Taking off the Heroku training wheels: the Rails preflight checklist



You’ll hardly find a Ruby on Rails developer who has never tried to deploy their applications via Heroku, a cloud-based platform which innovated how we deliver code from development to production. The git push heroku main flow is pure magic, but in order for it to work, you need to tweak your application a little bit. Today, I’d like to share my checklist targeted to small teams going live with Heroku.
At the time of this writing, in mid-2022, plenty of alternatives to Heroku are available, but it’s still the number one choice for shipping your first Rails MVP. Heroku has everything you need in one place: application servers, databases, file storage—whatever you want, as well as some things a larger cloud-based solution could offer (such as Amazon Web Services, which Heroku is built on top of). Yes, this comes with a price—not having a DevOps team to manage all the infrastructure complexity! Jokes aside, Heroku helps you save money and, more importantly, it helps save time in the short to medium term. But remember that when you get bigger, the bills get higher.
A couple of times in the past, we’ve written about dealing with big Rails applications on Heroku (one and two), but we’ve never shared our approach on getting started with the platform itself. How to prepare the codebase? How to configure deployment pipelines? How to… okay, let’s stop asking questions and just get started with the actual checklist.
Heroku has comprehensive documentation, especially for Ruby on Rails projects. Check it out first!
To pipeline or not to pipeline
The official getting started guide assumes you’re creating a standalone Heroku application (via heroku create). That’s good enough for experiments and lone-wolf-style developers, but we generally work on teams. Further, we usually embrace phased deployments: first, pushing updates to staging, doing some kind of QA, and finally, rolling out the updates to production. Sounds like a pipeline? Yes, it does. And we can easily get it on Heroku, too.
Surprisingly, the corresponding feature is actually called Pipelines. Pipelines allow you to group multiple applications and put them on different stages: production, staging, development (the most mysterious one) and review (we’re going to talk about this stage in detail below).
✅ Create a pipeline with staging and production applications, connect it to the repository.
Using pipelines from the very beginning is a must. If you’ve already created a standalone application, move it to the staging phase in the pipeline. Otherwise, create a new application.
I also prefer to create a production Heroku application as early as possible. This way I can configure all the DNS/SSL settings (see below) and make sure the project is accessible on the Internet beforehand (and not the night before the launch). While the project is still in development, we can turn on maintenance mode (with a custom page saying something like “Coming soon”—see the docs).
Nowadays, deploying to Heroku doesn’t even require running git push <whatever>; Heroku can do it for you (except when it couldn’t). I always turn on automatic deploy for the staging app so that staging reflects what is currently in the main branch.
Regarding production, strategies could vary:
- You could also connect the production to the
mainbranchand pray. - You could use a custom branch (say, “production”) and trigger deployments via the
git pushcommand (running locally or on CI). - You could manually hit the “Deploy Branch” button on Heroku.
- You could use the “Promote to production” feature.
The ability to “Promote to production” is one of the greatest Heroku pipeline features. Its main benefit (apart from the very descriptive title) is that the code goes live almost immediately, no building required. However, the lack of a build phase could be a problem: sometimes our builds depend on configuration. For example, we can inject some API keys into our JS code during assets:precompile, and we’d need different keys for staging and production. Another example is integrating with APM or error tracking services, which track releases (see Sentry + Heroku integration).
Making Rails Heroku-ready
Deploying a fresh Rails application to Heroku is a no-brainer: just push the code or hit the “Deploy” button. Zero configuration, zero code changes; your app will be live in minutes.
First, Heroku tries to do its best to detect your application language and choose the right buildpack, and heroku-buildpack-ruby does its magic to infer the configuration settings and required add-ons (e.g., a database). (Kudos to Richard Schneeman!)
