Martian Kubernetes Kit: running apps—and running them well


Topics

This is part 3 of the “Martian Kubernetes Kit” series, our Kubernetes-based infrastructure we developed for our clients drawn from years of experience. Now, it’s time for stuff to get real, for the rubber to meet the road–in other words, to move your app into the kit. After all, all of this infrastructure ultimately exists to serve one purpose: running our clients’ apps–and running them well!
Other parts:
- Martian Kubernetes Kit: a smooth-sailing toolkit from our SRE team
- Martian Kubernetes Kit: unboxing our toolkit's technical secrets
- Martian Kubernetes Kit: running apps—and running them well
As a refresher, in the first installment, we explained some of the basics of Martian Kubernetes Kit and why you’d want a solution like this in the first place. Then, in part two, we went deeper into the technical nuts and bolts by revealing some of our decision-making processes we went through while crafting the kit.

Irina Nazarova CEO at Evil Martians
From infrastructure to real application deployment
In this article, we’ll talk about the process of deploying and managing a real-world application on a Kubernetes cluster: configuring deployment pipelines, handling secrets, Helm Chart hints, and more configuration insights–we’ll break down the steps and tools for a smooth, scalable application management. (And in part 4, we’ll have even more fun when we talk about preview apps!)
A quick recap on our example app
If we’re really going to get a good look at how Martian Kubernetes Kit works in practice, we’ll need to have some kind of example application to show off its capabilities. Luckily, we already fleshed that out in a previous article, but nevertheless, let’s quickly recap here:
- We have a thoroughly-prepared Kubernetes cluster
- It’s being completely managed by Argo CD, with a full configuration, stored and versioned in Git
- We also have a ton of helpful tools at our disposal: a monitoring stack, an external secrets operator, and so on.
Beyond that, (for the sake of brevity) let’s go ahead and assume we’ll be working with a typical modern web application. This application might consist of multiple components: a web worker, queue worker, Cron tasks, or one-time jobs.
Perhaps we might add AnyCable, with its WebSocket and RPC services (or add anything else). At this point, we’d already have about 5 components.
Perfect! With our infrastructure and example application defined, we can now focus on what matters most: getting an application running smoothly across all environments.
A brief note about Helm charts
Helm charts are so popular and they are indeed a solid default choice if you don’t know otherwise. And so, naturally we chose Helm to package our application. This means it’s impossible not to mention something about it here. Still, the full coverage regarding the dark arts of writing and utilizing Helm charts is beyond the scope of this text.
Let’s reap the most crucial insights from our experience:
- Our main recommendation: make the Helm chart that will manage your particular application as configurable as the situation requires, and adapt it to your needs accordingly.
- Bitnami’s common Helm chart allows us to reuse some code and to make sure the chart is predictable for other SRE engineers – this helps us be prepared to transition the infrastructure to a client’s team or another team.
- A wise starting place for storing your Helm chart is inside the application code itself. This means it’s constantly tracked and remembered during the deployment process and evolves with your application.
- For up-to-date info, we recommend reading as many popular Helm charts from Artifact Hub as possible. For example, here’s a solid pick: Bitnami’s!
Regarding that last point, keep in mind these Bitnami charts were made to be utilized by users from across the entire internet. So, they almost certainly will be orders of magnitude more configurable and complex than your own project’s Helm chart needs.
Adding the applications to the cluster
OK, enough about Helm charts, let’s get back to the topic at hand. Preparations are complete, we have an application, and we have a Helm chart. Now, it’s time to instruct Argo CD to take matters into its own hands.
Just as the client-infrastructure repository references the core of the Martian Kubernetes Kit, we can now add a reference to the Helm chart we have for the application and make Argo CD deploy it (to the desired environment).
Let’s note that there are a number of ways we can arrange the Argo CD configuration to manage our application.
For now, we’ll focus on the most straightforward option: just a single infrastructure repository for everything.

