


Meet Ruby Next, the first transpiler for Ruby that allows you to use the latest language features, including experimental ones, today—without the stress of a project-wide version upgrade. Read the story behind the gem, discover its inner workings, and see how it can help push Ruby into the future.
These days, Ruby is evolving faster than ever. The latest minor release of the language, 2.7, introduced new syntax features like numbered parameters and pattern matching. However, we all know that switching to the next major Ruby version in production or within your favorite open source project is not a walk in the park. As a developer of a production website, you have to deal with thousands of lines of legacy code that might break in different subtle ways after the upgrade. As a gem author, you have to support older versions of the language as well as popular alternative implementations (JRuby, TruffleRuby, etc.)—and it might be a while before they pick up on syntax changes.
In this post, I want to introduce a new tool for Ruby developers, Ruby Next, which aims to solve these problems, and that could also help the members of the Ruby Core team to evaluate experimental features and proposals. Along the way, we’re going to touch the following topics:
- Ruby versions lifecycle and usage statistics
- Refinements
- Parsers and un-parsers
- The process of accepting changes to the language
Why backporting is important
So, why isn’t it possible to update to the latest version of Ruby every Christmas? As we all know, for years, Matz has been unveiling new major releases right on December 25th. Besides the fact that no one should ever update anything on a holiday, this also has to do with respect for your fellow developers.
