


A hitchhiker’s guide to developing GraphQL applications with Rails on the backend side and React/Apollo on the frontend side. Follow this multi-part tutorial to learn both the basics and the advanced topics by example and feel the power of this modern technology.
Other parts:
- GraphQL on Rails: From zero to the first query
- GraphQL on Rails: Updating the data
- GraphQL on Rails: On the way to perfection
GraphQL is one of those new shiny things we’ve been seeing here, there and everywhere: blog posts, conferences, podcasts, maybe, even newspapers. It sounds like you should hurry up and start rewriting your application in GraphQL instead of REST as soon as possible, right? Not exactly. Remember: there is no silver bullet. It’s essential to understand the pros and cons of the technology before making a paradigm-shift decision.
In this series, we’re going to walk you through a no-frills guide to the development of GraphQL applications, talking about not only its advantages but also its caveats and pitfalls (and, of course, the ways to deal with them).
GraphQL in a nutshell
According to the specification, GraphQL is a query language and runtime (or execution engine). Query language, by definition, describes how to communicate with an information system. Runtime is responsible for fulfilling queries with data.
At the core of every GraphQL application lies a schema: it describes the underlying data in the form of a directed graph. The runtime must execute queries according to the schema (and some general rules from the specification). That means, every valid GraphQL server runs queries in the same manner and returns data in the same format for the same schema. In other words, the schema is everything clients should know about the API.
Here is an example of a simple GraphQL query:
query getProduct($id: Int!) {
product(id: $id) {
id
title
manufacturer {
name
}
}
}Let’s dissect it line by line:
- We define a named query (
getProductis the operation name) accepting a single argument ($id). The operation name is optional, but it helps readability and could be used by frontend for caching. - We “select” the
productfield from the “root” of the schema and pass the$idvalue as an argument. - We describe the fields we want to fetch: in this case, we want to get the
idandtitleof the product as well as thenameof the manufacturer.
Essentially, a query represents a sub-graph of the schema, which brings the first benefit of GraphQL—we can fetch only this data we need and all we need at once, in a single query.
