Realtime text analysis with Word Tagger: pro computer vision, part 1



In this series, I would like to share my experience working with computer vision. To do that, we’ll play with an example application that can recognize the English-language text of a recipe using the mobile camera and which can then convert this information into a set of class objects. And all of this will be happening right on the device in real-time! 🕶️
At some point, you’ve probably used applications which leverage computer vision to recognize text within images. This is most often found in online translators or simple text scanners. In the latter part of 2021, the mobile world got a big jolt of energy in this area: with the release of iOS version 15.0, Apple added Live Text to the native camera app, allowing for instant text recognition, and letting users seamlessly interact with any text, links, and phone numbers that appear inside their images.
Other parts:
- Realtime text analysis with Word Tagger: pro computer vision, part 1
- Realtime text analysis with Word Tagger: recipe reader, part 2
This basic functionality—reading text from a picture—no longer surprises anyone. But what if we wanted to go further and be able to turn recognized words and characters into a set of class objects? This would allow us to format the original text in whatever way we might need: we could rearrange parts of the sentence, remove extra words, or add missing ones.

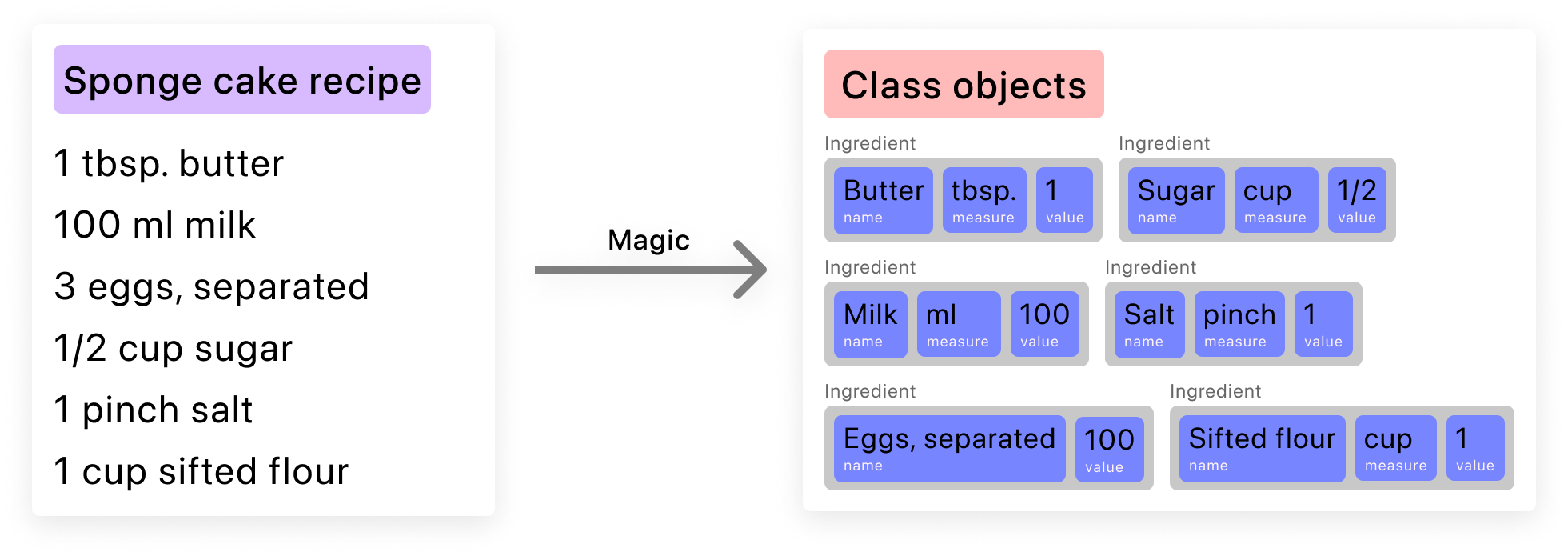
It might seem like a complicated task, but not to fear, machine learning comes to the rescue again! Fortunately for us, Create ML’s templates include the Word Tagger model, which allows us to mark individual words and phrases in a natural language text. Perfect for achieving our goal!