Take me, for instance. I like to think of myself as a library developer first, and an application developer last. My unwavering desire to create new gems out of everything is subject of long-running jokes between my colleagues at Evil Martians. Currently, I actively maintain dozens of gems—a few of them quite popular. Anyway, that leads us to the first problem.
I have to write code compatible with older versions of Ruby.
Why? Because it’s good practice to support at least all the officially supported Ruby versions; those which haven’t reached their end of life (EOL).
According to the Ruby maintenance calendar, Ruby versions that are still very much alive at the time of this publication are 2.5, 2.6, and 2.7. Even though you can still use older versions, it’s highly recommended to upgrade as soon as possible—new security vulnerabilities, if found, will not be fixed for EOL releases.
This means I have to wait at least two more years to start using all those 2.7 goodies in my gems without forcing everyone to upgrade.
I’m not even sure I’ll be writing Ruby two years from now, I want this bloody pattern matching now!
But, let’s imagine I suddenly don’t care about users and decide to ship a new release with required_ruby_version = "~> 2.7". What’s gonna happen?
Well, my gems would lose their audience—big time. See the breakdown of Ruby versions according to the recently launched RubyGems.org Stats:

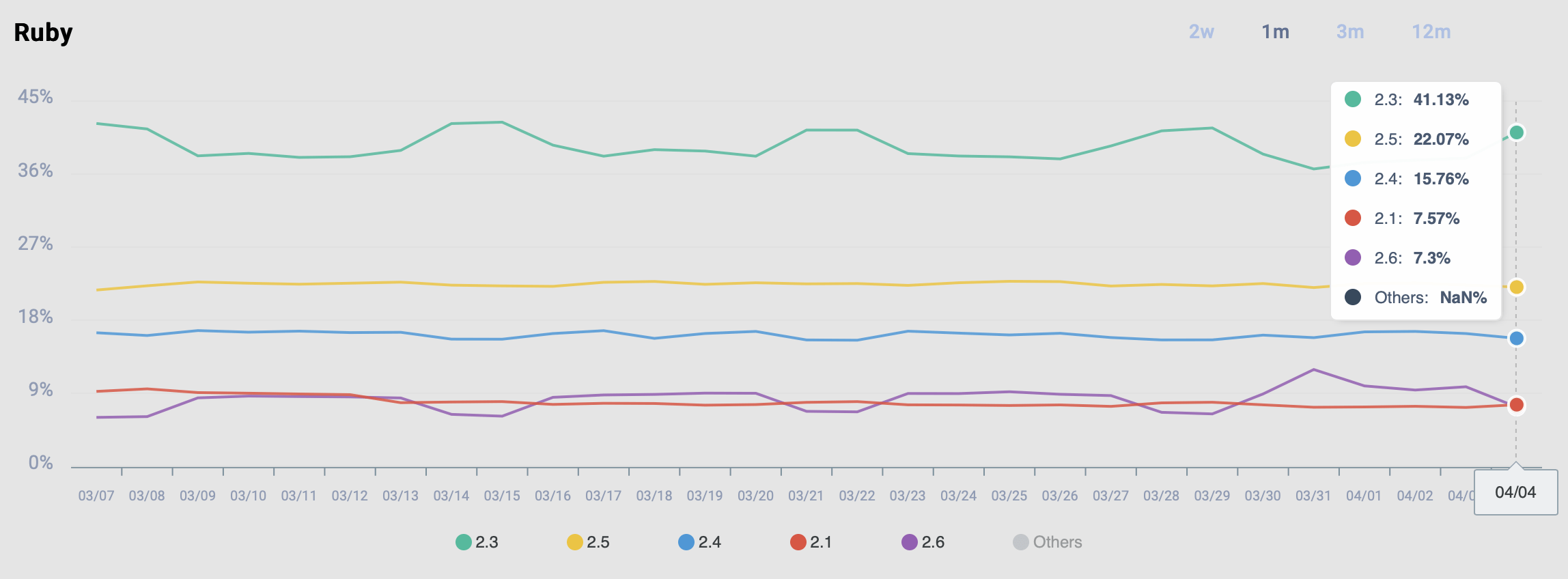
RubyGems.org stats: version breakdowns (Apr 4, 2020)
We can’t even see 2.7 on this chart. Keep in mind that this data is too technical in the sense that it contains stats not only from Ruby applications and developers, but also from irrelevant sources, such as, for example, system Rubies (which are usually lagging a few versions behind the latest release).
A more realistic picture of the current state of the Ruby community comes from JetBrains and their annual survey. The data is for 2019, but I don’t think the numbers have changed drastically:

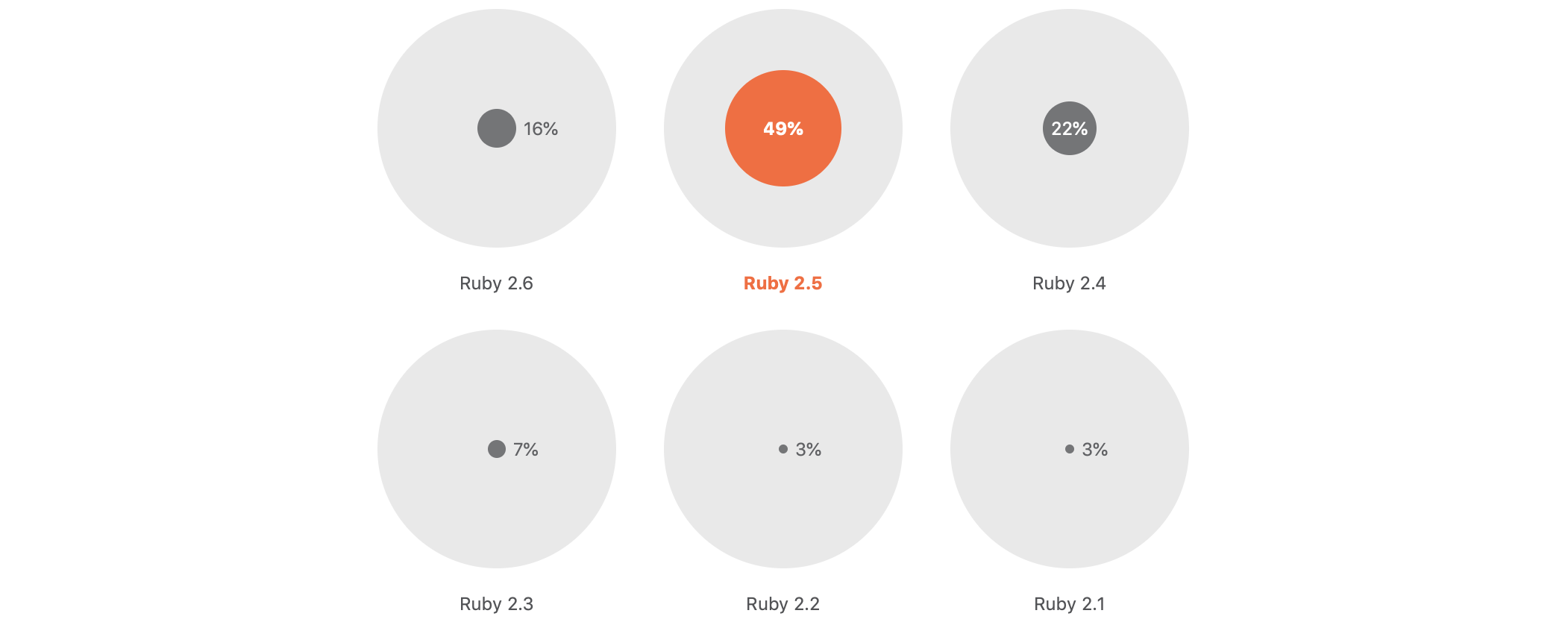
Which version of Ruby do you use the most?
