Let there be docs! A documentation-first approach to Rails API development



Translations
- Chinese一种文档优先的Rails API开发方案
In this post, we’ll examine approaches to API documentation, with a case for why the documentation-first approach is beneficial, plus, we’ll not only introduce a new Ruby gem that will be a revelation for those who are ready to follow this path, you can also read on for practical tips and advice for jumping in.
In the beginning, God created the heavens and the Earth.
…and Roy Fielding created the REST.
Despite the existence of more advanced and structured standards like GraphQL and gRPC, we’re still frequently opting for good old REST. The appeal of REST lies in its simplicity and the development freedom it offers.
However, those familiar with REST are well aware of the primary challenge that comes with it: documentation. Yet, effective documentation is vital to have because it serves as a collaboration cornerstone and a definitive guide for both customers and team members interacting with an API.
Consequently, a pressing question arises: what is the most effective approach to documenting APIs? Let’s start by examining a few approaches.
Other parts:
- Let there be docs! A documentation-first approach to Rails API development
- Let there be docs! Generating an OpenAPI schema across the Rails stack
Approaches to API documentation
Manually-written documentation is a straightforward approach where the developer simply describes the implementation after the code has been completed. This might take the form of a page in Notion, or a section in a README file—it doesn’t matter since the resulting documentation is constantly outdated and easily out of sync with the implementation itself.
But all the same, in the end, that approach is just really boring!
Maybe we somehow generate docs from the implementation? A code-first approach involves the usage of DSLs to generate documentation right from API controllers. Here’s an example of a grape resource with the grape-swagger DSL:
class Petstore < Grape::API
desc "Add a new pet to the store", tags: ["Pet"],
http_codes: [
{code: 201, message: "Pet added", model: Api::Entities::Pets}
]
params do
requires :pet, type: Hash do
requires :name, type: String,
documentation: { example: "doggie" }
requires :photo_urls, type: Array[String],
documentation: { example: ["https://example.com/img.json"] }
optional :tags, type: Array[String],
documentation: { example: ["dogs"] }
end
end
post do
spline = Spline.create(spline_params)
present spline, with: Entities::Splines
end
endWith the grape-swagger DSL in place, we can simply call the add_swagger_documentation helper to add always up-to-date documentation to our application.
This approach might look promising, but in actual practice, there are still some downsides:
- Documentation is still only ready after the implementation
- Our controllers are now cluttered with magical, metadata-filled DSL
- Finally, there are no tests in place to assert that the generated documentation is valid
An obvious solution is to shift these DSLs from controllers to tests.
So, here comes the test-first approach. It changes the development flow, and now we can write the tests first and then sprinkle them with some DSLs to generate documentation.
Here’s an example of RSpec with rswag DSL:
require "swagger_helper"
describe "Petstore API" do
path "/pets" do
post "Creates a pet" do
tags "Pet"
produces "application/json"
request_body_example value: {name: "doggie", photo_urls: []}, name: "pet", summary: "Pet"
response "200", "Pet added" do
schema type: :object,
required: ["name", "photo_urls"],
properties: {
name: {type: :string},
photo_urls: {type: :array, items: {type: :string}},
tags: {type: :array, items: {type: :string}},
}
run_test!
end
end
end
endWe now ensure that as long as our tests are accurate, our documentation will be, too.
Yet, despite the fact that the documentation is ready before the implementation, it’s still only read after the tests have been written. The primary issue with both the code-first and test-first approaches is that developers might simply overlook the generated documentation.
And often, this kind of generated documentation is unclear, contains function names instead of descriptions, omits attributes, and other oversights. Generated documentation is treated as just another artifact, but we should care more.
The documentation-first approach
Here we come to the documentation-first approach. This switches the developer focus to crafting detailed documentation before starting to write code. And while we’re calling it “documentation-first”, actually referring to it as a “schema-first” or even “specification-first” approach would also be appropriate for this method, since the resulting document is not just some documentation, but a comprehensive specification.
In any case, this opens a lot of possibilities: developers can not only generate documentation, they can also test the application against the specification, validate incoming requests, use mocks and code generators, and so on.