This way, we solve one of the common problems of the traditional REST APIs—overfetching.
Another noticeable feature of GraphQL schemas is they are strongly typed: both client and runtime ensure that the data passed is valid from the perspective of the application’s type system. For example, if someone mistakenly passes a string value as the $id to the query above, the client fails with the exception without even trying to perform a request.
And the last but not least bonus is a schema introspection: clients can learn the API from the schema itself, without any additional documentation sources.
We’ve just learned a bunch of theoretical aspects of GraphQL. Now it’s time to do some coding exercises to make sure you won’t forget everything tomorrow’s morning.
What are we going to build?
During this series, we will be building an application representing a “Martian Library”—a personal online collection of movies, books, and other art objects related to the Red Planet.

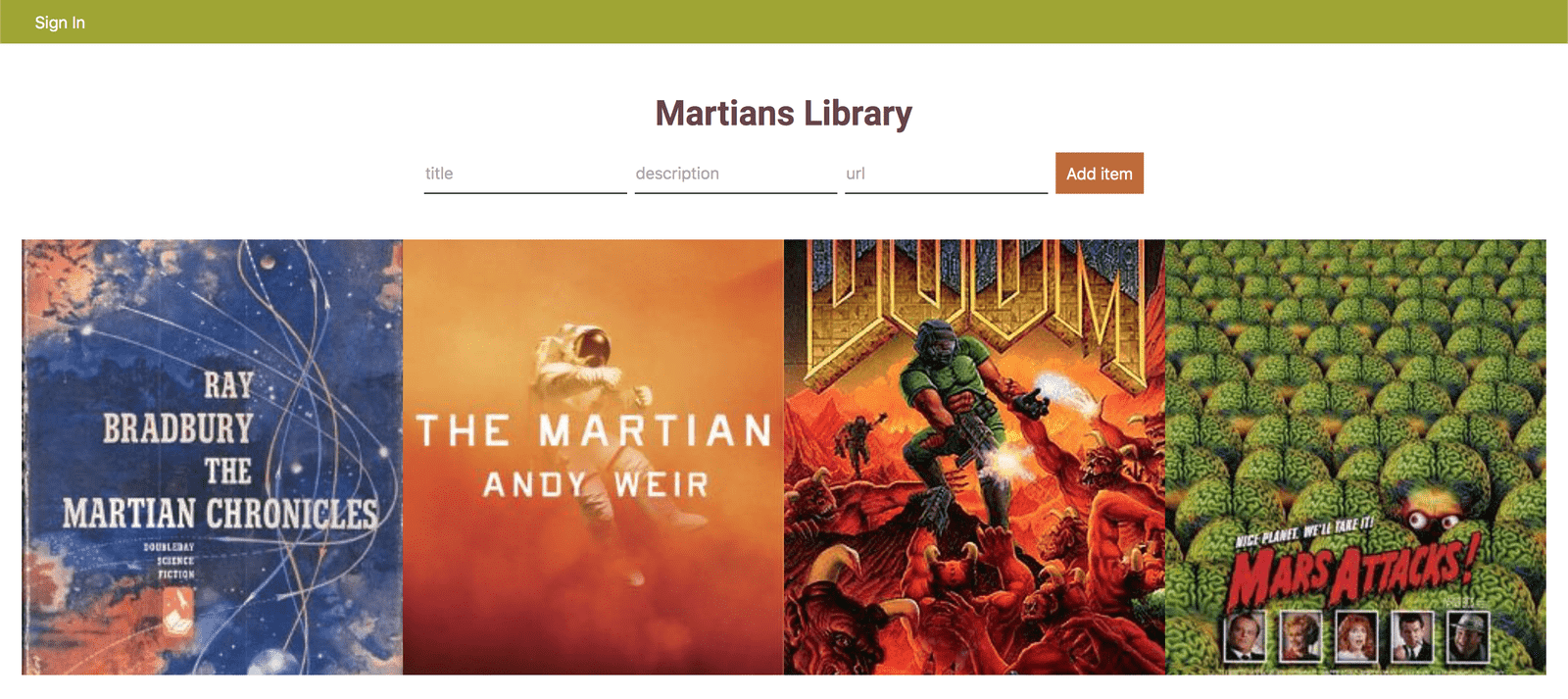
The application we are going to build
For this tutorial, we’re going to use:
- Ruby 2.6 and Rails 6 (release candidate is already here) for backend.
- Node.js 9+, React 16.3+, and Apollo (client version 2+) for frontend (and make sure you have yarn installed according to the instruction).
You can find the source code here—don’t forget to run bundle install && yarn install before the first run. master branch represents a current state of the project.
Setting up a new Rails project
If at the time of reading this article Rails 6.0 hasn’t been released yet, you might need to install the release candidate first:
$ gem install rails --pre
$ rails -v
=> Rails 6.0.0.rc1Now we’re ready to run this unexpectedly long rails new command:
$ rails new martian-library -d postgresql --skip-action-mailbox --skip-action-text --skip-spring --webpack=react -T --skip-turbolinksWe prefer okonomi to omakase: skip frameworks and libraries we don’t need, choose PostgreSQL as our database, preconfigure Webpacker to use React, and skip tests (don’t worry—we’ll add RSpec soon).
Before you start, it’s strongly recommended that you disable all the unnecessary generators in the config/application.rb:
config.generators do |g|
g.test_framework false
g.stylesheets false
g.javascripts false
g.helper false
g.channel assets: false
endPreparing the data model
We need at least two models to start:
Itemto describe any entity (book, movie, etc.) that we want to store in the libraryUserto represent the application user who can manage items in the collection.
