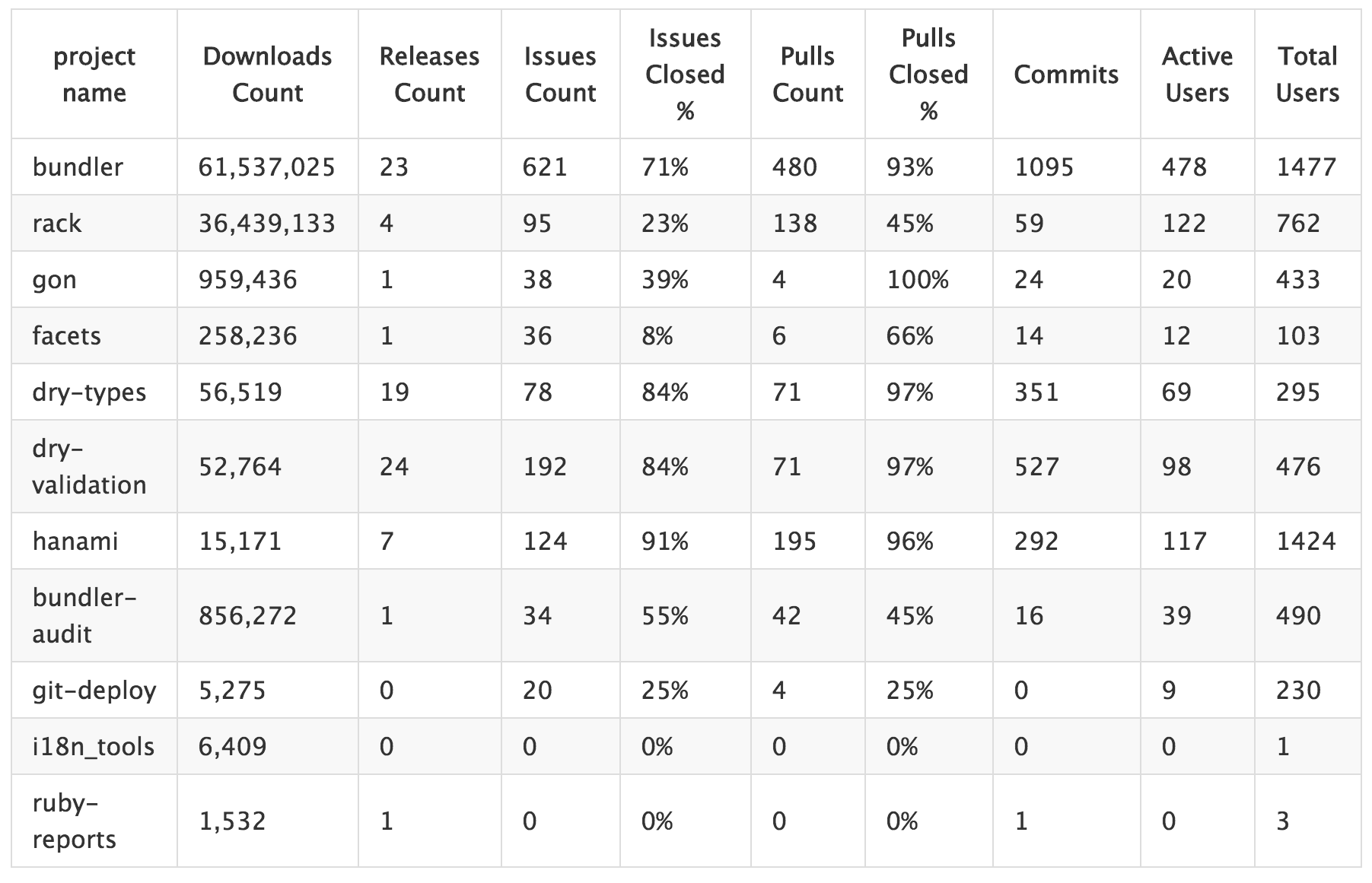
Comparison Table (Past Year)
What do we do with all this data?