Using this approach also allows us to enhance the development workflow: a developer can first draft a specification, discuss it with the team, and ensure the API meets all necessary requirements. Next, they can add tests to confirm that the specification works as intended, and finally, implement the API. (The last two steps can be swapped depending on your preference for a TDD approach.)
Let’s summarize the documentation-first approach:
- It doesn’t use any DSLs, making the resulting documentation readable and editable by anyone in the team.
- Further, the documentation is ready before the implementation or the tests, so developers can get feedback earlier.
- Finally, the documentation itself acts as a specification.
The documentation-first approach stands out as the most effective and collaborative method for API development.
The only downside is that documentation-first approach might require a shift in workflow for some teams.
Now, let’s see that approach in action.
Documentation-first: an illustrated example
The first step is to choose a specification format, and while there are many options, OpenAPI is the most popular one, and could arguably be considered the de-facto standard.
To learn more about OpenAPI, consider checking out the Petstore API. It’s a great example of a well-documented API using OpenAPI, and while it’s commonly used for demos and examples, it’s a bit overcomplicated for our purposes. So instead, let’s take a look at the “Noah’s Ark API”.
Here’s the situation: so, let’s assume we’ve already implemented some features, like a simple CRUD, for dealing with the animals present (or not) on the Ark—and we’ve been flooded with positive responses from users!
Thus, our happy stakeholder—the CEO of the Ark—comes to us with a new feature request: implementing a feed feature. This request is somewhat vague, and unfortunately, the CEO is swamped with other tasks and so they can’t address our questions immediately. This means we’ll need to come up with something first on our own.
I suspect that the CEO of the Ark wants to create a feed similar to X/Twitter! A place where the animals can get into verbal scuffles other online, instead of within the real life holds of the Ark itself. We’ll take this as a reasonable assumption since, of course, these days, social networks are popping up like mushrooms after rain. So let’s describe this feature with OpenAPI!
OpenAPI
Let’s start with the minimal valid OpenAPI document:
openapi: 3.1.0
info:
title: Noah's Ark API
version: 1.0.0
paths: {}Now, unfortunately, explaining every keyword and feature of OpenAPI would take forever, and it’s also not the point of this article, so let’s dig in just deep enough to understand how it looks and feels.
Next, we’ll add three requests for our new Feed feature:
paths:
"/feed":
get:
summary: Get a list of messages
operationId: getFeedMessages
post:
summary: Add a new message to the feed
operationId: postFeedMessage
"/feed/{message_id}":
get:
summary: Get a message by id
operationId: getFeedMessageIt’s a great idea to describe requests in this manner, going from top to bottom and adding more details with each next step.
Now let’s zoom in on one particular path:
paths:
"/feed":
get:
summary: Get updates about the animals
operationId: getAnimalsFeed
responses:
"200":
description: OK
content:
application/json:
schema:
type: array
items:
type: object
required: [id, animal_id, message]
properties:
id:
type: integer
format: int64
animal_id:
type: integer
format: int64
message:
type: string
"403":
description: ForbiddenAt this step, we just added a description for a successful response. Note the schema keyword, and the fact that, inside of it, OpenAPI uses a different specification: JSON Schema. This can be used to validate JSON even outside OpenAPI, and it’s a great tool; it’s really readable and easy to understand, but it’s a bit verbose. To fix that, we can use references:
paths:
"/feed":
get:
summary: Get updates about the animals
operationId: getAnimalsFeed
responses:
"200":
description: OK
content:
application/json:
schema:
type: array
items:
$ref: "#/components/schemas/FeedItem"
components:
schemas:
FeedItem:
type: object
required: [id, animal_id, message]
properties: #...Here, we’re referencing a local component in this document, but it’s also possible to reference external files or OpenAPI descriptions, so we can avoid dealing with, you know, thousands lines of code files.
Next, we can iterate on this specification, adding more and more keywords and features until we’re satisfied with the result. And once we’re done with the specification, we can leverage the OpenAPI ecosystem.
OpenAPI Ecosystem
Writing specification in YAML might seem painful (and it is at first), so here are couple ways to make developer lives less miserable:
- Swagger Editor: a web based application which can be embeded into your application in development environment for example.