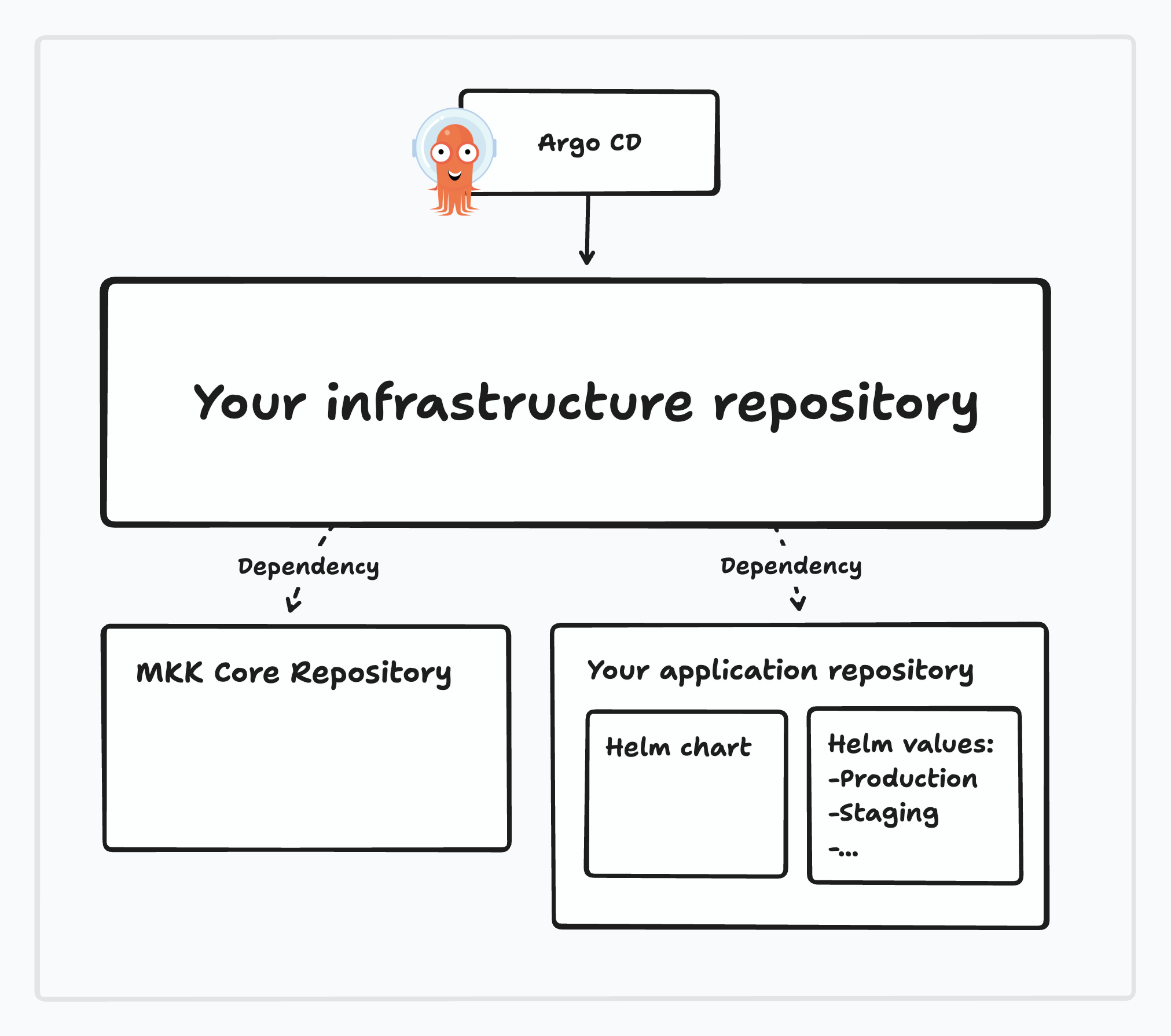
If you have to comply with stricter security rules–or if you just have a way bigger setup–it may be advisable to isolate your configurations for your application in a separate repository. This will allow you to better control access to the whole cluster configuration versus the application configuration itself.