Our goals
We want to end up with something that works like this:
To implement our Recipe Reader, we’ll progress through several stages:
- Actually training the model
- Implementing a mobile application capable of recognizing a text from a video stream
- Converting the resulting text into an array of objects using the Word Tagger model
In the first part of the series, we’ll cover how the Word Tagger model works, prepare the raw data, write a program in Xcode Playground to generate a dataset from the raw data, and then we’ll train our model.
Understanding the Word Tagger model’s requirements
But, before we get too far ahead of ourselves, it’s important to better understand how the Word Tagger works and its data requirements. Let’s take a simple example and imagine that our task is to take a sentence and find any planet names within it. 🪐
To create and train the model, we’ll need a JSON file, which takes the following structure:
[
{
"tokens" : ["Uranus", "and", "Neptune", "look", "alike", "."],
"labels" : ["planet", "none", "planet", "none", "none", "none"]
},
{
"tokens" : ["Earth", "comes", "third", "."],
"labels" : ["planet", "none", "none", "none"]
},
{
"tokens" : ["Welcome", "to", "Mars", "!"],
"labels" : ["none", "none", "planet", "none"]
}
]The JSON is composed of an array of objects, where each object has two necessary fields:
tokens: an array of words, collocations, and punctuation markslabels: an array of tags corresponding to eachtokensarray element
❗️It’s important that the length of both arrays match!
Since we only want to find planet names, the elements in the labels set have been given the “planet” tag, while all other elements have the “none” tag.
Simply put, to create a Word Tagger model, we need a sentence set with real-life, natural-sounding examples where each word will have its own corresponding tag. Sounds easy enough, right? But there’s a catch! In this case, we’d need a giant dataset—the larger the better! The recipes we see below are fairly small with some discernible patterns, but imagine if we had a 20-word sentence where the word “Saturn” was in the 17th position.
Complicating this task is the fact that the planet names can be placed almost anywhere in a sentence, as well as the fact that the number of words in a particular sentence is not limited. Further, we’d need to find all possible combinations of these words in our sentences. 😅
So, for the purposes of our demonstration, let’s look at our—slightly—more manageable task for now.
Dealing with the main task
The primary objective of our demo project is to recognize and parse recipe text. We need to figure out what it takes to create our dataset from scratch. To get the best result, we’ll need to carefully analyze a sufficient number of real-life examples. This process will entail collecting data requirements for training, and will help find common features of recognizable texts, as well as edge cases.
🗒️ The first thing to note is that most recipes are written as a list, where each line contains information about one ingredient—for our purposes, each of these lines can be considered as a sentence. This means that the recognized text will be a list of elements (sentences) that we’ll pass to our Word Tagger model for processing.


Mmm… sounds delicious. 🤤
Analyzing them a bit, it seems that each line always consists of several elements, written in a certain order, as demonstrated in the picture below:


But actually, this is misleading. I was able to find at least 4 notations for recording ingredient information. The main distinction relates to the number of elements and the order in which they are presented:


Key points:
- A string can only consist of the ingredient name.
- A given measure may be missing.
- Numerical values and measures may be combined (like
0.5tbspin the example above). Such cases occur quite often and we’ll treat them in a special way. - Ingredient names and measurements do not always consist of one word, and, at times, processing methods are indicated. (We see this below with “clean water, boiled”.) In this case, we’ll include the processing method to the name of the ingredient.


- Measures can have different notation options. They can come in abbreviated forms (with and without a dot) or plural forms. All this must be taken into account when creating a dataset:


- The same can be said about numerical values. For example, fractional numbers can be written in a variety of ways: separated by a dot, a slash, or a comma:


Finding data to train our model
At first glance, it might seem that the variety of possible values is too large to even work with! Well, yes, there is indeed a large variety of ingredient types in the world, but, nevertheless, this data pool is still limited. Don’t panic—just relax! 🧘 For now, we’ll deal with the sources of raw data together and prepare everything necessary to create our dataset.
I managed to find a set of ingredient names on Kaggle. The resource is open and unlicensed, so we can use it for our project. It’s a JSON file that contains 6714 unique items.
It was not possible to find a ready-made measurement dataset. However, this is fairly easy to make on your own. To do this, I analyzed a number of resources that describe possible measurement values and took into account the various notation options that were described in the previous section of this article.
Next, based on this data, take a look at the program code I created using Xcode Playground. In particular, note the getMeasures method, which generates the measure set. Please note that the various variations of fluid ounces are placed in another array, because they consist of two words, unlike the other examples:
func getMeasures() -> [WordObject] {
var measures = ["tbsp", "tbsp.", "tablespoon", "tablespoons", "tb.", "tb", "tbl.", "tbl", "tsp", "tsp.", "teaspoon", "teaspoons", "oz", "oz.", "ounce", "ounces", "c", "c.", "cup", "cups", "qt", "qt.", "quart", "pt", "pt.", "pint", "pints", "ml", "milliliter", "milliliters", "g", "gram", "grams", "kg", "kilogram", "kilograms", "l", "liter", "liters", "pinch", "pinches", "gal", "gal.", "gallons", "lb.", "lb", "pkg.", "pkg", "package", "packages","can", "cans", "box", "boxes", "stick", "sticks", "bag", "bags"]
measures += ["fluid ounce", "fluid ounces", "fl. oz"].flatMap { Array(repeating: $0, count: 10) }
return measures.map { WordObject(token: $0, label: .measure) }.shuffled()
}We’re touching on something important here: the concept of a pattern! As it learns, the Word Tagger model deals not only with values and labels, but the order and occurrence count of words in a sentence, thus, it can make correct predictions for examples not in the training set. Don’t worry that some existing values will be absent in the final JSON.
Let’s get back to fluid ounces: these are the only units of measurement that consist of two words. Initially, there are only 3 items: fluid ounce, fluid ounces, and fl. oz. The pattern that these measurements follow (consisting of two words) is rarely found amongst the majority of one-word measurements. If nothing is done to account for this, then, when generating a dataset, the count of examples with fl. oz. will be relatively small. For this reason, I have increased the count of fl. oz up to 10 copies. This will allow us to add more examples of this type to the JSON file, and as a result, our ML model will be better able to handle such cases:
measures += ["fluid ounce", "fluid ounces", "fl. oz"].flatMap { Array(repeating: $0, count: 10) }Let’s move on to the getValues method, which generates a numerical value set. As much as I could, I strove to take exactly the kinds of values which could be found in real-life examples: fractional numbers with different notations, integers from 1 to 9, and integers from 10 to 1000 with a step of 25:
func getValues() -> [WordObject] {
var values: [String] = [
"1/2", "1/3", "1/4", "1/5", "2/3", "3/4",
"0,25", "0.25", "0,5", "1,5", "0.5", "1.5", "2.5", "2,5",
"1", "2", "3", "4", "5", "6", "7", "8", "9"
]
values += values.flatMap { Array(repeating: $0, count: 2) }
values += (10 ... 1000).filter { $0 % 25 == 0 }.map { String($0) }
return values.map { WordObject(token: $0, label: .value) }.shuffled()
}I also increased the number of fractional examples to match the number of integer examples:
values += values.flatMap { Array(repeating: $0, count: 2) }Dataset preparation
Now, let’s figure out how to turn our raw datasets into JSON that’s ready to be used to train models. I’m quite confident you can (or have already) figure out the program code on your own. 💪
Still, below I’ll try to describe the most important points you’ll need to make sure and implement. The code for this program should do the following:
- Convert JSON with ingredient names into a set of unique values, and prepare units of measurement and numerical values.
- Make a set of proposals, taking into account all the nuances described in the Dealing with the main task section of this article.
- Save the resulting JSON file to disk.
Pay attention to the getIngredients method, which parses the JSON we found on Kaggle. Initially, this file consists of a list of objects, where each object is a recipe describing the required ingredients. Some positions may be repeated. There are 39774 ingredient names in this file, but only 6714 of these are unique values. To obtain only the unique ingredient names from the entire list without any extra effort, we use the Set data structure:
return Set(jsonArray.flatMap { $0.ingredients }).map {
return WordObject(token: $0, label: .ingredient)
}Up next is the generateSentences method, which combines 3 sets of data (values, measures, and ingredients) into real sentences. Take a look at the code below. Going through all the ingredient names, the program comes up with 4 different types of sentences, which we also touched in the Dealing with the main task section:
func generateSentences(ingredients: [WordObject], measures: [WordObject], values: [WordObject]) -> Set<[WordObject]> {
var measureIndex = 0
var valueIndex = 0
var isFirstWay = true
return ingredients.reduce(into: Set<[WordObject]>()) { sentences, ingredient in
if measureIndex == measures.count {
measureIndex = 0
}
if valueIndex == values.count {
valueIndex = 0
}
let measure = measures[measureIndex]
let value = values[valueIndex]
measureIndex += 1
valueIndex += 1
let token = value.token + measure.token
let combination = WordObject(token: token, label: .combination)
if isFirstWay {
sentences.insert([value, ingredient]) // 10 sugar
sentences.insert([combination, ingredient]) // 10tbsp sugar
} else {
sentences.insert([ingredient]) // sugar
}
sentences.insert([value, measure, ingredient]) // 10 tbsp sugar
isFirstWay.toggle()
}
}I would also like to say a bit more about the isFirstWay variable. With it, I decided to balance the dataset in such a way that the number of sentences which consist of the three main parts we’re concerned about (value, measure, and ingredient) prevailed. In my opinion, this is the most common type of sentence we deal with. Therefore, in the code, you may notice that such examples are generated in each reduce method iteration, while sentences of different types are created during each second iteration.
And, do you remember how I talked about situations where ingredient names or measures might consist of several words? Of course, we could pass entire compound strings for training, using one measure or ingredient label for all the words in a collocation, like so:


But, through my own experiments, I have found that this isn’t the right approach to take. Instead, a better option is splitting the elements so that each word has its own label:


In a JSON file, the different variations would look like this:
[
{
"tokens" : ["2", "fl. oz", "sharp cheddar cheese"],
"labels" : ["value", "measure", "ingredient"]
},
{
"tokens" : ["2", "fl.", "oz", "sharp", "cheddar", "cheese"],
"labels" : ["value", "measure", "measure", "ingredient", "ingredient", "ingredient"]
}
]To make this efficient, I wrote the separateCollocations method, which splits collocations into separate words, where the separating element is space:
func separateCollocations(in sentences: Set<[WordObject]>) -> [SentenceObject] {
return sentences.compactMap { sentence in
let sentenceObject = SentenceObject()
sentence.map { word in
word.token.split(separator: " ").map { part in
let newToken = String(part)
sentenceObject.tokens.append(newToken)
sentenceObject.labels.append(word.label)
}
}
return sentenceObject
}
}This collocation splitting improves the accuracy of the model. To confirm this theory, I ran two experiments based on the two approaches described above. In the image below, you can see that whenever we use one label for the entire phrase, the model cannot distinguish between the measurement and the ingredient name.


Finally, in order to make sure that we’ve fully absorbed the algorithm for training JSON data, I propose to go over it in its entirety one more time:


Training the model
With the dataset preparation complete, let’s move on to the next step of this lovely process: training. For training, we’ll need three JSON files: the first file is for training (train), the second for validation (valid), and the third for testing (test). Each file will consist of 16785 elements. Our script program always shuffles the initial values. This means that every time it is run, a file is created containing random combinations. At the end of program execution, the new JSON file path will be displayed in the console.
If you need it, here’s the pre-generated data.
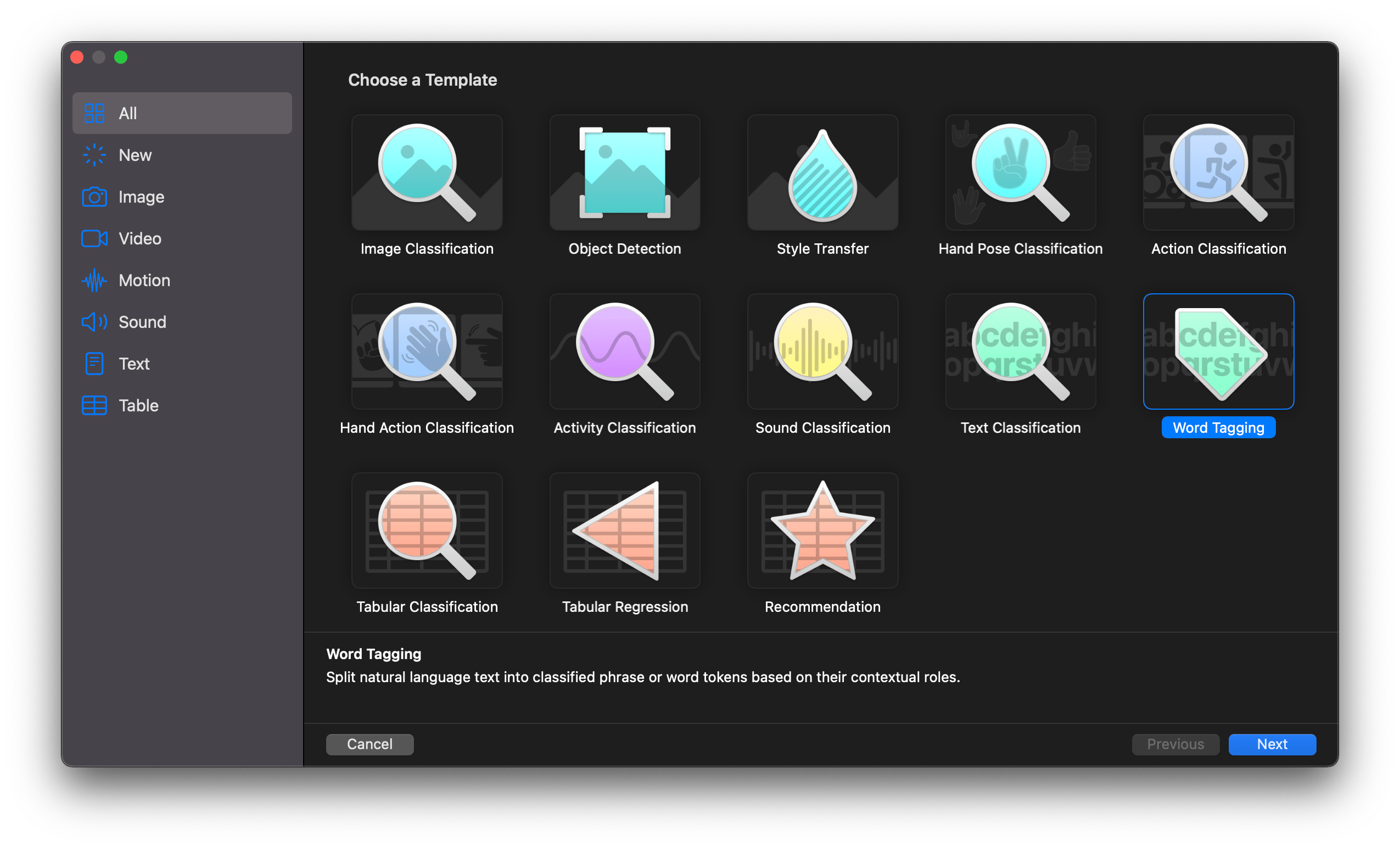
Enough talk, let’s move on to training our model! 🤫 First, let’s create a new project in Create ML using the Word Tagger template.

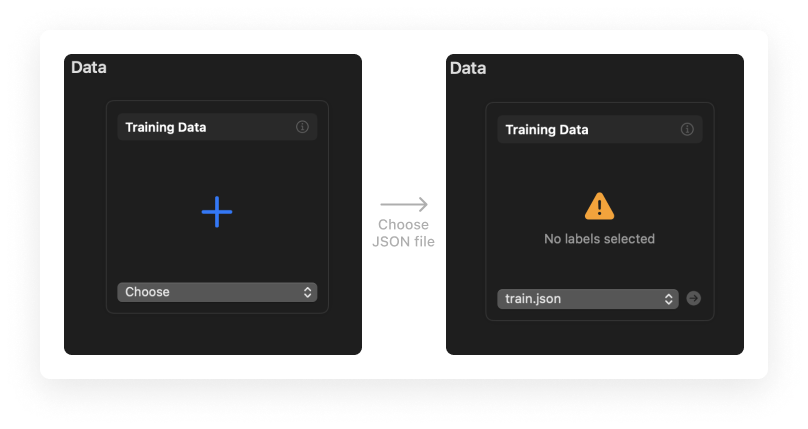
In the Training data section, use the context menu called Choose (or the (+) button, or drag-and-drop the file) and load the training JSON file.