Here is what we might have in the application configuration after the initial deployment:

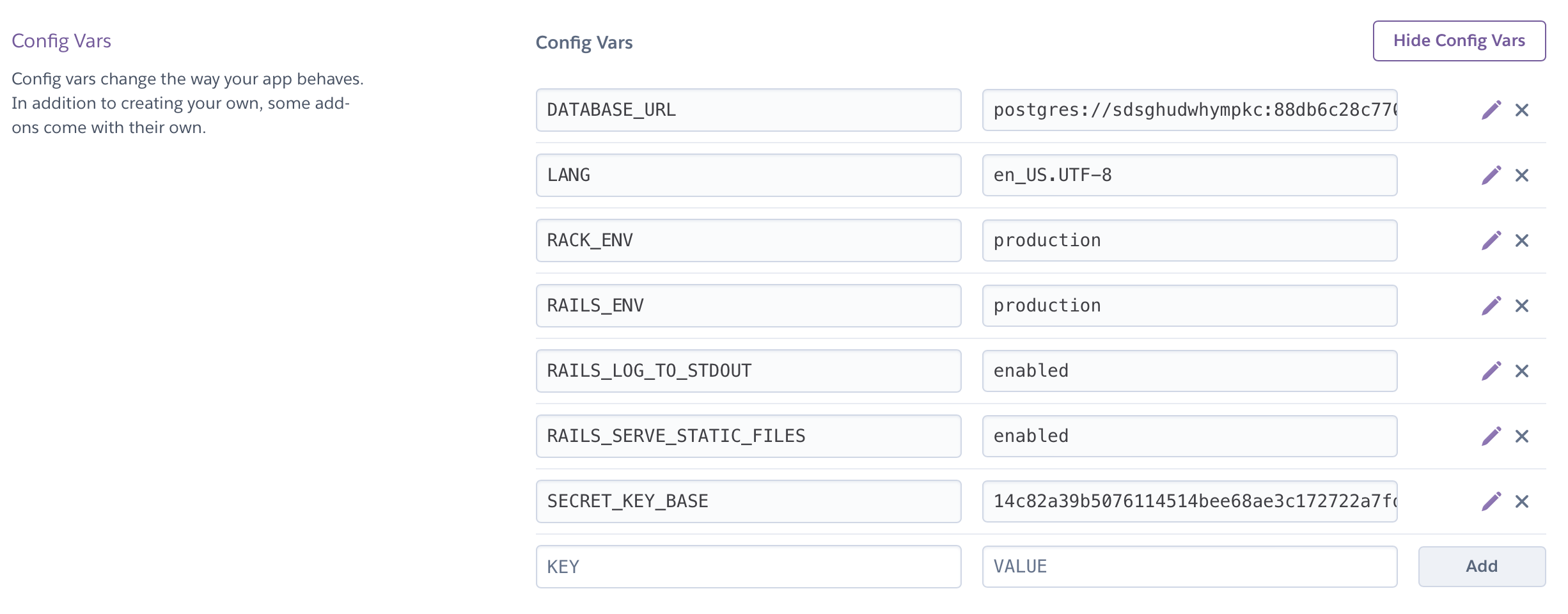
Heroku application config for a fresh Rails app
Make sure your production.rb is aware of these settings.
✅ Make sure your app recognizes the
RAILS_LOG_TO_STDOUTandRAILS_SERVE_STATIC_FILESsettings.
Unfortunately, I can’t stay “config-less” for too long…
Procfile and Rake tasks
By default, Heroku implicitly configures the web process to run your Rails server (something like bin/rails server -p ${PORT:-5000} -e $RAILS_ENV). Most likely, you will need at least one more process group in your application, worker. Let’s use Sidekiq as an example.
To define multiple process groups (or services), we need to create a Procfile:
# <project-root>/Procfile
web: bundle exec rails server -p $PORT -b 0.0.0.0
worker: env RAILS_MAX_THREADS=$WORKER_MAX_THREADS bundle exec sidekiq✅ Configure a Procfile with individual concurrency settings per service.
It might be a bit unfamiliar how my Procfile is set up. What is env RAILS_MAX_THREADS=$WORKER_MAX_THREADS?
Let’s start with the RAILS_MAX_THREADS env variable. By default, the value of this variable is used by Rails, Puma, and other libraries to set concurrency limits. In Rails, you can find it in the default database.yml where it’s used to specify the Active Record’s connection pool size. Puma’s default configuration uses this value to define the max number of threads per process to use. To prevent congestion, it’s important to have at least the same number of database connections as Puma threads.