- Redocly VSCode Extension: a Visual Studio Code extension from Redocly.
Both can help with autocompletion, previews and much more.
No doubt, as a professional Ruby developer, you use RuboCop daily, but do you lint your OpenAPI documents? If not, you should. And Spectral is way to go. Even if you use code-first or test-first approaches, adding Spectral to your workflow will elevate your documentation:
❯ spectral lint docs/openapi.yml
/noahs_ark/docs/openapi.yml
3:6 warning info-contact Info object must have "contact" object. info
16:5 warning tag-description Tag object must have "description". tags[1]
26:9 warning operation-operationId Operation must have "operationId". paths./animals.get
✖ 3 problems (0 errors, 3 warnings, 0 infos, 0 hints)For more rules and examples see Spectral rulesets.
With the OpenAPI specification ready, the frontend team can start implementing their part of the feature using mock servers, like Prism:
❯ prism mock docs/openapi.yml
[1:49:35 PM] › [CLI] ▶ start Prism is listening on http://127.0.0.1:4010
[1:49:47 PM] › [HTTP SERVER] get /animals ℹ info Request received
[1:49:48 PM] › [NEGOTIATOR] ℹ info Request contains an accept header: */*
[1:49:48 PM] › [VALIDATOR] ✔ success The request passed the validation rules. Looking for the best response
[1:49:48 PM] › [NEGOTIATOR] ✔ success Found a compatible content for */*
[1:49:48 PM] › [NEGOTIATOR] ✔ success Responding with the requested status code 200
[1:49:48 PM] › [NEGOTIATOR] ℹ info > Responding with "200"❯ curl http://127.0.0.1:4010/animals
[{"id":0,"name":"Polkan","species":"dog","sex":"male"}]❯ curl -X POST http://127.0.0.1:4010/animals \
-H "Content-Type: application/json" \
-d '{"name":"Polkan","species":"dog","sex":"male"}'
{"id":0,"name":"Polkan","species":"dog","sex":"male"}Furthermore, the frontend team can enhance type safety using openapi-typescript, which converts the OpenAPI specification into TypeScript types:
> npx openapi-typescript docs/openapi.yml -o app/javascript/api/schema.d.ts
🚀 docs/openapi.yml → app/javascript/api/schema.d.ts [39ms]Taking automation a step further, the openapi-fetch library allows for the dynamic generation of API clients based on the OpenAPI specification. This eliminates the need to manually code API clients, saving time and reducing development overhead:
import createClient from "openapi-fetch";
import type { paths } from "./api"; // generated by openapi-typescript
const client = createClient<paths>({ baseUrl: "https://noahs.ark" });
const {data, error} = await client.GET("/animals/{animal_id}", {
params: {
path: { animal_id: "0" },
},
});
await client.POST("/animals", {
body: {
name: "Sea-Tac Airport Facebook YouTube Instagram Snapchat",
species: "cat",
sex: "female",
},
});This level of automation greatly simplifies the development workflow, letting the frontend team focus on building robust, type-safe applications with less concern about the underlying boilerplate code for API interactions.