As you can see, 2.3 is no longer the most popular. And still, the latest version (2.6 at the time of the survey) holds only the bronze.
Two or three most recent versions of Ruby are actively used at any time, and the latest is the least popular among them.
Another insight from this survey: “30% reported that they’re not about to switch”.
Why so? Maybe because upgrading for the sake upgrading seems to be too costly. If it ain’t broke don’t fix it, right?
What’s the proper motivation for an upgrade? Performance improvements? (Every next Ruby version has them.) Not sure. Can new features encourage developers to switch sooner? Sure, if they don’t come at a price (like, for example, keyword arguments deprecations and changes in 2.7).
To sum up, the latest language additions could be very attractive in theory but hardly applicable in practice right away.
I decided to find a way to change this to allow everyone to taste modern Ruby in real projects independently of their current environment.
#yield_self, #then transpile
Before we dig into a technical overview of Ruby Next, let me share my personal story of modernizing Ruby.
It was the winter of 2017, and Ruby 2.5 had just appeared under the Christmas tree. One thing from this release caught my attention in a somewhat controversial way: the Kernel#yield_self method. I was a bit skeptical about it. I thought: “Is this a feature that can change the way I write Ruby? Doubt it.”
Anyway, I decided to give it a try and started using it in applications I was working on (luckily, we try to upgrade Ruby as soon as possible, i.e., around x.y.1 release). The more I used this method, the more I liked it.
Eventually, #yield_self appeared in the codebase of one of my gems. And, of course, as soon as this happened—tests for Ruby 2.4 failed. The simplest way to fix them would have been by monkey-patching the Kernel module and making an old Ruby quack like a new one.
Being a follower of gem development best practices (and the author of one particular checklist), I knew that monkey-patching is a last resort measure, and a no-go for libraries. In essence, someone else can define a monkey-patched method with the same name and create a conflict. For #yield_self, this is an improbable scenario. But a few months later, #then alias had been merged into Ruby trunk 🙂
So, we need a monkey-patch that is not a monkey-patch.
And you know what? Ruby has got your covered! This patch looks like this:
module YieldSelfThen
refine BasicObject do
unless nil.respond_to?(:yield_self)
def yield_self
yield self
end
end
alias_method :then, :yield_self
end
endYes, we’re going to talk about refinements for a while.
Doing fine with refine
Refinements can rightly be called the most mind-blowing Ruby feature. In short, a refinement is a lexically scoped monkey-patch. Though I don’t think this definition help really understand just what kind of a beast this feature is. Let’s consider an example.
Assume that we have the three following scripts:
# succ.rb
def succ(val)
val.then(&:to_i).then(&:succ)
end
# pred.rb
def pred(val)
val.then(&:to_i).then(&:pred)
end
# main.rb
require_relative "succ"
require_relative "pred"
puts send(*ARGV[0..1])If we’re using Ruby 2.6+, we can run them and see the correct result:
$ ruby main.rb succ 14
15
$ ruby main.rb pred 15
14Trying to run them in Ruby 2.5 would give us the following exception:
$ ruby main.rb succ 14
undefined method `then' for "14":StringOf course, we can replace #then with #yield_self and make everything work as expected. Let’s not do that. Instead, we’ll use the YieldSelfThen refinement defined above.
Let’s put our refinement code into the yield_self_then.rb file and activate this refinement only in the succ.rb file:
# main.rb
+ require_relative "yield_self_then"
require_relative "succ"
require_relative "pred"
...