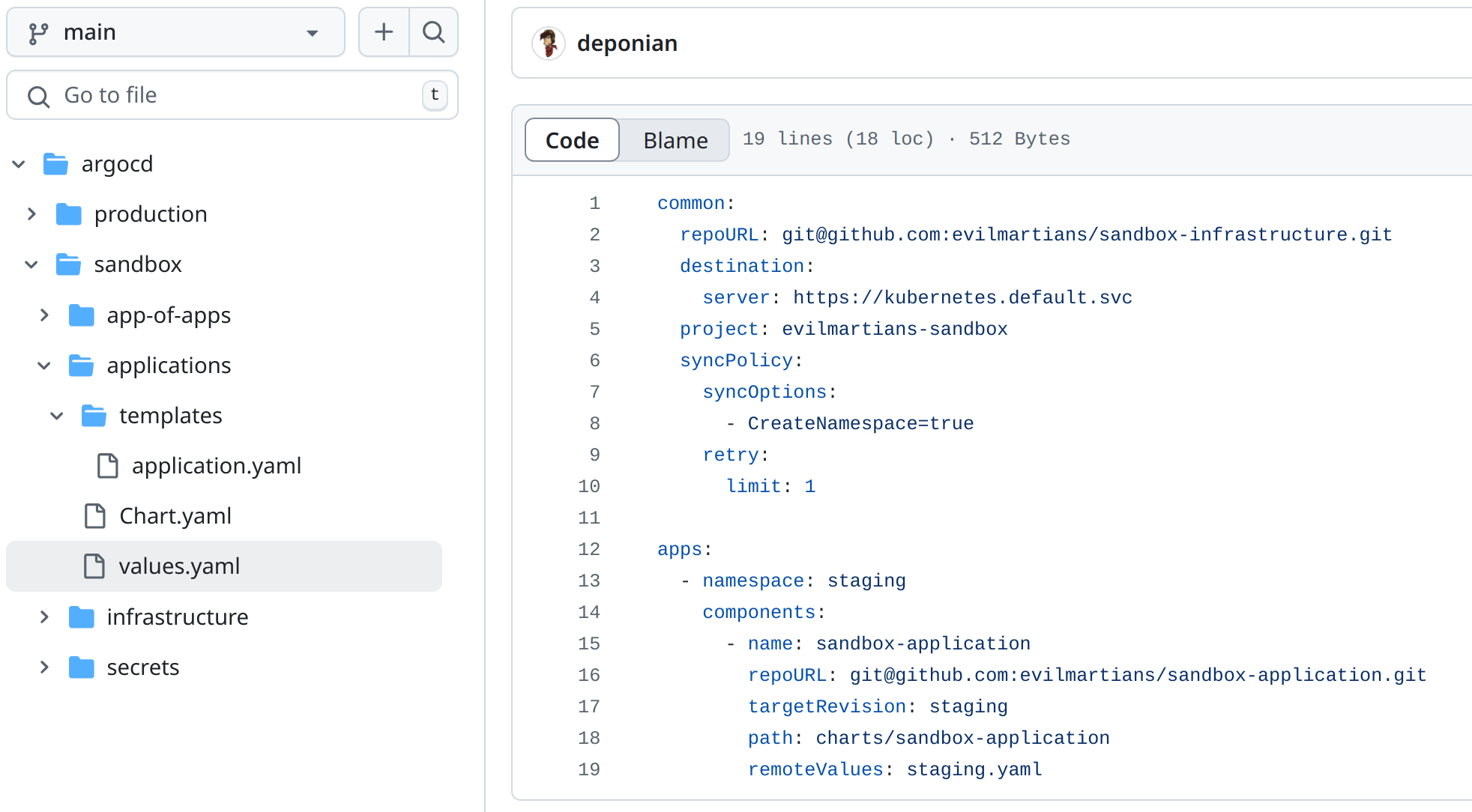
This configuration instructs Argo CD roughly as follows:
- Our application lives in the
evilmartians/sandbox-applicationrepository, where Argo CD has to select the staging branch and to read the chart at the pathcharts/sandbox-application. - The Helm values for this application should be taken from the
staging.yamlfile in the same directory of the chart.
That last step is very useful because storing values in the application repository is much more convenient than using the general client-infrastructure repository. This is for several reasons:
- Developers have full and transparent control over the parameters of the deployed application.
- Values are versioned along with the application.
- You can always run
helm installif needed, e.g. for a local test withminikube. - You can store configurations for different environments in different files, e.g. one for production, one for staging, and so on.
However, all that said, whenever a project reaches a certain size, you probably don’t want it so that it’s any of just an old developer with access to the code to be able to influence the infrastructure. In this scenario, some (or all) of the values can be moved to an infrastructure or a specific application configuration repository that only a select few people can access.
So, keeping configuration values for your application in a repository is really handy, but what about secrets, which aren’t so safe to keep out in the open? Let’s tackle that next.
The challenge of managing secrets
Our application, its Helm chart and values are nicely trackable via Git and all quite understandable. But, much like people, every modern application has some secrets, and we have to manage them, right? So, here’s what makes our life harder:
- First of all, application secrets …have to be secret.