Let’s generate them:
$ rails g model User first_name last_name email
$ rails g model Item title description:text image_url user:referencesDon’t forget to add the has_many :items association to app/models/user.rb:
# app/models/user.rb
class User < ApplicationRecord
has_many :items, dependent: :destroy
endLet’s add some pre-generated data to db/seeds.rb:
# db/seeds.rb
john = User.create!(
email: "john.doe@example.com",
first_name: "John",
last_name: "Doe"
)
jane = User.create!(
email: "jane.doe@example.com",
first_name: "Jane",
last_name: "Doe"
)
Item.create!(
[
{
title: "Martian Chronicles",
description: "Cult book by Ray Bradbury",
user: john,
image_url: "https://upload.wikimedia.org/wikipedia/en/4/45/The-Martian-Chronicles.jpg"
},
{
title: "The Martian",
description: "Novel by Andy Weir about an astronaut stranded on Mars trying to survive",
user: john,
image_url: "https://upload.wikimedia.org/wikipedia/en/c/c3/The_Martian_2014.jpg"
},
{
title: "Doom",
description: "A group of Marines is sent to the red planet via an ancient " \
"Martian portal called the Ark to deal with an outbreak of a mutagenic virus",
user: jane,
image_url: "https://upload.wikimedia.org/wikipedia/en/5/57/Doom_cover_art.jpg"
},
{
title: "Mars Attacks!",
description: "Earth is invaded by Martians with unbeatable weapons and a cruel sense of humor",
user: jane,
image_url: "https://upload.wikimedia.org/wikipedia/en/b/bd/Mars_attacks_ver1.jpg"
}
]
)Finally, we’re ready to initialize our database:
$ rails db:create db:migrate db:seedNow that we’ve put some information into our system, let’s add a way to access it!
Adding a GraphQL endpoint
For crafting our GraphQL API, we will use the graphql-ruby gem:
# First, add it to the Gemfile
$ bundle add graphql --version="~> 1.9"
# Then, run the generator
$ rails generate graphql:installYou might be surprised by the number of files a minimal graphql-ruby application requires: this boilerplate is the price we pay for all the goodies we described above.

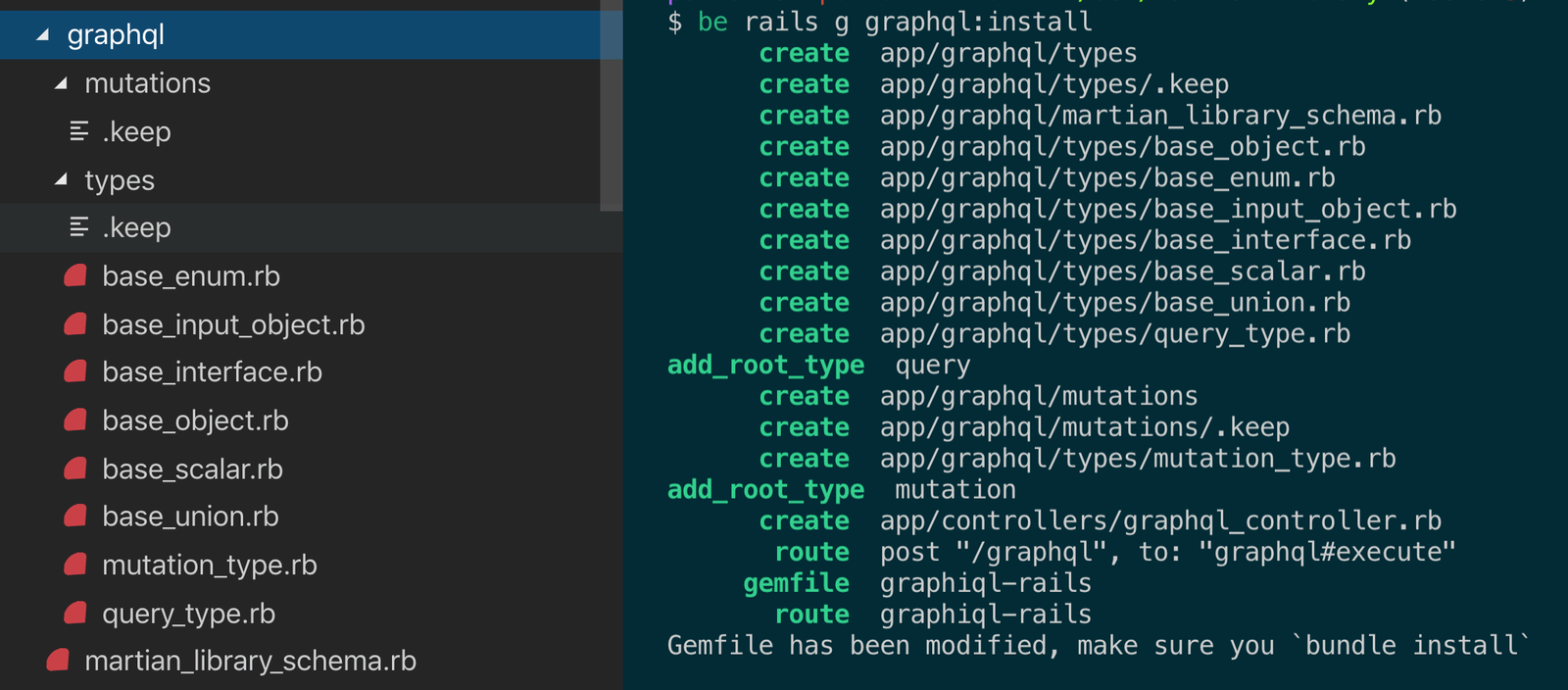
The result of executing graphql:install generator
First of all, let’s take a look at the schema, martian_library_schema.rb:
# app/graphql/martian_library_schema.rb
class MartianLibrarySchema < GraphQL::Schema
query(Types::QueryType)
mutation(Types::MutationType)