We have ended up with quite a lot of figures. To make decisions based on these numbers, we need to create a classification model that will help us evaluate the project’s stability and development status.
I’ve decided to base this model on an existing one—the Open Source Maturity Model. It’s a little bit outdated, but the basic concept is very convenient for our task.
We will define maturity as the sum of all work accomplished in this project. In this case, by accomplished work I mean certain parameters, such as the percentage of closed Pull Requests. So, we will have to link all the measurables to the project maturity.
To cover all possible project activity, I singled out the four basic directions of open source project development:
- Popularity
- Maintenance quality
- Code characteristics
- Documentation characteristics
For the most accurate evaluation, we will need to take all named directions in consideration. However, for the first approximation, I decided to combine Popularity and Maintenance quality, because these can be used for faster decision making.
Popularity
Popularity can be presented as a dependency between a number of people participating in the project and their interactions with the project by such data as:
- Number of people creating tickets and commenting on tickets
- Number of project dependencies
- Total stars
- Total downloads
Maintenance
Maintenance quality can be presented as a dependency from actions targeted on project development and fixes, by such data as the percentage of closed Issues and Pull Requests, a total number of changes, and fixes speed.
Project maturity will be a total evaluation based on project Popularity and Maintenance Quality.
So, how do we get to actual calculations?
I took each parameter’s value, defined the rules for its evaluation and its weight applied to the direction of development. This way, by summing up the evaluations and taking their weight into consideration, we receive the final point for each direction.
For example, for Maintenance Quality evaluation, the percentage of closed Pull Requests, especially for past months, is very important. So, for this parameter, the weight would equal 1 for all time, and 2 for the previous year.
This is how we’re giving points to the projects:
- Less than 20%: 0 points
- 20% to 40%: 1 point
- 40% to 60%: 2 points
- 60% to 80%: 3 points
- 80% to 100%: 4 points
I ranked the project from A to E in each direction:
- A: the most developed (popular, well maintained, mature, etc.)
- B: well developed
- C: moderately developed
- D: poorly developed
- E: experimental
The development classifier is worth another article, so we won’t get into that. Let’s take a look at the results received.
Let’s go live!
Here are the marks the classifier gave the projects we picked:
| Maintenance | Popularity | Maturity | |||||
|---|---|---|---|---|---|---|---|
| bundler | A | A | A | ||||
| rack | C | A | A | ||||
| gon | D | C | C | ||||
| facets | C | B | B | ||||
| dry-types | A | B | B | ||||
| dry-validation | A | B | B | ||||
| hanami | A | C | B | ||||
| bundler-audit | C | B | B | ||||
| git-deploy | D | D | C | ||||
| i18n_tools | E | E | E | ||||
| ruby-reports | E | E | E |
It looks like the results do not contradict prior research (see project links).
Let’s check how it will handle comparing projects solving similar problems. For testing, we picked attachment download processing and background processing projects. We’ll search for popular solutions using RubyToolbox.
Attachment download processing
| Maintenance | Popularity | Maturity | |||||
|---|---|---|---|---|---|---|---|
| attached | D | E | E | ||||
| dragonfly | D | B | B | ||||
| carrierwave | B | A | A | ||||
| paperclip | A | A | A |
Let’s see Popularity and Maintenance graphs of them.
Carrierwave lost a few points to Paperclip in the closed Issues department (63% vs. 72%, 238 and 266 Issues), but it has a higher percentage of closed Pull Requests (97% vs. 89%, 114 and 136 closed Pull Requests).
Paperclip also has a more active community that is bigger than Carrierwave’s (609 vs. 493 active GitHub users).
The two all-time leaders are, of course, Carrierwave and Paperclip—no need to worry about reliability with these. It seems like both solutions are somewhat equal and you can pick one by comparing DSLs, for example.