# succ.rb
+ using YieldSelfThen
+
def succ(v)
v.then(&:to_i).then(&:succ)
endNow, when we run the succ command, we can see our result:
$ ruby main.rb succ 14
15The pred command, however, will still fail:
$ ruby main.rb pred 15
undefined method `then' for "14":StringRemember the “lexically scoped” part of the refinement definition? We’ve just seen it in action: the extension defined in the YieldSelfThen module via the refine method is only “visible” in the succ.rb file, where we added the using declaration. Other Ruby files for the program do not “see” it; they work as if there were no extensions at all.
This means refinements allow us to control monkey-patches, to put them on a leash. So, a refinement is a safe monkey-patch.
Refinements are safe monkey-patches.
Even though refinements were introduced in Ruby 2.0 (first, as an experimental feature, and stable since 2.1), they didn’t manage to get much traction. There were several key reasons for that:
- A large number of edge cases in the early days (e.g., no modules support, no
sendsupport). The situation was getting better with every Ruby release, and now refinements are recongnized by the majority of Ruby features (in MRI). - Support for refinements in alternative Rubies was lagging. The JRuby Core team (and especially, Charles Nutter) has done a great job improving the situation recently, and refinements have been usable in JRuby since 9.2.9.0.
Today, I dare to say that all the critical problems with refinements are in the past, and “refinements are experimental and unstable” is no longer a valid argument.
That’s why I’m betting on refinements to solve the backporting problem.
We can use refinements to safely backport new APIs.
Before Ruby 2.7, making old Rubies quack like new ones was as simple as adding a universal refinement with all the missing methods.
That’s what the original idea for Ruby Next was—one refinement to rule them all:
# ruby_next_2018.rb
module RubyNext
unless nil.respond_to?(:yield_self)
refine BasicObject do
# ...
end
end
unless [].respond_to?(:difference)
refine Array do
# ...
end
end
unless [].respond_to?(:tally)
refine Enumerable do
# ...
end
end
# ...
end
# ...and then in your code
using RubyNextLuckily, I didn’t release this project in 2018. The addition of new features to Ruby 2.7 showed where the refinement approach is lacking: we can not refine syntax. That is when my work on the most exciting part of Ruby Next, the transpiler, began.
”Refining” the syntax, or transpiling
In 2019, the active evolution of Ruby syntax began. A bunch of new features have since been merged into master (although, not all of them survived): a method reference operator (eventually reverted), a pipeline operator (reverted almost immediately), pattern matching and numbered parameters.
I’ve been watching this Shinkansen passing by and thinking: “Wouldn’t it be nice to bring all these goodies to my projects and gems? Is it possible at all?” Turns out, it was. And that’s how today’s Ruby Next was born.
In addition to a collection of polyfills—refinements, Ruby Next has acquired another powerful functionality—a transpiler from Ruby to Ruby.