endThe schema declares that all the queries should go to Types::QueryType while mutations should go to Types::MutationType. We’re going to dig deeper into mutations in the second part of the series; the goal of this article is to learn how to write and execute queries. Thus, let’s open the types/query_type.rb class—it is an entry point for all the queries. What’s inside?
# app/graphql/types/query_type.rb
module Types
class QueryType < Types::BaseObject
# Add root-level fields here.
# They will be entry points for queries on your schema.
# TODO: remove me
field :test_field, String, null: false,
description: "An example field added by the generator"
def test_field
"Hello World!"
end
end
endIt turns out that QueryType is just a regular type: it inherits from the Types::BaseObject (which we will use as a base class for all types), and it has field definitions—the nodes of our data graph. The only thing that makes QueryType different is that GraphQL requires this type to exist (while mutation and subscription types are optional).
Have noticed that the code above is actually a “hello world” app? Before going further (and boring you with by the amount of code), we’d like to show you how to get this “hello world” in your browser.
Let’s see what has been added to the config/routes.rb file by the generator:
# config/routes.rb
Rails.application.routes.draw do
mount GraphiQL::Rails::Engine, at: "/graphiql", graphql_path: "/graphql" if Rails.env.development?
post "/graphql", to: "graphql#execute"
endMounting GraphiQL::Rails::Engine allows us to test our queries and mutations using a web interface called GraphiQL. As we discussed in the introduction, the schema can be inspected, and GraphiQL uses this feature to build interactive documentation for us. It’s time to give it a shot!
# Let's run a Rails web server
$ rails sOpen up http://localhost:3000/graphiql in the browser:

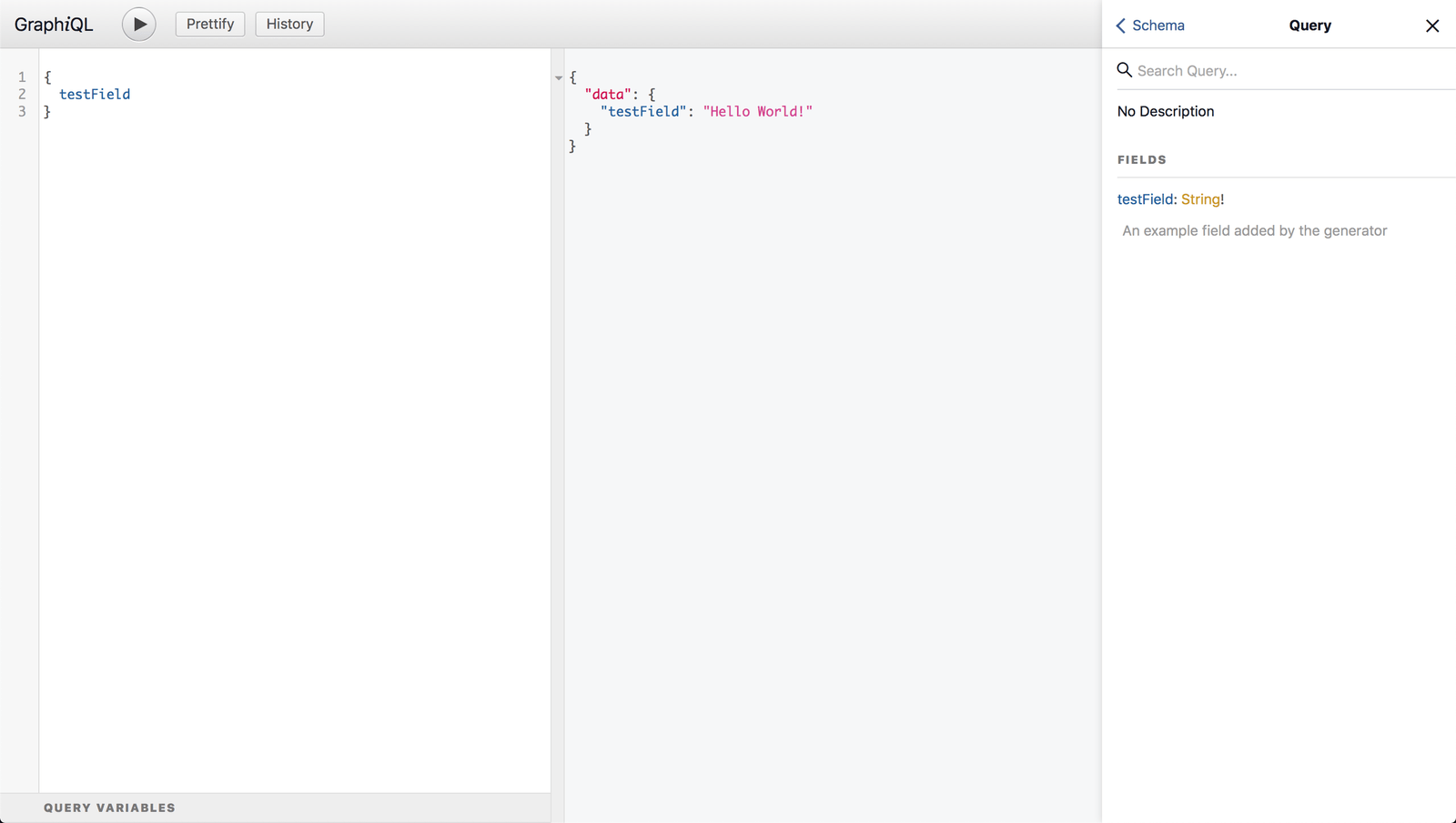
GraphiQL UI
In the left pane, you can type a query to execute, then click the “play” button (or hit Ctrl/Cmd+Enter) and get the response in the right pane. By clicking the “Docs” link at the right top corner, you can explore your schema.
Let’s take a look at our logs—we want to know what happens when we click the execute button.


Execution logs