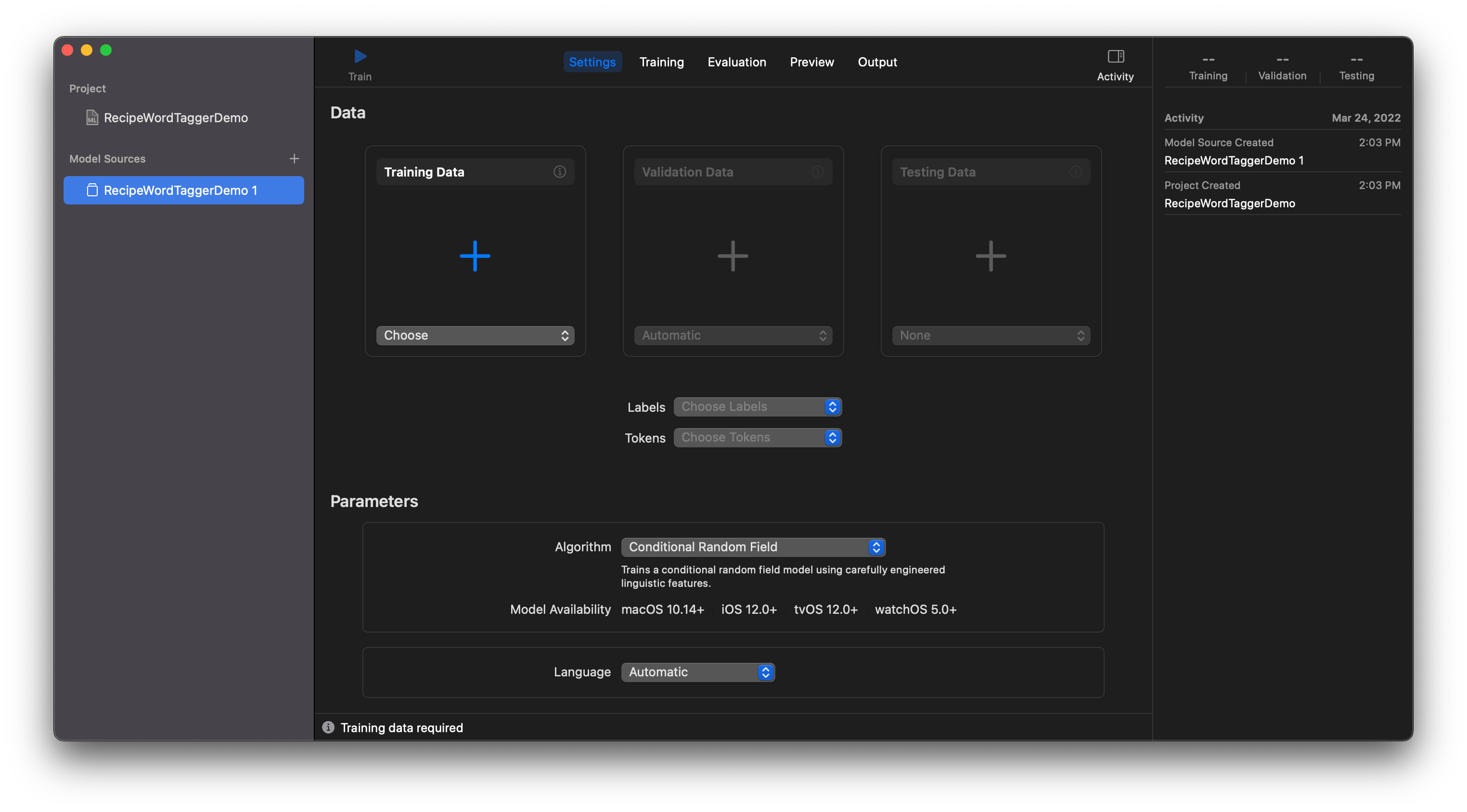
Create ML prompts you to choose values for the Labels and Tokens fields. This can be done using the corresponding context menus in the middle of the screen. Next, the program prompts us to take a part of the data from the Train set to generate the validation set. But, in this case, we’ve already prepared two special sets: Valid and Test. Add data for validation and testing to the project. Select the English language using the context menu below.