Generally, “transpiler” is a word used to describe source-to-source compilers, i.e., compilers which have the same input and output format. Thus, the Ruby Next transpiler “compiles” some Ruby code into another bunch of Ruby code without the loss of functionality. More precisely, we transform source code for the latest/edge Ruby version into source code compatible with older versions:

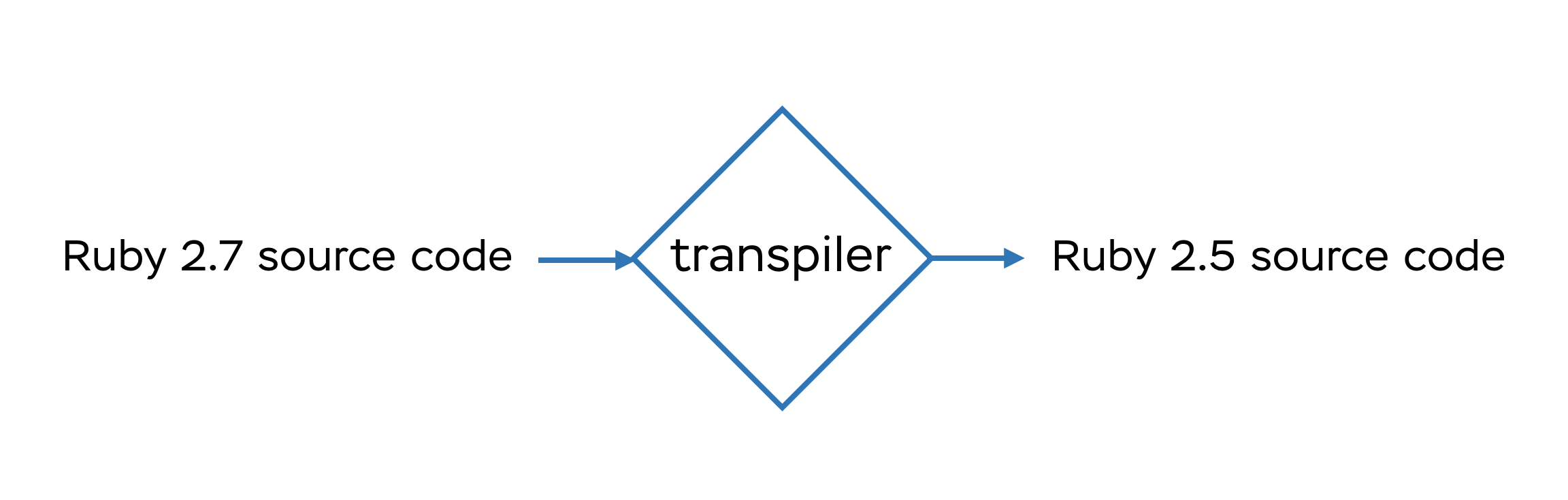
Transpiling is very popular in the world of frontend development, where we have such tools as Babel for JavaScript and PostCSS for CSS.
The reasons why those tools exist are rooted in browser incompatibilities and rapid language evolution (to be more precise, the evolution of specifications). You might be surprised, but we do have the same problems in Ruby, too. We have different “browsers” (Ruby runtimes), and, as we’ve already mentioned, the language is changing fast. Of course, the scale of the problem is not as terrifying as the state of frontend development five years ago, but it’s better to be prepared.
From AST to AST
Let’s have a quick overview of how the Ruby Next transpiler works. Advanced technical details will follow in future posts (or conference talks), so today I’m covering just the basics.
The naive way of transpiling would be loading code as text, applying a few gsub!-s, and writing the result into a new file. Unfortunately, that wouldn’t work even in the simplest case: for example, we could try to transpile the method reference operator (.:) by applying source.gsub!(/\.:(\w+)/, '.method(:\1)'). This works fine unless you have a string or a comment with .: inside. Thus, we need something that is context-aware—for instance, an abstract syntax tree.


Let me skip the theory and move right to practice: how can we generate an AST from some Ruby source code?
We have multiple tools in the Ruby ecosystem which could be used for generating an AST. To name a few: Ripper, RubyVM::AbstractSyntaxTree, and Parser.
Let’s take a look at the ASTs generated by these tools for the following example code:
# beach.rb
def beach(*temperature)
case temperature
in :celcius | :c, (20..45)
:favorable
in :kelvin | :k, (293..318)
:scientifically_favorable
in :fahrenheit | :f, (68..113)
:favorable_in_us
else
:avoid_beach
end
endRipper is a built-in Ruby tool (since 1.9) which allows you to generate symbolic expressions from source code:
$ ruby -r ripper -e "pp Ripper.sexp(File.read('beach.rb'))"
[:program,
[[:def,
[:@ident, "beach", [1, 4]],
[:paren,
[:params,
[:rest_param, [:@ident, "temperature", [1, 11]]],
],
[:bodystmt,
[[:case,
[:var_ref, [:@ident, "temperature", [2, 7]]],
[:in,
[:aryptn,
nil,
[[:binary,
[:symbol_literal, [:symbol, [:@ident, "celcius", [3, 6]]]],
...As you can see, the return value is a deeply nested array with some identifiers. One problem with Ripper is that there is no documentation on the possible “node” types and no noticeable patterns in node structure. More importantly, for transpiling purposes, Ripper can not parse the code for a newer Ruby from an older Ruby. We can’t force developers to use the latest version (and especially an edge version) of Ruby just for the sake of transpiling.