Requests are sent to GraphqlController, which has also been added to the application by the graphql gem generator.
Take a look at the GraphqlController#execute action:
# app/controllers/graphql_controller.rb
def execute
variables = ensure_hash(params[:variables])
query = params[:query]
operation_name = params[:operationName]
context = {
# Query context goes here, for example:
# current_user: current_user,
}
result = GraphqlSchema.execute(
query,
variables: variables,
context: context,
operation_name: operation_name
)
render json: result
rescue StandardError => e
raise e unless Rails.env.development?
handle_error_in_development e
endThis action calls the GraphqlSchema#execute method with the following parameters:
queryandvariablesrepresent a query string and arguments sent by a client respectively;contextis an arbitrary hash, which will be available during the query execution everywhere;operation_namepicks a named operation from the incoming request to execute (could be empty).
All the magic happens inside this method: it parses the query, detects all the types that should be used for building the response, and resolves all the requested fields. The only thing we need to do is to define the types and declare how fields should be resolved.
What’s in the Martian Library?
Let’s move from “hello world” to something real: remove the example contents from Types::QueryType and register a field called :items which will return all the items from the library. We also need to add a resolver method for this field (the resolver method name must match the field name):
# app/graphql/types/query_type.rb
module Types
class QueryType < Types::BaseObject
field :items,
[Types::ItemType],
null: false,
description: "Returns a list of items in the martian library"
def items
Item.all
end
end
endEach field definition contains a name, a result type, and options; :null is required and must be set to either true or false. We also define optional :description—it’s a good practice to add a human-readable message to a field: it will be automatically added to documentation providing more context to developers. The array notation for the result type, [Types::ItemType], means that the field value must be an array and each element of this array must be represented using the Types::ItemType type.
