Power for Kadenze: More performance, less cloud costs



The Kadenze project is a perfect showcase of the eLearning platform that was lucky to face performance challenges due to a growth in demand—not because of technical imperfection. Martians had to be fast and furious to help the platform scale swiftly, saving up to 25% on cloud infrastructure along the way.
Kannu is the Kadenze, Inc.’s flagship learning management system (LMS) that powers the digital learning experiences of schools, institutions, and companies all over the world. Kannu is also the core of kadenze.com, an online course platform focused on art, music, and creative technology courses from world-renowned schools like Stanford University, Princeton University, UCLA, Columbia, and many others. As the entire educational system was forced into the futuristic virtual reality overnight due to COVID-19, Kannu and kadenze.com experienced a dramatic influx of new users, exposing the need for immediate performance optimizations.
The performance challenge
Kadenze’s tech stack is based on a Ruby on Rails application deployed to the Amazon Web Services cloud. While the in-house engineering team was focusing on product development, the project needed a hand in managing the increased load—and here came Martians, with an exceptional background in Rails performance and the record of dozens of speed troubleshooting projects.
A small crew of Martians jumped in to help on the same day as Jordan Hochenbaum, the CTO of Kadenze, had contacted us.
Only a week after, the situation improved significantly: we reduced the average service web response time by 76%, bringing it from 500+ milliseconds to less than 200 milliseconds.
For users, it means popular scenarios like visiting a homepage to start a new course do not feel sluggish anymore; in fact, most of the application’s “golden paths” are now significantly faster. For Kadenze engineers, the quicker response from the servers means fewer resources to allocate even when the influx of visitors stresses the workloads.
Oil the Rails
Over the years, Martians mastered the art of speeding up Rails applications. So, like in the majority of our performance projects, we started with monitoring.
We carefully examined the existing monitoring metrics by setting up in-depth custom dashboards—in this case, with New Relic—to determine and separate the parts that needed to be “cured.” The problem of redundant database calls is a typical diagnosis for large Rails applications, and Kadenze wasn’t an exception. By adding caching and eliminating N+1 queries, we managed to cut the number of database calls per request by up to 95% in critical areas. The app could breathe normally again.