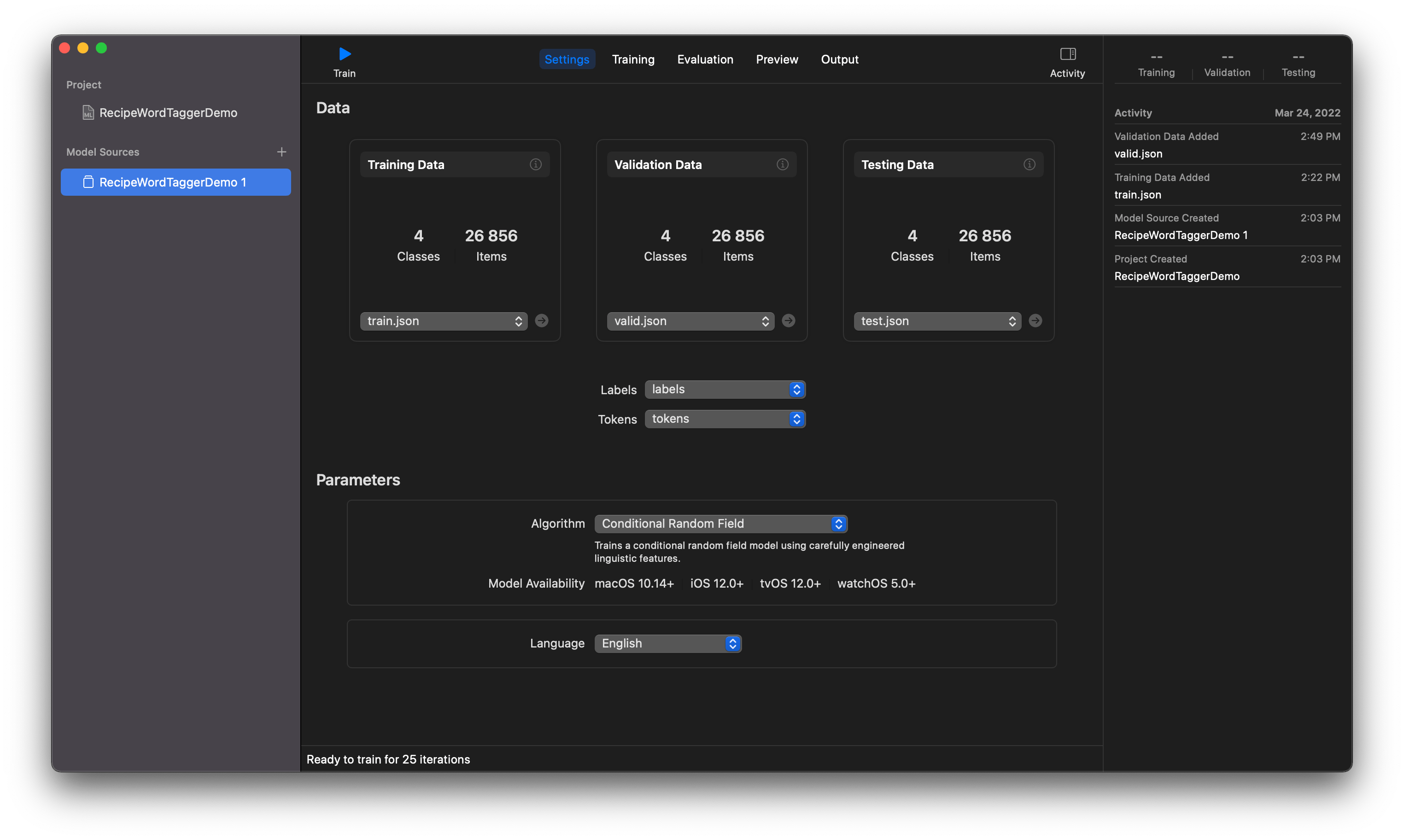
Before starting Word Tagger training, the model asks us to choose one of two algorithms.
Option 1: Conditional Random Field (CRF) is a sequence modeling algorithm used to identify entities or patterns in text. This model not only assumes that features are dependent on each other but also considers future observations while learning a pattern. In terms of performance, it’s considered to be the best method for sequence recognition.
Option 2: I talked about the Transfer Learning method in the second part of my article Object Detection with Create ML. When using this method, the Word Tagger model training takes much longer than with CRF, and the file size can be 3 times larger.