And finally, the whole team can leverage beautiful documentation generators like Swagger UI, Elements, Redoc:

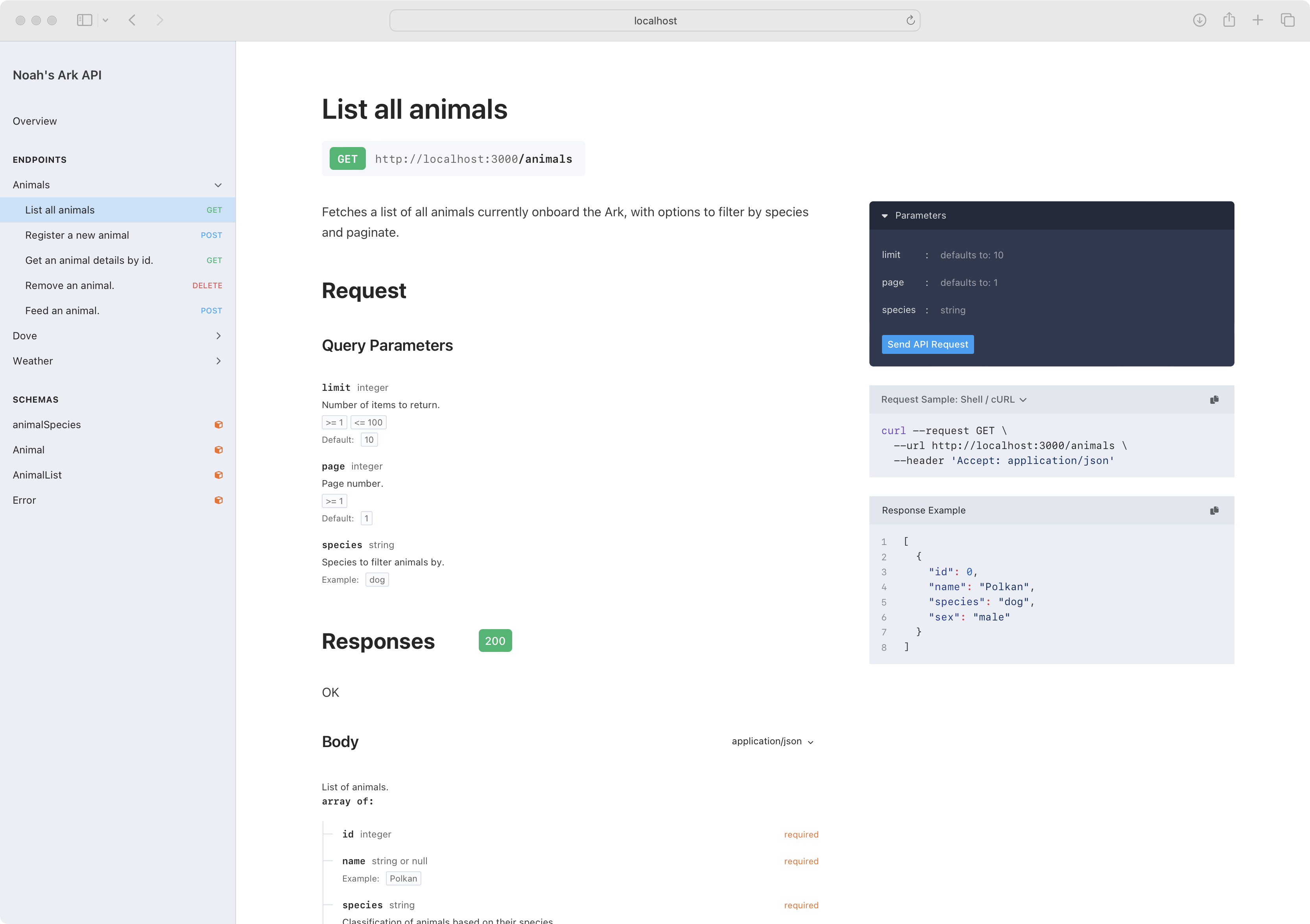
Collaboration
But the most important tool is collaboration within the team between the frontends, analytics, stakeholders, and so on. And with a documentation-first approach it’s now easy to discuss and improve the feature with them.
By the way, now when we have edited, linted, and rendered documentation, let’s show it to the CEO of the Ark.
“Awesome work, but I wanted to feed the animals…
…NOT an ‘Animals’ Feed!”
Yikes, it seems we misunderstood the requirements, and to be honest, this kind of misunderstanding happens all the time in software development. But isn’t that great that we’ve switched to a documentation-first approach? We didn’t implement anything yet and aos we got the necessary feedback earlier. Now, we can just re-iterate on the documentation and make it work this time.
Now, let’s assume we did just that and our new documentation is ready and approved, so we’ve just completed the two first steps of the documentation-first approach workflow. Next, we’re going to add tests to confirm the specification and implement the API.
With that, allow me to a introduce a gem that will help us with that workflow: Skooma.
Skooma
Meet Skooma! This is a gem for validating API implementations against OpenAPI documents. It supports the latest OpenAPI 3.1 and JSON Schema Draft 2020-12, comes with RSpec and Minitest helpers out of the box, and finally it comes complete with a cool name referencing The Elder Scrolls games!