But we haven’t defined ItemType yet, right? Hopefully, the graphql gem will give us a handy generator:
$ rails g graphql:object itemNow we can modify the newly created app/graphql/types/item_type.rb to our liking.
# app/graphql/types/item_type.rb
module Types
class ItemType < Types::BaseObject
field :id, ID, null: false
field :title, String, null: false
field :description, String, null: true
field :image_url, String, null: true
end
endAs you can see, we’re exposing three fields in ItemType:
- non-nullable fields
idandtitle - a nullable field
description
Our execution engine resolves fields using the following algorithm (slightly simplified):
- First, it looks for the method with the same name defined in the type class itself (like we did earlier in the
QueryTypeforitems); we can access the object being resolved using theobjectmethod. - If no such method defined, it tries to call the method with the same name on the
objectitself.
We do not define any methods in our type class; thus, we assume that the underlying implements all the fields’ methods.
Go back to http://localhost:3000/graphiql, execute the following query, and make sure that you get the list of all items in response:
{
items {
id
title
description
}
}So far, we haven’t added any functionality that leverages the power of graphs—our current graph’s depth is one. Let’s grow the graph by adding a non-primitive node to ItemType, for example, a user field to represent the user who created the item:
# app/graphql/types/item_type.rb
module Types
class ItemType < Types::BaseObject
# ...
field :user, Types::UserType, null: false
end
endLet’s repeat the same generator spell to create a new type class:
$ rails g graphql:object userThis time we also want to add a computed field—full_name:
# app/graphql/types/user_type.rb
module Types
class UserType < Types::BaseObject
field :id, ID, null: false
field :email, String, null: false
field :full_name, String, null: false
def full_name
# `object` references the user instance
[object.first_name, object.last_name].compact.join(" ")
end
end
endLet’s transform our query to fetch users along with items:
{
items {
id
title
user {
id
email
}
}
}At this point, we’re ready to move our attention from the backend side to the frontend side. Let’s build a client for this API!
Configuring the frontend application
As we already mentioned, we recommend you install the Apollo framework for dealing with GraphQL client-side.
To get the ball rolling, we need to install all the required dependencies:
$ yarn add apollo-client apollo-cache-inmemory apollo-link-http apollo-link-error apollo-link graphql graphql-tag react-apolloLet’s take a look at some of the installed packages:
- We use
graphql-tagto build our first queries. apollo-clientis a generic framework-agnostic package for performing and caching GraphQL requests.apollo-cache-inmemoryis a storage implementation for Apollo cache.react-apollocontains a set of React components for displaying data.apollo-linkand other links implement a middleware pattern forapollo-clientoperations (you can find further details here).
Now we need to create an entry point for our frontend application. Remove hello_react.jsx from the packs folder and add index.js:
$ rm app/javascript/packs/hello_react.jsx && touch app/javascript/packs/index.jsFor the sake of debugging, it’s good enough to stay with the following content:
// app/javascript/packs/index.js
console.log('👻');Let’s generate a controller to serve our frontend application:
$ rails g controller Library index --skip-routesUpdate app/views/library/index.html.erb to contain the React root element and a link to our pack:
<!-- app/views/library/index.html.erb -->
<div id="root" />
<%= javascript_pack_tag 'index' %>Finally, let’s register a new route in the config/routes.rb:
# config/routes.rb
root 'library#index'Restart your Rails server and make sure you see the ghost in the browser console. Don’t be scared.
Configuring Apollo
Create a file for storing our application’s Apollo config:
$ mkdir -p app/javascript/utils && touch app/javascript/utils/apollo.jsIn this file we want to configure the two core entities of the Apollo application, the client and the cache (or more precisely, the functions to create both):
// app/javascript/utils/apollo.js
// client
import { ApolloClient } from 'apollo-client';
// cache
import { InMemoryCache } from 'apollo-cache-inmemory';
// links
import { HttpLink } from 'apollo-link-http';
import { onError } from 'apollo-link-error';
import { ApolloLink, Observable } from 'apollo-link';
export const createCache = () => {
const cache = new InMemoryCache();
if (process.env.NODE_ENV === 'development') {
window.secretVariableToStoreCache = cache;
}
return cache;
};Let’s take a second and look at how cache works.