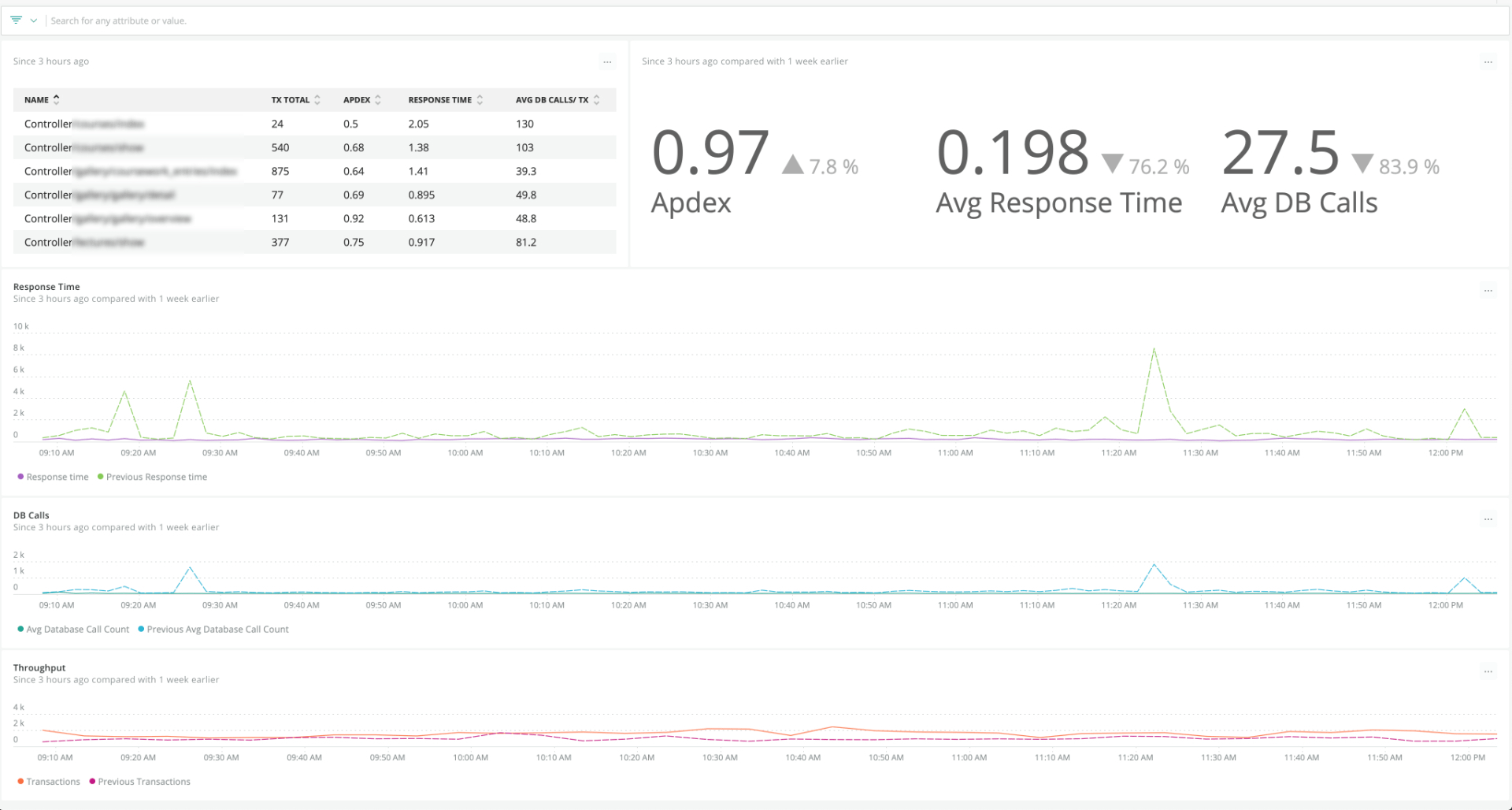
Average response time decrease after the Martian intervention
Finally, we’ve added not one but two cherries on top. First, with the help of TestProf, our open source performance analyzer for Ruby tests, we could cut the time to run tests by half.
Learn more about TestProf—a bag of powerful tools to diagnose all test-related problems—in our blog: TestProf Part I and TestProf Part II.
Secondly, we have implemented a full local Docker setup to simplify the onboarding of new team members so they can bootstrap their development environments instantly. Besides, a single Docker container keeps all the Kadenze engineers’ development environments in sync.
Saving a quarter
The next vital business challenge that Kadenze set for Martians was to reduce the Amazon Web Services cloud infrastructure cost. The goal was to save up to a quarter of current expenses.
Decimating infrastructure costs is a familiar task for Martians. In most cases, startups have plenty of room for expenses optimization but a lack of system or cloud architecture resources prevents them from implementing it. Besides, it’s a common situation when a project has to scale promptly due to growth in demand. There are typically several directions for cost-cutting: improving the application performance and reworking its infrastructure—or reconfiguring the cloud environment by spinning more virtual machines and services.
In this project with Kadenze, we did both. First, we’ve optimized the instance sizes of the application. We’ve discovered that the app was using just about 10% of allocated resources for some instances, so we adjusted the instance configuration to match the real needs. Secondly, we have updated the cloud infrastructure: by migrating the app from two separate ECS clusters (one for web and for background tasks) to a single one. Then, we switched to a compute savings plan that included AWS service settings configuration and getting an Amazon 20% discount for capacity reservation for over a year.
As a result, we have achieved 25% savings and drew up the resources consumption report with some recommendations for Kadenze to continue their cloud optimization.
Teaming up
None of that could have been possible without outstandingly open and prompt communication and generous support of Kadenze’s core tech team. This perfect match helped the project to find all the solutions and implement them in time.
Some problems are good ones to have, but when customer experience is involved, it’s crucial to get ahead of them. Working with the Martians on this unique situation, we were able to do just that. They came in, they rolled up their sleeves, and they delivered. We loved working with them and will continue to do so because, well, they are simply the best at what they do.

Jordan Hochenbaum
Kadenze, Inc., CTO

Are you enjoying the same explosive growth but struggling with relevant side effects in your Rails application? Get in touch to receive recommendations on how to boost your performance and reduce expenses for your cloud infrastructure.