- They cannot be stored unencrypted alongside the code.
- They can differ depending on the application environment–and we cannot just create a single blob of secrets for all environments at once because this is not secure.
Now, one might just say, “OK, that’s not so bad! We can just create some encrypted files and call it a day”.
But wait, there’s a bit more to that:
- To start, these files have to be editable without jumping through a bunch of flaming hoops to decrypt/encrypt local files (a process which reduces security and increases the chances of human error).
- Preferably, secrets should only be locally accessible for selected developers.
- And, at the end of the day, they have to be versioned and tracked by some tool. (Imagine a situation where you’ve changed a secret and now the application fails–you need to roll back the entire application, but it also has to be able to automatically access the older version of those secrets. Yikes!)
That means you have to use some external service to store your secrets.
How to manage external secrets?
External secrets are a relatively simple concept to grasp: you simply do not save your secrets inside the place where your application lives. Instead, you keep them on some remote server, while only a reference to the remote secret is saved within your values.
So, how does an application access a secret then? There are two main ways to make this happen:
- Your application can directly access the remote secrets store on its own.
- Or, you could run a separate helper, which connects to the secret’s storage, gets the secret data and converts it to something your application can utilize.
The first option is way more secure and more convenient. However, if your application wasn’t originally developed with support for external secrets in mind, that means you’ll have to invest some time, effort, money, (as well as blood, sweat, and perhaps tears) in order to add that functionality.
(Incidentally, most of the applications we encounter in our work fall into this category, and it’s often quicker and easier to implement the second option, so let’s move on to that one now.)
In terms of helpers, there are a number of different secret storages available. If you’re using Google Cloud, their Secret Manager is there for you. AWS has its own Secrets Manager, too. On the other hand, if you want to manage the whole process from start to finish and keep secrets on your own servers, you can opt for Hashicorp Vault. In short, there are options here, although there are some differences to keep in mind.
External secrets made easy: the Martian Kubernetes Kit way!
Fortunately, we don’t have to worry about the differences between these different providers, because our Martian Kubernetes Kit uses External Secrets Operator. It supports a number of providers and allows us to ask for secrets in a similar way, regardless of the backend!
But how does it work? Operator accesses your external secret storage, extracts the secrets by name and version, and creates a corresponding Kubernetes secret inside the Kubernetes cluster. Then, later on, we can use this secret as secretRef in envFrom field of application’s manifest.
By using this approach, we check off all the aforementioned requirements:
- We keep our secret data safe.
- It’s versioned.
- All modern secret storages provide us with an interface to edit secrets (and you’re not required to encrypt/decrypt some local files manually).
Here’s an example of this kind of secret:
apiVersion: external-secrets.io/v1beta1
kind: ExternalSecret
metadata:
name: example
spec:
# how frequently to go to provider and check for changes
refreshInterval: "0"
# provider credentials
secretStoreRef:
name: secretstore-sample
kind: ClusterSecretStore
# Kubernetes secret that will be created
target:
name: secret-to-be-created
creationPolicy: Owner
# external secret name and version to fetch your data from
dataFrom:
- extract:
key: the-name-of-the-secret-in-the-store
version: secret-versionSo, here’s what’s happening:
- We instruct External Secrets Operator (ESO) to get an exact version of some secret data from an external secret named
the-name-of-the-secret-in-the-store - We instruct ESO to store that data into the Kubernetes secret named
secret-to-be-created - ESO should use “credentials” configured in the ClusterSecretStore named
secretstore-sample - ESO should not update that secret automatically (no need as we inted to reference the exact version)
Now, our manifests from our Helm chart can refer to this new secret-to-be-created Kubernetes secret to get the actual secrets to the app securely. Now, let’s move to the actual deployment process where we use it.
The Martian Kubernetes Kit deployment process
So, we’ve figured out how to safely avoid all of the common pitfalls and we’re finally ready for our application to be deployed–it’s time to bring a CI/CD tool into the mix!
Today, there are a significant number of modern CI/CD tools available. An in-depth selection process of a CI/CD solution is beyond the scope of this post. That said, most, if not all, will suffice for the sake of deploying your application the way we suggest.
Our go-to CI/CD system is GitHub Actions, and the majority of our clients (and our own projects) are already hosted on GitHub anyway. (Plus, GitHub Actions has matured over the years and now has a huge community with thousands of supported actions in its marketplace.)