Each query response is put into the cache (the corresponding request is used to generate the cache key). Before making a request, apollo-client ensures that the response hasn’t been cached yet, and if it has been—the request is not performed. This behavior is configurable: for instance, we can turn off caching for a particular request or ask the client to look for a cache entry of a different query.
One important thing we need to know about the cache mechanism for this tutorial is that, by default, a cache key is a concatenation of the object id and __typename. Thus, fetching the same object twice would result only in one request.
Back to coding. Since we use HTTP POST as a transport, we need to attach a proper CSRF token to every request to pass the forgery protection check in the Rails app. We can grab it from meta[name="csrf-token"] (which is generated by <%= csrf_meta_tags %>):
// app/javascript/utils/apollo.js
// ...
// getToken from meta tags
const getToken = () =>
document.querySelector('meta[name="csrf-token"]').getAttribute('content');
const token = getToken();
const setTokenForOperation = async operation =>
operation.setContext({
headers: {
'X-CSRF-Token': token,
},
});
// link with token
const createLinkWithToken = () =>
new ApolloLink(
(operation, forward) =>
new Observable(observer => {
let handle;
Promise.resolve(operation)
.then(setTokenForOperation)
.then(() => {
handle = forward(operation).subscribe({
next: observer.next.bind(observer),
error: observer.error.bind(observer),
complete: observer.complete.bind(observer),
});
})
.catch(observer.error.bind(observer));
return () => {
if (handle) handle.unsubscribe();
};
})
);Let’s look at how we can log errors:
// app/javascript/utils/apollo.js
//...
// log erors
const logError = (error) => console.error(error);
// create error link
const createErrorLink = () => onError(({ graphQLErrors, networkError, operation }) => {
if (graphQLErrors) {
logError('GraphQL - Error', {
errors: graphQLErrors,
operationName: operation.operationName,
variables: operation.variables,
});
}
if (networkError) {
logError('GraphQL - NetworkError', networkError);
}
})In production, it makes more sense to use an exception tracking service (e.g., Sentry or Honeybadger): just override the logError function to send errors to the external system.
We’re almost there—let’s tell the client about the endpoint for making queries:
// app/javascript/utils/apollo.js
//...
// http link
const createHttpLink = () => new HttpLink({
uri: '/graphql',
credentials: 'include',
})Finally, we’re ready to create an Apollo client instance:
// app/javascript/utils/apollo.js
//...
export const createClient = (cache, requestLink) => {
return new ApolloClient({
link: ApolloLink.from([
createErrorLink(),
createLinkWithToken(),
createHttpLink(),
]),
cache,
});
};The very first query
We’re going to use a provider pattern to pass the client instances to React components:
$ mkdir -p app/javascript/components/Provider && touch app/javascript/components/Provider/index.jsIt’s the first time we are using an ApolloProvider component from the react-apollo library:
// app/javascript/components/Provider/index.js
import React from 'react';
import { ApolloProvider } from 'react-apollo';
import { createCache, createClient } from '../../utils/apollo';
export default ({ children }) => (
<ApolloProvider client={createClient(createCache())}>
{children}
</ApolloProvider>
);Let’s change our index.js to use the newly created provider:
// app/javascript/packs/index.js
import React from 'react';
import { render } from 'react-dom';
import Provider from '../components/Provider';
render(<Provider>👻</Provider>, document.querySelector('#root'));If you use Webpacker v3 you may need to import babel-polyfill to use all the cool JavaScript tricks like async/await. Don’t worry about the polyfill’s size; babel-preset-env will remove everything you don’t need.
Let’s create a Library component to display the list of items on the page:
$ mkdir -p app/javascript/components/Library && touch app/javascript/components/Library/index.jsWe’re going to use the Query component from react-apollo, which accepts the query string as a property to fetch the data on mount:
// app/javascript/components/Library/index.js
import React from 'react';
import { Query } from 'react-apollo';
import gql from 'graphql-tag';
const LibraryQuery = gql`
{
items {
id
title
user {
email
}
}
}
`;
export default () => (
<Query query={LibraryQuery}>
{({ data, loading }) => (
<div>
{loading
? 'loading...'