Sidekiq also uses threads, and we typically have 10 to 20 of them to process our background jobs. Background tasks usually deal with the database, thus, it’s best to have a dedicated connection per thread. How can we change the Active Record pool size just for Sidekiq processes? By setting the value right in the Procfile. We’ll use the env X=Y trick so it will still be configurable via application settings.
Thus, in the application settings, we set WORKER_MAX_THREADS=10, and, finally, in sidekiq.yml we use the canonical RAILS_MAX_THREADS variable:
---
:concurrency: <%= ENV.fetch('RAILS_MAX_THREADS', 5) %>
# ...Having a worker process is not the only reason why we need a Procfile: we also want to automate running database migrations.
Heroku introduced the Release Phase about five years ago (yeah, I remember the pre-release times). You define a special release command, which is executed right before the app goes live. This is the best place to put our rails db:migrate—or is it?
I want to go custom here (or unique, “as usual” 😉) and introduce custom Heroku Rake tasks.
✅ Add
heroku.rakeand userails heroku:releaseas the Release Phase command.
Running database migrations is not the only task we may want to run before the app goes live. For example, we can run data migrations, send Slack notifications, or do nothing (e.g., skip migrations when deploying an AnyCable gRPC app).
That’s why I prefer to go with a custom Rake task, heroku:release, which I can extend or modify using Ruby and without ever touching the Procfile:
# lib/tasks/heroku.rake
namespace :heroku do
task release: ["db:migrate"]
endTaking care of slugs
A slug is a distribution of your application, a “package” containing your code and any dependencies; something like a Docker image but without an OS layer.
And like with Docker images, size matters. First, the smaller slug is the faster it could be deployed (compressed, uncompressed, transferred to a Dyno manager, etc.). Second, slugs have a maximum allowed size of 500MB. And it’s very easy to hit this limit, especially if you’re working on a rich frontend application.
✅ Configure
.slugignoreand.slug-post-clean(via heroku-buildpack-post-build-clean)
There are two things you should consider regarding this problem:
- Add the
.slugignorefile and list the files from your repo which aren’t required to build and run the application. - Install heroku-buildpack-post-build-clean and add a
.slug-post-cleanwith the build-only dependencies.
Here the examples of these files:
# .slugignore
dockerdev
.github
.rubocop
docs
# .slug-post-clean
node_modules
tmpA bit of instrumentation
We can save some 💰 on powerful APMs and start with Heroku’s built-in runtime metrics support.
✅ Enable Ruby runtime metrics.
The official documentation covers all you need. Only on production, I deviate from it a bit by installing the barnes gem:
# Gemfile
gem "barnes", group: :production
# puma.rb
# ...
# Run Barnes only if available
begin
require "barnes"
rescue LoadError # rubocop:disable Lint/SuppressedException
end
before_fork do
Barnes.start if defined?(Barnes)
endAdding Heroku-awareness to the application
What should our application know about the platform it’s being deployed to? One may say “Nothing! Code should be platform-agnostic!” I could agree with this statement to some extent, but instead of arguing, let’s re-phrase the original question: can we use environment information to infer sensible defaults for our application? Sure we can.
One particular configuration parameter, which we can get from Heroku, is the current application hostname. We need to know our application hostname, for example, to generate URLs in emails sent via Action Mailer.
We can set the hostname in a configuration file like this:
config.action_mailer.default_url_options = { host: "example.com" }On Heroku, we can use the application name to build a hostname: <appname>.herokuapp.com. How can we get this name?
✅ Enable Dyno Metadata:
heroku labs:enable runtime-dyno-metadata.
This information is not available by default and should be explicitly turned on. Once you’ve enabled it, you can access the Heroku application information via environmental variables, for example, ENV["HEROKU_APP_NAME"].
Of course, I do not recommend using env vars right in the default_url_options. That how we could cross a line between using the platform details as the source of configuration and depending on the platform. Instead, I go with a class-based configuration approached via anyway_config.
✅ Add configuration classes to access Heroku details and manage application general settings (optional).