To configure Skooma with RSpec we only need to specify the documentation path and include Skooma into request specs:
# spec/rails_helper.rb
RSpec.configure do |config|
# ...
path_to_openapi = Rails.root.join("docs", "openapi.yml")
config.include Skooma::RSpec[path_to_openapi], type: :request
endNow, we can access OpenAPI document via skooma_openapi_schema helper, and, for example, validate it against the OpenAPI specification:
# spec/openapi_spec.rb
require "rails_helper"
describe "OpenAPI document", type: :request do
subject(:schema) { skooma_openapi_schema }
it { is_expected.to be_valid_document }
endJust like that, we can now be sure that our OpenAPI document is always valid. But the most important thing is that we can now validate our endpoints with these helpers:
conform_request_schema– validates the request path, query, headers, and bodyconform_response_schema(status)– validates the response status, headers, and body (testing error responses)conform_schema(status)– validates both the request and response (happy path testing)
Here is a full example of a vanilla request spec with Skooma in use (there is no magic DSLs, only a couple of helpers):
# spec/requests/feed_spec.rb
require "rails_helper"
describe "/animals/:animal_id/feed" do
let(:animal) { create(:animal, :unicorn) }
describe "POST" do
subject { post "/animals/#{animal.id}/feed", body:, as: :json }
let(:body) { {food: "apple", quantity: 3} }
it { is_expected.to conform_schema(200) }
context "with wrong food type" do
let(:body) { {food: "wood", quantity: 1} }
it { is_expected.to conform_schema(422) }
end
end
endAnd that’s it! Just imagine validating all those attributes manually with plain Ruby. That’s how Skooma saves time and makes your tests more readable! By the way, we just entered the Red Green Refactor cycle:
Validation Result:
{"valid"=>false,
"instanceLocation"=>"",
"keywordLocation"=>"",
"absoluteKeywordLocation"=>"urn:uuid:1b4b39eb-9b93-4cc1-b6ac-32a25d9bff50#",
"errors"=>
[{"instanceLocation"=>"",
"keywordLocation"=>
"/paths/~1animals~1{animalId}~1feed/post/responses/200"/
"/content/application~1json/schema/required",
"error"=>
"The object is missing required properties"/
" [\"animalId\", \"food\", \"amount\"]"}]}
# ./spec/requests/feed_spec.rb:12:in `block (3 levels) in <top (required)>'Skooma, alongside a documentation-first approach, enables the TDD way to the perfect API implementation, ensuring that each feature is working according to the specification.
And that’s it, and with that, the rain is cleaning and we’re ready to settle back on dry ground, in a new land without poor documentation!
Tips and tricks
Start small. It’s okay to begin with a documentation-first approach for just one endpoint. Once you and your team become comfortable with it, you can expand this approach to the entire API. For those transitioning from a code-first or test-first approach, generating an OpenAPI document from your existing code can serve as a solid starting point to shift towards a documentation-first approach.
Add Spectral to your CI/CD pipeline. Once you’ve did this, start using custom linter rules to enforce your API design. For example, you can use rules for specific error responses, or say, pagination, to ensure that they are consistent across your API. There are also real-world examples of Rulesets available in the Spectral documentation. You can use these as a reference to learn more about Spectral.
Read the JSON Schema keywords specs to level up your validations. For example, there is the unevaluatedProperties keyword which can be used to avoid exposing internal attributes to end users:
type: object
unevaluatedProperties: false
properties: # ...Just add this to your schemas and you’ll be sure that your API is safe. You can even use custom linter rules to enforce it.
Use a documentation-first approach to enable collaboration and early feedback. Collaboration is the key to successful development, reduce unneeded iterations on implementation and by parallelize work of multi-functional teams.
Use OpenAPI to write specification, so you and your team have all speak one language. Improve your documentation with linters and tools from OpenAPI ecosystem.
And finally, use Skooma to test your application against the OpenAPI document and save time and effort making your code and tests more readable and API more stable.
I hope you liked this approach, and you too can now proclaim:
“Let there be docs” …and there will be docs!

At Evil Martians, we transform growth-stage startups into unicorns, build developer tools, and create open source products. If you’re ready to engage warp drive, give us a shout!