When it comes to the alternatives, Dragonfly feels left far behind. The previous year activity was low, compared with previous projects:
- 7 commits
- 15 Pull Requests, only a third of which are closed
- 58 Issues, 15% closed
- 64 active users
Judging by the number of active users, this project has potential, but it’s useless because of poor maintenance quality. If for some reason you need to use this particular gem, fork it and monitor the changes. Yes, in this case, you’ll have to maintain the code all by yourself.
Attached had shown close to zero previous year activity. Obviously, it’s risky to use such an experimental project in enterprise development. You can also see the maintenance activity decrease in both projects.
Background processing
| Maintenance | Popularity | Maturity | |||||
|---|---|---|---|---|---|---|---|
| sidekiq | A | A | A | ||||
| resque | B | A | A | ||||
| sucker_punch | A | B | B | ||||
| delayed_job | C | A | A |
Take a look at popularity and maintenance graphs of them.
These projects all seem like a good competition for each other, except delayed_job, which performed poorer than the others. Let’s see how the projects were ranked.
Previous year Issues:
| Count | Closed % | Half closed within | |||||
|---|---|---|---|---|---|---|---|
| sidekiq | 503 (50 at the beginning of the year) | 98% | 2 weeks | ||||
| resque | 155 (124 at the beginning of the year) | 66% | 10 months (!) | ||||
| sucker_punch | 43 (7 at the beginning of the year) | 97% | 2 weeks | ||||
| delayed_job | 125 (88 at the beginning of the year) | 32% | 2 months |
Previous year Pull Requests:
| Count | Closed % | Half closed within | |||||
|---|---|---|---|---|---|---|---|
| sidekiq | 117 (5 at the beginning of the year) | 100% | 6 days | ||||
| resque | 171 (65 at the beginning of the year) | 95% | 7 months (!) | ||||
| sucker_punch | 17 (1 at the beginning of the year) | 100% | 4 days | ||||
| delayed_job | 53 (33 at the beginning of the year) | 30% | 25 days |
Active users:
| GitHub Stars | Users | ||||
|---|---|---|---|---|---|
| sidekiq | 1306 | 820 | |||
| resque | 765 | 305 | |||
| sucker_punch | 392 | 59 | |||
| delayed_job | 387 | 204 |
Downloads and dependencies:
| Dependants Count | Downloads | ||||
|---|---|---|---|---|---|
| sidekiq | 350 | 4.5M | |||
| resque | 429 | 2.2M | |||
| sucker_punch | 45 | 0.3M | |||
| delayed_job | 139 | 1.8M |
After all
There’s a striking inconsistency between delayed_job’s number of downloads and dependencies and its maintenance quality. Here we can see that project popularity does not necessarily equal good support or represent the actual, objective state of development.
Unfortunately, I would not recommend using delayed_job in production, unless you want to solve all the possible problems yourself.
Among the other solutions, I would like to note that sucker_punch looks like fair competition for Sidekiq and Resque. Even though its audience is smaller, compared to the others, it handles project maintenance and development well enough.
The results
We see that the classifier helps to evaluate how risky the gem is for use in production. If a project is marked with A’s and B’s—the library is reliable and safe, before any maintenance quality decrease.
Using a project with C’s increases your open source use responsibility. If you opt for using a C-marked project, you need to have a clear understanding of what you will do if something goes wrong, or, at least, be familiar with this code base. D’s and E’s can only be used in production if you are ready to take full control and responsibility for the code maintenance and are very familiar with the code base.