The RubyVM::AbstractSyntaxTree module was recently added to Ruby (in 2.6). It provides a much better, object-oriented AST representation but has the same problem as Ripper—it’s version specific:
$ ruby -e "pp RubyVM::AbstractSyntaxTree.parse_file('beach.rb')"
(SCOPE@1:0-14:3
body:
(DEFN@1:0-14:3
mid: :beach
body:
(SCOPE@1:0-14:3
tbl: [:temperature]
args: ...
body:
(CASE3@2:2-13:5 (LVAR@2:7-2:18 :temperature)
(IN@3:2-12:16
(ARYPTN@3:5-3:28
const: nil
pre:
(LIST@3:5-3:28
(OR@3:5-3:18 (LIT@3:5-3:13 :celcius) (LIT@3:16-3:18 :c))
...Finally, Parser is a pure Ruby gem originally developed at Evil Martians by @whitequark:
$ gem install parser
$ ruby-parse ./beach.rb
(def :beach
(args
(restarg :temperature))
(case-match
(lvar :temperature)
(in-pattern
(array-pattern
(match-alt
(sym :celcius)
(sym :c))
(begin
(irange
(int 20)
(int 45)))) nil
(sym :favorable))
...Unlike the former two, Parser is a version-independent tool: you can parse any Ruby code from any supported version. It has a well-designed API, some useful built-in features (e.g., source rewriting), and has been bullet-proofed by a popular tool, RuboCop.
These benefits come at a price: it isnt 100% compatible with Ruby. This means you can write bizarre, but valid, Ruby code that won’t be recognized correctly by Parser.
Here is the most famous example:
<<"A#{b}C"
#{
<<"A#{b}C"
A#{b}C
}
str
A#{b}C
#=> "\nstr\n"Parser generates the following AST for this code:
(dstr
(begin
(dstr
(str "A")
(begin
(send nil :b))))
(str "\n")
(str "str\n")
(str "A")
(begin
(send nil :b))))The problem is with the (send nil :b) nodes: Parser treats #{...} within the heredocs labels as interpolation, but it’s not.
I hope you won’t use this dark knowledge to break all the libraries relying on Parser 😈
As you can see, no instrument is perfect. Writing a parser from scratch or trying to extract the one used by MRI was too much effort for the experimental project.
I decided to sacrifice Ruby’s weirdness in favor of productivity, and went with Parser.
One more selling point for choosing Parser was the presence of the Unparser gem. As its name says, it generates a Ruby code from the Parser generated AST.
From Ruby to Ruby
The final Ruby Next code for transpiling looks like this:
def transpile(source)
ast = Parser::Ruby27.parse(source)
# perform the required AST modification
new_ast = transform ast
# return the new source code
Unparser.unparse(new_ast)
endWithin the #transform method we pass the AST through the rewriters pipeline:
def transform(ast)
rewriters.inject(ast) do |tree, rewriter|
rewriter.new.process(tree)
end
endEach rewriter is responsible for a single feature. Let’s take a look at the method reference operator rewriter (yeah, this proposal been reverted, but it’s perfect for demonstration purposes):
module Rewriters
class MethodReference < Base
def on_meth_ref(node)
receiver, mid = *node.children
node.updated( # (meth-ref
:send, # (const nil :C) :m)
[ #
receiver, # ->
:method, #
s(:sym, mid) # (send
] # (const nil :C) :method
) # (sym :m)
end
end
endAll we do is replace the meth-ref node with the corresponding send node. Easy-peasy!
Rewriting is not always that simple. For example, pattern matching rewriter contains more than eight hundred lines of code.
Ruby Next transpiler currently supports all Ruby 2.7 features except beginless ranges.
Let’s take a look at the transpiled verison of our beach.rb:
def beach(*temperature)
__m__ = temperature
case when ((__p_1__ = (__m__.respond_to?(:deconstruct) && (((__m_arr__ = __m__.deconstruct) || true) && ((Array === __m_arr__) || Kernel.raise(TypeError, "#deconstruct must return Array"))))) && ((__p_2__ = (2 == __m_arr__.size)) && (((:celcius === __m_arr__[0]) || (:c === __m_arr__[0])) && ((20..45) === __m_arr__[1]))))
:favorable
when (__p_1__ && (__p_2__ && (((:kelvin === __m_arr__[0]) || (:k === __m_arr__[0])) && ((293..318) === __m_arr__[1]))))
:scientifically_favorable
when (__p_1__ && (__p_2__ && (((:fahrenheit === __m_arr__[0]) || (:f === __m_arr__[0])) && ((68..113) === __m_arr__[1]))))
:favorable_in_us
else
:avoid_beach
end
endWait, what? This is unbearable! Don’t worry; this is not code for you to read or edit, this is code for Ruby runtime to interpret. And machines are good at understanding such code.