We need two configuration objects: one for Heroku details and one to keep application-wide settings (such as hostname). Here is a simplified example:
# config/configs/heroku_config.rb
class HerokuConfig < ApplicationConfig
attr_config :app_id, :app_name,
:dyno_id, :release_version,
:slug_commit, :branch, :pr_number
def review_app?
pr_number.present?
end
end
# config/configs/my_app_config.rb
class MyAppConfig < ApplicationConfig
attr_config :host, :port, # The address of the server
:asset_host, # Custom URL for assets
seo_enabled: false # Enable SEO features (robots.txt, etc.)
def ssl?
port == 443
end
def asset_host
super || begin
proto = ssl? ? "https://" : "http://"
port_addr = ":#{port}" unless port == 443 || port == 80
"#{proto}#{host}#{port_addr}"
end
end
endAs you can see, one benefit of having configuration classes is that you can add helper methods and computed values.
And here is the application.rb file using these configuration objects:
# Store configuration singleton in the Rails config object,
# so we can standardize the way we access configuration.
config.my_app = MyAppConfig
config.heroku = HerokuConfig
# Set project hostname if missing.
# In production, we set the real hostname via ENV['MY_PROJECT_HOST']
if config.my_app.host.blank?
config.my_app.host = "#{config.heroku.app_name}.herokuapp.com"
end
config.action_mailer.default_url_options = {
host: config.my_app.host,
port: config.my_app.port,
protocol: config.my_app.ssl? ? "https" : "http"
}
config.action_mailer.asset_host = config.my_app.asset_hostThis might look like unnecessary overhead—we just have two apps, it’s not a big problem to simply manually configure env vars. True, but we plan to have many more apps—review apps!
Mastering review apps
In my opinion, Heroku review apps is the most powerful feature for teams. Instead of playing leapfrog with staging apps, you can have a dedicated application instance per a pull request—your personal staging!
✅ Enable and configure review apps.
Setting up review apps requires some additional work. Let’s walk through the most important preparation tasks.
Configuration, app.json, and credentials
Heroku uses a specific file—app.json—to spin up review apps. It describes buildpacks, dyno types, add-ons, and environment configuration. The configuration for review apps could be stored in two places: app.json itself and pipeline settings. The reasoning behind this separation is to avoid keeping sensitive data (such as API keys) in a plain text file.
Luckily, with Rails, we have a more elegant solution to this problem: credentials. Keeping as many secrets as possible in the config/credentials/production.yml.enc file and only setting the RAILS_MASTER_KEY on Heroku would be ideal.
✅ Add
config/environments/staging.rbto use with staging and review apps.
However, a single production application’s set of secrets usually don’t fit all three environments: production, staging, review. For example, review apps should use test Stripe accounts, not the real ones. That’s why I recommend adding RAILS_ENV=staging to the mix. The Ruby configuration file could be as simple as this:
require_relative "production"
Rails.application.configure do
# Override production configuration here
endNOTE: Don’t forget to add staging to database.yml (and <whatever>.yml) and to create staging credentials (rails credentials:edit -e staging).
Some configuration parameters can only be set via environment variables. I’d suggest providing them all via the pipeline settings (“Review apps config vars”) and keep app.json clean. For example, I store all Rails default env vars via pipeline settings (RAILS_ENV=staging, RAILS_SERVE_STATIC_FILES=enabled, etc.) as well as, of course, the RAILS_MASTER_KEY value for staging. There is at least one review-specific config var you must set, too: DISABLE_DATABASE_ENVIRONMENT_CHECK=1. We’re going to talk about it in a minute.
Here is an example app.json file from one of my recent projects:
{
"environments": {
"review": {
"scripts": {
"postdeploy": "bundle exec rails heroku:review:setup",
"pr-predestroy": "bundle exec rails heroku:review:destroy"
},
"formation": {
"web": {
"quantity": 1
}
},
"addons": [
{
"plan": "heroku-postgresql",
"options": {
"version": "14"
}
}
],
"buildpacks": [
{ "url": "heroku/nodejs" },
{ "url": "heroku/ruby" },
{
"url": "https://github.com/Lostmyname/heroku-buildpack-post-build-clean"
}
]
}
}
}✅ Minimize review app dependencies by using in-process adapters for background jobs.