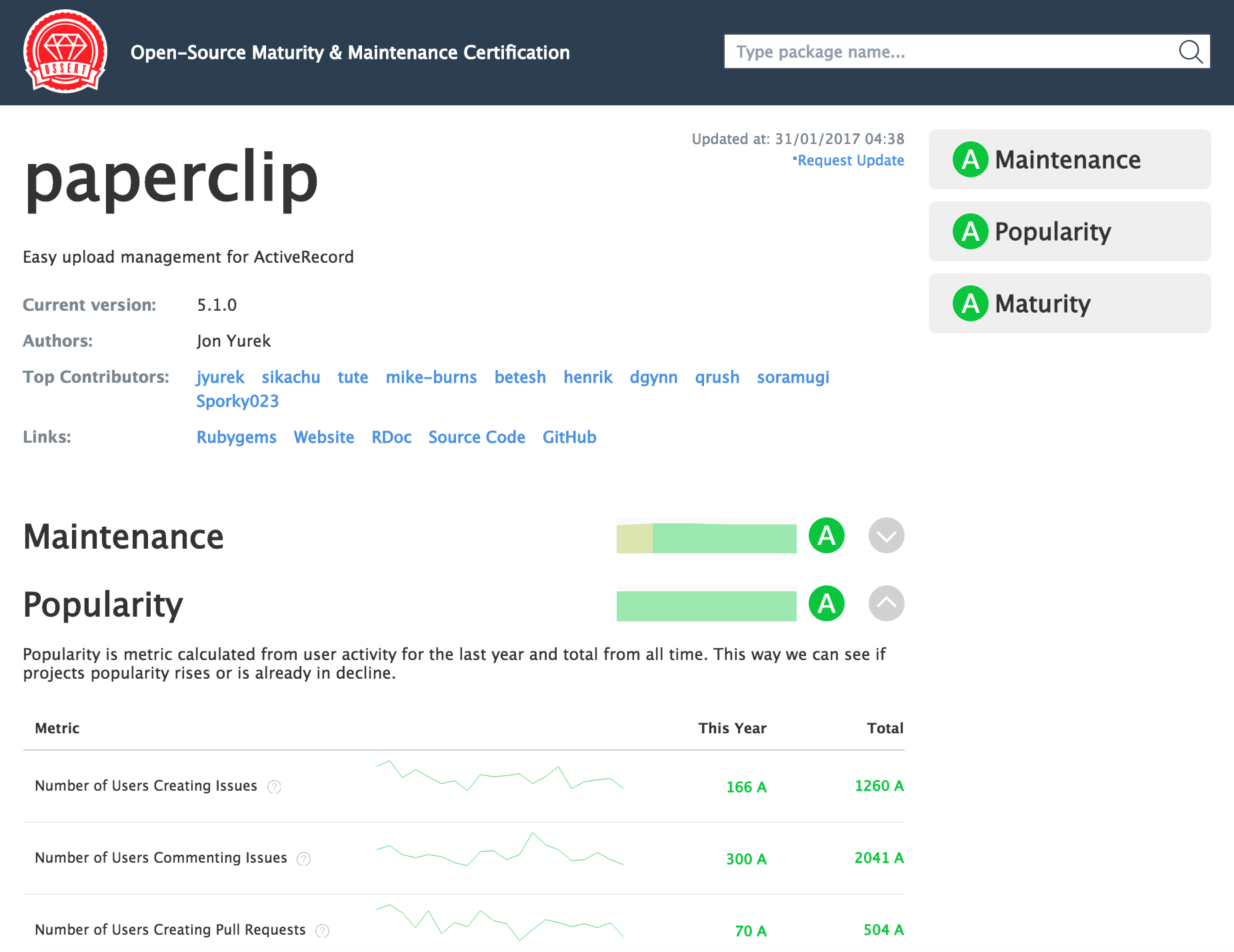
I consider my experiment on automation of project maturity evaluation quite successful. The classifier I created for the research is now an open source SaaS.
The classifier, called Osset, is an open source SaaS that checks a given gem’s reliability and provides a detailed report of every evaluation. You can analyze information on given parameters and see quarterly dynamics, starting from the release date.
Say hello to Ossert!

Ossert Project Page

What’s next?
In further articles, I will tell you more about the classification methods and techniques I applied to open source software lifecycle data.
While working on Ossert, I came across some problems the OSS community is facing:
- How do we improve supported gems’ metrics?
- How do we increase the number of well-maintained projects?
- How to avoid abandoning a project once you have started?
- Is committing to other people’s projects worth spending time on?
For solving the problems, I plan to do more Ossert-based research, and I will share the fruits with you.
So stay tuned!