Our CI/CD process is practically the classic and familiar setup, but with one new addition: push → test → build → get-secret → deploy.

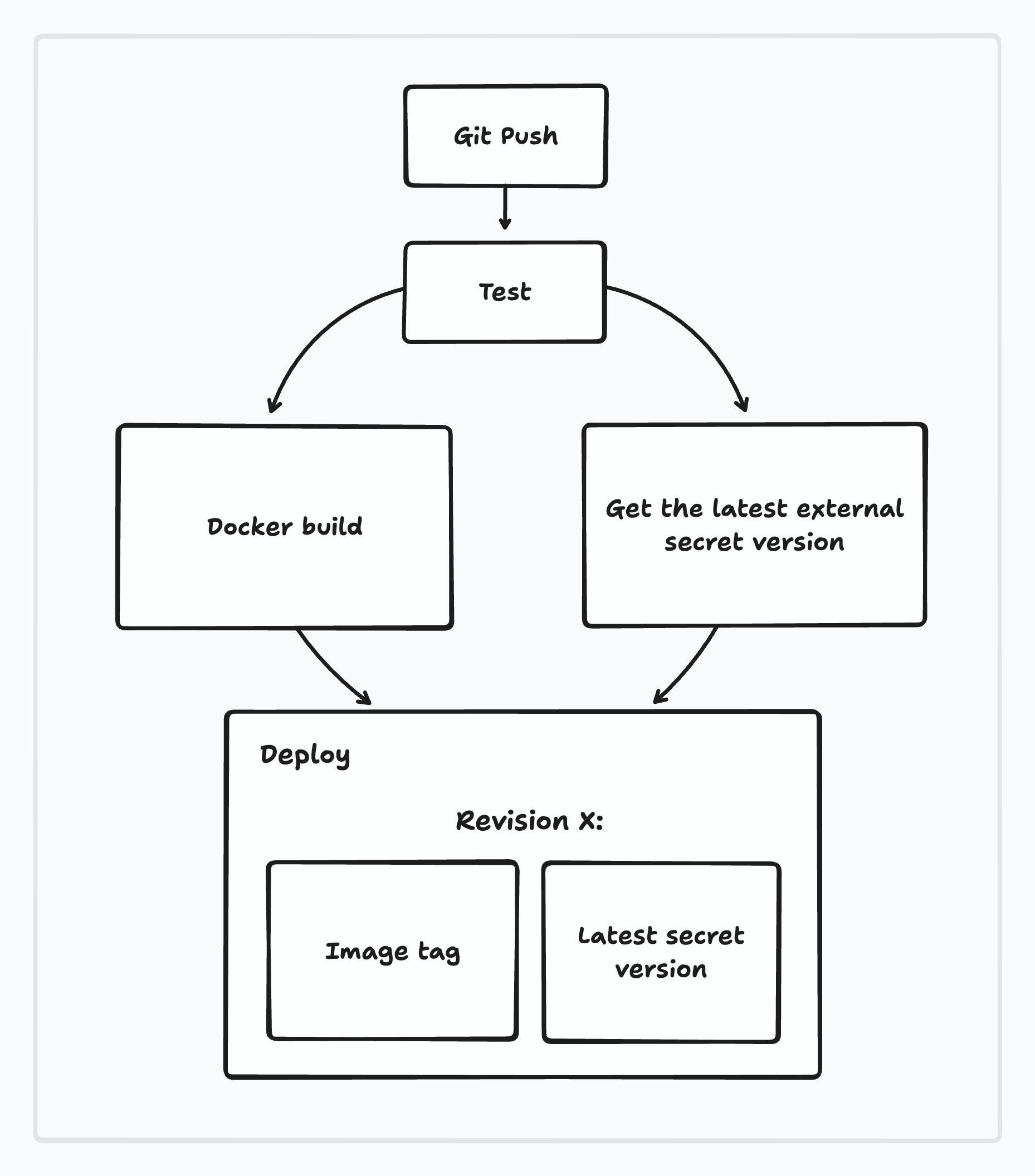
In our case, the app deployment is essentially a set of two values: the image version and the external secret version. Our main goal is to pass Argo CD both of these and it will take care of the rest.
(As you will shortly see, we’re relying on reusable workflows. The workflow takes input parameters via inputs which are used in the subsequent steps in order to switch environments and as variables within commands. This approach is extremely handy because we can re-use the same steps for any number of environments by simply changing the input variables.)