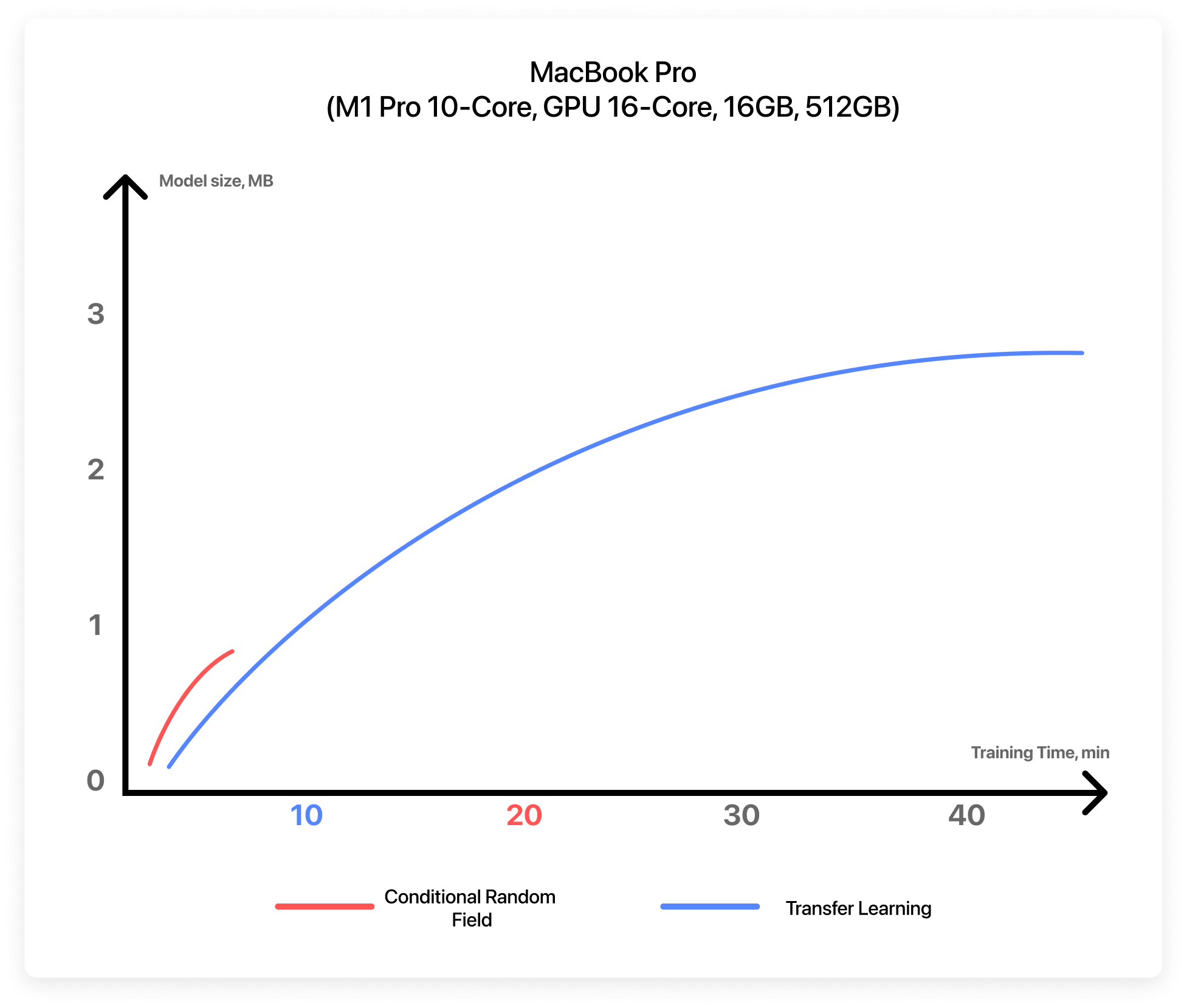
The final choice of the algorithm may depend on your specific goals. For example, if you need to implement text recognition for an application that must support iOS version 12.0+, then you have only one option—the CRF algorithm. And it’s good to keep in mind that none of the available algorithms guarantee 100% efficiency.
For our project, we’ll use a model created with the Conditional Random Field algorithm to support iOS 13. Moreover, after doing a lot of experiments with different datasets, I’ve found the CRF algorithm performs better with those examples which were not included in the original dataset.
After choosing an algorithm, press the Train button and wait for the training to complete. As mentioned, on the Preview tab, you can test the performance of the model. To export a model file, go to the Output tab. Then click the Get button and save the model to disk.
Conclusion
So, let’s summarize what we’ve done throughout this article. We’ve uncovered the data requirements for creating a Word Tagger model and where to find that data. We learned about the intricacies and edge cases involved in our task of recognizing culinary recipes. After, we wrote a script that generates a dataset, and then we trained the model.
In the next part of this series, we’ll create our project. We’ll integrate the model trained during the first stage, and implement the functionality of the camera and recipe text recognition using two different approaches with two different tools: GoogleMLKit/TextRecognition (iOS 13.0) and the native Live Text tool (iOS 15.0). Stay tuned! 🧑🍳

By the way, if you’ve got a problem (ML-related or not), Evil Martians are ready to help detect it, analyze it, and to gently send it out of existence! Drop us a line!