Transpiled code is for machines, not humans.
However, there is one case when we want transpiled code to be as structurally close to the original as possible. (By “structurally,” I mean having the same layout or line numbers.)
In the example above, line 7 of the transpiled code (:scientifically_favorable) is different from the original (in :fahrenheit | :f, (68..113)). When might this be a problem? During debugging. Debuggers, and consoles (such as IRB, Pry) use original source code information, but line numbers in runtime will be different. Happy debugging 😈!
To overcome this issue, we introduced a “rewrite” transpiling mode in Ruby Next 0.5.0. It uses Parser’s rewriting feature and applies changes to the source code in-place (that’s the same way RuboCop autocorrection works, by the way).
Ruby Next uses the “generation” (AST-to-AST-to-Ruby) transpiling mode by default since it’s faster and more predictable. In any case, the actual backported code is similar.
Performance and compatibility
One question that usually comes up: how does the case-when results’ performance compares to the original, elegant case-in? Prepare to be surprised by the results of the benchmark:
Comparison:
transpiled: 1533709.6 i/s
baseline: 923655.5 i/s - 1.66x slowerHow did it turn out that the transpiled code is faster than the native implementation? I added some optimizations to the pattern matching algorithm, e.g., #deconstruct value caching.
How can I be sure that these optimizations don’t break compatibility? Thank you for yet another good question!
To make sure that transpiled code (and backported polyfills) work as expected, I use RubySpec and Ruby’s own tests. That doesn’t mean that the transpiled code behaves 100% identically to the MRI code, but at least it behaves the way it’s expected to. (And to be honest, I know some weird edge cases that break compatibility, but I won’t tell you 🤫)
Run-time vs. build-time
Now that we’ve learned about the inner workings of transpiling, it’s time to answer the most intriguing question: how can we integrate Ruby Next into library or application development?
Unlike frontend developers, we Rubyists usually don’t need to “build” code (unless you’re using mruby, Opal, etc.). We just call ruby my_script.rb, and that’s it. So how can we inject transpiled code into the interpreter?
Ruby Next assumes two strategies depending on the nature of your code, i.e., whether you’re developing a gem or an application.
For applications, we provide the “run-time mode”. In this mode, every loaded (required) Ruby file from the application root directory is transpiled before being evaluated within the VM.
The following pseudo-code describes this process:
# Patch Kernel to hijack require
module Kernel
alias_method :require_without_ruby_next, :require
def require(path)
realpath = resolve_feature_path(path)
# only transpile application source files, not gems
return require_without_ruby_next(path) unless RubyNext.transpilable?(realpath)
source = File.read(realpath)
new_source = RubyNext.transpile source
# nothing to transpile
return require_without_ruby_next(path) if source == new_source
# Load code the same way as it's loaded via `require`
RubyNext.vm_eval new_source, realpath
true
end
endThe actual code can be found here.
You can activate the run-time transpiling in two steps:
- Add
gem "ruby-next"to yourGemfile. - Add
require "ruby-next/language/runtime"as early as possible during your application boot process (e.g., inconfig/boot.rbfor Rails projects).
If you’re afraid of using such a powerful monkey-patch from a very new library (as I am 🙂), we have you covered with the Bootsnap integration. This way, we move core patching responsibility to Shopify 🙂 (they know how to do that the right way).
When developing a gem, you should think about the many aspects of a good library (see GemCheck), including the number of dependencies and possible side effects. Thus, enabling Ruby Next run-time mode within a gem doesn’t seem to be a good idea.