First up, getting the secrets
The workflow code below looks extremely long for the task it performs, which is the commands on two last lines. This gets the latest version of our secret stored (in this case) in GCP Secret Manager–but it obscures one important thing:
Specifically, we do NOT want to use labels like latest (or AWSCURRENT in the case of AWS). This is so that each deployed revision has a full, specific version of that secret assigned.
---
# This is [R]eusable [W]orkflow.
# You can't run it directly.
# It's intended to be called from other workflows.
# See for more details:
# https://docs.github.com/en/actions/using-workflows/reusing-workflows
name: "[RW][GCP] Get latest version of secret form GCP Secret Manager"
on:
workflow_call:
inputs:
environment:
type: string
description: "Environment to deploy to"
required: true
external-secret-name:
type: string
description: "External secret name"
required: true
outputs:
version:
description: "Latest version of the secret"
value: ${{ jobs.get-secret.outputs.version }}
permissions:
id-token: write
contents: read
defaults:
run:
shell: bash
env:
APP_EXTERNAL_SECRET_NAME: ${{ inputs.external-secret-name }}
jobs:
get-secret:
name: Get latest version of secret
runs-on: ubuntu-24.04
environment: ${{ inputs.environment }}
outputs:
version: ${{ steps.get.outputs.version }}
steps:
- name: Check out repository
uses: actions/checkout@v4
- id: auth
name: Authenticate to GCP
uses: google-github-actions/auth@v2
with:
create_credentials_file: 'true'
workload_identity_provider: ${{ secrets.GCP_WORKLOAD_IDENTITY_PROVIDER }}
service_account: ${{ secrets.GCP_SERVICE_ACCOUNT_EMAIL }}
- name: Set up Cloud SDK
uses: 'google-github-actions/setup-gcloud@v2'
- name: Get current external secret version
id: get
run: |
SECRET_VERSION=$(gcloud secrets versions describe latest --secret ${APP_EXTERNAL_SECRET_NAME} --project=${{ vars.GCP_PROJECT }} --format="value(name)" | awk -F"/" '{print $NF}')
echo "version=${SECRET_VERSION}" >> $GITHUB_OUTPUTAt long last, deployment
Next, let’s have a look at something more interesting – an example workflow describing the deployment process:
---
# This is [R]eusable [W]orkflow.
# You can't run it directly.
# It's intended to be called from other workflows.
# See for more details:
# https://docs.github.com/en/actions/using-workflows/reusing-workflows
name: "[RW][SHARED] Deploy to Kubernetes cluster"
on:
workflow_call:
inputs:
environment:
type: string
description: "Environment to deploy to"
required: true
commit-sha:
type: string
description: "Commit SHA"
required: true
external-secret-name:
type: string
description: "External secret name"
required: true
external-secret-version:
type: string
description: "External secret version"
required: true
argocd-app-name:
type: string
description: "Argo CD application name"
required: true
permissions:
id-token: write
contents: read
actions: read
defaults:
run:
shell: bash
env:
APP_EXTERNAL_SECRET_NAME: ${{ inputs.external-secret-name }}
APP_EXTERNAL_SECRET_VERSION: ${{ inputs.external-secret-version }}
ARGOCD_APPLICATION: ${{ inputs.argocd-app-name }}
jobs:
deploy:
name: Deploy
runs-on: ubuntu-24.04
environment: ${{ inputs.environment }}
timeout-minutes: 10
steps:
- name: Check out repository
uses: actions/checkout@v4
- name: Authenticate to Google Cloud
id: auth
uses: google-github-actions/auth@v2
with:
workload_identity_provider: ${{ secrets.GCP_WORKLOAD_IDENTITY_PROVIDER }}
service_account: ${{ secrets.GCP_SERVICE_ACCOUNT_EMAIL }}
- name: Set Kubernetes context
uses: google-github-actions/get-gke-credentials@v2
with:
cluster_name: ${{ vars.GKE_CLUSTER_NAME }}
location: ${{ vars.GKE_CLUSTER_LOCATION }}
- name: Install Argo CD
uses: clowdhaus/argo-cd-action@v2.2.0
with:
version: ${{ vars.ARGOCD_VERSION }}
- name: Change app image and external secret version
run: |
argocd login --username ${{ vars.ARGOCD_USER }} --password ${{ secrets.ARGOCD_PASSWORD }} --grpc-web ${{ vars.ARGOCD_URL }}
argocd app set --helm-set image.tag=${{ inputs.commit-sha }} ${ARGOCD_APPLICATION}
argocd app set --helm-set externalSecret.name=${APP_EXTERNAL_SECRET_NAME} ${ARGOCD_APPLICATION}