: data.items.map(({ title, id, user }) => (
<div key={id}>
<b>{title}</b> {user ? `added by ${user.email}` : null}
</div>
))}
</div>
)}
</Query>
);We can access the loading state and loaded data through the corresponding loading and data properties (passed using a so-called render-props pattern).
Don’t forget to add the component to the main page:
// app/javascript/packs/index.js
import React from 'react';
import { render } from 'react-dom';
import Provider from '../components/Provider';
import Library from '../components/Library';
render(
<Provider>
<Library />
</Provider>,
document.querySelector('#root')
);If you reload the page you should see the list of items with emails of users who added them:


List of items with emails of users
Congratulations! You’ve just made the very first step towards GraphQL happiness!
…And the very first problem
Everything seems to work fine, but let’s take a look at our server logs:


N + 1
The SQL query SELECT * FROM users WHERE id = ? is executed four times, which means that we hit the famous N+1 problem—server makes a query for each item in the collection to get the corresponding user info.
Before fixing the problem, we need to make sure that it’s safe to make code modifications without breaking anything—let’s write some tests!
Writing some specs
Now it’s time to install and configure RSpec, or more precisely, the rspec-rails gem:
# Add gem to the Gemfile
$ bundle add rspec-rails --version="4.0.0.beta2" --group="development,test"
# Generate the initial configuration
$ rails generate rspec:installTo make it easier to generate data for tests let’s install factory_bot:
$ bundle add factory_bot_rails --version="~> 5.0" --group="development,test"Make factory methods (create, build, etc.) globally visible in tests by adding config.include FactoryBot::Syntax::Methods to the rails_helper.rb.
Since we created our models before adding Factory Bot, we should generate our factories manually. Let’s create a single file, spec/factories.rb, for that:
# spec/factories.rb
FactoryBot.define do
factory :user do
# Use sequence to make sure that the value is unique
sequence(:email) { |n| "user-#{n}@example.com" }
end
factory :item do
sequence(:title) { |n| "item-#{n}" }
user
end
endNow we are ready to write our first test. Let’s create a spec file for QueryType:
$ mkdir -p spec/graphql/types
$ touch spec/graphql/types/query_type_spec.rbThe simplest query test looks like this:
# spec/graphql/types/query_type_spec.rb
require "rails_helper"
RSpec.describe Types::QueryType do
describe "items" do
let!(:items) { create_pair(:item) }
let(:query) do
%(query {
items {
title
}
})
end
subject(:result) do
MartianLibrarySchema.execute(query).as_json
end
it "returns all items" do
expect(result.dig("data", "items")).to match_array(
items.map { |item| { "title" => item.title } }
)
end
end
endFirst, we create a pair of items in our database. Then, we define the query under test and the subject (result) by calling the GraphqlSchema.execute method. Remember, we had a similar line in the GraphqlController#execute?
This example is very straightforward: we’re not passing either variables or context to the execute call, though we definitely can do that if needed.
Now we’re confident enough to fix “the bug”—the N+1 problem!
GraphQL vs. N+1 problem
The easiest way to avoid N+1 queries is to use eager loading. In our case, we need to preload users when making a query to fetch items in QueryType:
# /app/graphql/types/query_type.rb
module Types
class QueryType < Types::BaseObject
# ...
def items
Item.preload(:user)
end
end
endThis solution can help in simple situations, but it’s not very efficient: the following code preloads users even if the client does not need them, e.g.:
items {
title
}Discussing other ways to solve the N+1 problem is worthy of a dedicated post and out of this tutorial’s scope.
Most of the solutions fit the following two groups:
- lazy eager loading (e.g., using the ar_lazy_preload gem)
- batch loading (e.g., using the graphql-batch gem)

That’s all for today! We learned a lot about GraphQL, completed all the routine work of configuring the backend and frontend applications, made the first query, and even found and fixed the first bug. And that’s just a tiny step (despite the size of the article) in our journey. We’ll come back shortly and unveil how to manipulate data using GraphQL mutations and keep it up-to-date with subscriptions. Stay tuned!