Instead, we want to make it possible to ship a gem with code for all supported Ruby versions at a time, i.e., with the pre-transpiled code. With Ruby Next, adopting this flow consists of the following steps:
- Generate transpiled code using Ruby Next CLI (
ruby-next nextify lib/). This will create thelib/.rbnextfolder with the files required for older versions. - Configure Ruby’s
$LOAD_PATHto look for files in the correspondinglib/.rbnext/<version>folder by callingRubyNext::Language.setup_gem_load_pathin your gem’s root file (read more).
On one hand, this adds bloat to the resulting .gem package (some files are duplicated). On the other hand, your library users won’t need to care about transpiling at all. Oh, and now you can use modern Ruby in your gem!
From backporting Ruby to pushing it forward
So far, we’ve only considered Ruby Next as a syntax and API backporting tool. To be honest, that’s what I initially was building it to be, with no fine print.
The paradigm shifted in November 2019, as a consequence of two events: method reference operator reversion and RubyConf, where I had an opportunity to discuss the language evaluation with many prominent Rubyists, including Matz himself.
Why so much drama around just two symbols, .:? The situation with the method reference operator is very atypical: it was merged into master on December 31, 2018, and was reverted almost eleven months after on November 12, 2019. Blog posts were published with example usages; transpiler was written to backport this feature… Many Ruby developers found it useful and were waiting for it in 2.7 release.
The feature has been canceled for a reason. Is it OK to revert something that was alive in master for almost a year? Yes, because the feature had the experimental status.
Instead, the proper question should be this: was there an experiment? I’d say “no” because only a small portion of community members were able to try this feature. Most developers do not build edge Ruby from source or use preview releases for applications that are more complex than “Hello, World!”
Ruby 2.7 came out with a major experimental feature—pattern matching. For an application or library developer, the word “experimental” is a red flag. In essence, there is a risk that a significant refactoring would be required if the experiment fails (remember the refinements story?). Will there be enough experimental data to assess the results and promote or revert the feature?
We need more people involved in experiments.
Currently, it’s mostly the people involved in Ruby development itself and a few dozens of enthusiastic Ruby hackers who follow the ruby/ruby master branch and discuss proposals in the issue tracking system.
Can we collect the feedback from more Ruby developers of different backgrounds and programming skills?
Let’s turn an eye towards the frontend development world again.
The JavaScript (or more precisely, the ECMAScript) specification is developed by the TC39 group: “JavaScript developers, implementers, academics, and more, collaborating with the community to maintain and evolve the definition of JavaScript.”
They have a well-defined process of introducing new features, which operates in stages. There are four “maturity” stages: Proposal, Draft, Candidate, and Finished. Only the features from the last stage, Finished, are included in the specification.
Features from the Proposal and Draft stages are considered experimental, and one particular tool plays a significant role in embracing these experiments—Babel.
For a long time, the requirements for the Draft stage acceptance has contained the following sentence: “Two experimental implementations of the feature are needed, but one of them can be in a transpiler such as Babel.”
In short, a transpiler can be used to assess experimental features.
The example of Babel demonstrates that it is a very efficient approach.
What about having something similar for Ruby development? Instead of the merge-n-revert stories, we could have The Process of accepting features based on broader feedback from transpilers users.
Ruby Next aims to be such a transpiler, the one to move Ruby forward.

I’ve started using Ruby Next in my projects recently (check out anyway_config for a Ruby gem example and ACLI for mruby). It’s no longer an experimental project but is still at the very beginning of its open source journey.
The easiest way to give Ruby Next (and new Ruby features) a try is to use the -ruby-next option for the ruby command:
$ ruby -v
2.5.3p105
# Gem must be installed
$ gem install ruby-next
$ ruby -ruby-next -e "
def greet(val) =
case val
in hello: hello if hello =~ /human/i
'🙂'
in hello: 'martian'
'👽'
end
greet(hello: 'martian') => greeting
puts greeting
"
👽As you can see, Ruby Next already supports endless method definition and right-hand assignment, two new experimental features. Will they reach the final 3.0 release? Not sure, but I want to give them a try and provide feedback to the Ruby Core team. What about you?
I want Ruby Next to play an essential role in the adoption of new features and language evolution. Today, you can help us take a step towards this future by using Ruby Next in your library or application development. Also, feel free to drop me a line regardless of what you think about the idea as a whole!
As usual, don’t hesitate to contact Evil Martians, if you want me or my colleagues to give you a hand with application development.