argocd app set --helm-set externalSecret.version=${APP_EXTERNAL_SECRET_VERSION} ${ARGOCD_APPLICATION}
- name: Sync application
id: sync
run: |
argocd app sync --prune --async ${ARGOCD_APPLICATION}
- name: Wait for full sync
id: wait
run: |
kubectl wait --for=jsonpath='{.status.sync.status}'=Synced -n argocd applications.argoproj.io/${ARGOCD_APPLICATION} --timeout ${{ vars.ARGOCD_SYNC_TIMEOUT }}s
kubectl wait --for=jsonpath='{.status.sync.revision}'=${{ inputs.commit-sha }} -n argocd applications.argoproj.io/${ARGOCD_APPLICATION} --timeout ${{ vars.ARGOCD_SYNC_TIMEOUT }}s
kubectl wait --for=jsonpath='{.status.operationState.phase}'=Succeeded -n argocd applications.argoproj.io/${ARGOCD_APPLICATION} --timeout ${{ vars.ARGOCD_SYNC_TIMEOUT }}s
kubectl wait --for=jsonpath='{.status.health.status}'=Healthy -n argocd applications.argoproj.io/${ARGOCD_APPLICATION} --timeout ${{ vars.ARGOCD_SYNC_TIMEOUT }}s
- name: Rollback if sync fail
if: failure() && steps.sync.outcome == 'failure'
run: |
set +e argocd app terminate-op ${ARGOCD_APPLICATION}
argocd app rollback --prune ${ARGOCD_APPLICATION}Both tag and the external-secret-version are generated by previous reusable workflows before the deployment process starts. This way we always know which secret data corresponds to which deployment, and we can make sure Argo CD is able to roll-back to any previous application revision seamlessly.
When application values are updated with a new tag and a secret version, we can finally synchronize these changes to the Kubernetes cluster. Plus, if something goes wrong during this process, it will trigger an optional rollback step that will return the application to its previous state.
As mentioned above, you can easily manage multiple application instances simultaneously with reusable workflows. Just call them with an appropriate set of input values and you’re good to go. Here’s an example for deploying a separate staging environment using the code from above:
---
name: "Deploy app"
on:
push:
branches:
- staging
workflow_dispatch:
jobs:
build:
name: Staging
uses: ./.github/workflows/gcp-build.yml
with:
environment: staging-gcp
commit-sha: ${{ github.sha }}
secrets: inherit
get-secret-version:
name: Staging
uses: ./.github/workflows/gcp-get-external-secret-version.yml
with:
environment: staging-gcp
external-secret-name: staging-${{ vars.APP_NAME }}-env-vars
secrets: inherit
deploy:
name: Staging
needs:
- build
- get-secret-version
uses: ./.github/workflows/deploy-plain.yml
with:
environment: staging-gcp
commit-sha: ${{ github.sha }}
external-secret-name: staging-${{ vars.APP_NAME }}-env-vars
external-secret-version: ${{ needs.get-secret-version.outputs.version }}
argocd-app-name: staging-${{ vars.APP_NAME }}
secrets: inheritThe main variable here is environment: it switches between the configured GitHub Actions Environments and changes the values for the variables and secrets which are unique to each environment.
In effect, this means that the value of vars.ARGOCD_URL from the deployment workflow above will be different for production and staging. Of course, we can always change values for all variables and secrets by navigating to the Settings → Environments page in the repository
Preview apps
Traditionally, developers often relied on two main environments: production (for the live product) and staging (for final testing before production). However, limiting to only these two environments can hinder flexibility and efficiency.
We can significantly increase the development process efficiency and decrease any given feature’s time-to-production by increasing the number of testing grounds. Instead of waiting for a single staging environment to become free, each feature branch can and should be tested in its own isolated preview app.
Multiple preview apps promote better collaboration across teams. Developers, QA testers, and designers can work in tandem, each testing specific features independently without needing to coordinate or wait for one another.
And you know what? We set up Martian Kubernetes Kit with exactly this idea in mind. And in part 4, the final part of our series, that’s exactly what we’ll discuss. Stay tuned!