Note that we only declare the web service here, but not the worker one. That’s a cost optimization which could be useful at early stages. Thanks to Active Job, we can easily use different queueing backends without changing our code:
if config.heroku.review_app?
config.active_job.queue_adapter = :async
else
config.active_job.queue_adapter = :sidekiq
endAlternatively, you can add a specific configuration parameter to define the adapter (for example, if you want to leave the possibility of running Sidekiq in review apps).
Oh, we haven’t talked about review scripts yet? Let’s do that now.
Postdeploy and predestroy scripts
Review apps have additional lifecycle hooks that you can use to prepare an application (or clean up when it’s no longer needed).
✅ Define
heroku:review:setupandheroku:review:destroyRake tasks.
I use the same heroku.rake file to define the corresponding tasks:
namespace :heroku do
task release: ["db:migrate"]
# Review apps lifecycle
namespace :review do
# Called right after a review app is created
task setup: ["db:schema:load", "db:seed"]
# Called after review app is destroyed
task(:destroy) {}
end
endIn this example, we load the initial database schema from the schema dump (instead of re-running all migrations in the release phase) and also populate seeds. You may a separate set of seeds here or even restore a production database.
The destroy task could be used to drop user-generated content (e.g., S3 bucket) or delete search engine indexes. By the way, how do we deal with file uploads on Heroku, especially on review apps?
Sharing staging resources with review apps
Rails comes with Active Storage, a framework to deal with file uploads, which provides an abstraction over the actual storage mechanism (a particular cloud provider or file system). Heroku doesn’t provide any official storage solution; a typical workaround is to create an AWS S3 bucket ourselves or via an add-on (such as Bucketeer).
To avoid creating an add-on (or configuring a bucket) for each review app, we can re-use the one created for staging: just copy the configuration (BUCKETEER_AWS_ACCESS_KEY_ID, etc.) to the review app config vars, and that’s it. Since Active Storage uses UUIDs for file keys, we don’t even need to worry about collisions.
And, if you must use a bucket per app, you can use the heroku:review:setup and heroku:review:destroy tasks to create and destroy buckets, respectively (and use config.heroku.app_name as an identifier).
In a similar fashion, it’s possible to re-use the same ElasticSearch instance (and to use app names as namespaces) and even to re-use Redis instances.
DNS, SSL, CDN, WTFs
Heroku apps come with DNS and SSL pre-configured. But you don’t want to use whatever.herokuapp.com as your product web address, right?
So, you bought a domain, chose a DNS provider, what’s next? We need to set up a content-delivery network (CDN).
✅ Configure CDN to serve all application traffic.
CDN is crucial for our Rails application: we’ve configured it to serve static assets, and thus, every time a user opens a page and loads dozens of JS files (thanks to Import Maps 🙂), it wastes our Rails server resources (it occupies Ruby threads). We can’t afford that, and our Rails app deserves the best. That’s why we must use some caching proxies or CDNs.
There are two CFs usually considered as CDN candidates: CloudFront (by AWS) and Cloudflare. CloudFront is a great choice for advanced users who need more flexibility and features (and have some time to spend on its configuration).
Cloudflare is more like Heroku among CDNs: you can setup DNS, SSL and distributions in a few clicks. This simplicity (and a generous free plan, by the way) makes it especially popular among Heroku users.
From the Heroku point of view, all you need is to configure a custom domain name. The official documentation has you covered here; I have nothing to add! Well, maybe, just one thing: make sure you use <xxx>.herokudns.com in your CNAME records, not <yyy>.herokuapp.com.
I also recommend securing traffic between CDN and Heroku. In Cloudflare, for example, that means using the “Full encryption” mode (and creating an Origin certificate to be used by Heroku).
Here are the relevant Rails configuration changes in a single diff:
+++ b/config/environments/production.rb
# Disable serving static files from the `/public` folder by default since
# Apache or NGINX already handles this.
config.public_file_server.enabled = ENV["RAILS_SERVE_STATIC_FILES"].present?
+ # Tell "clients" (and CDNs) to cache assets
+ config.public_file_server.headers = {
+ "Cache-Control" => "public, s-maxage=31536000, max-age=15552000",
+ "Expires" => 1.year.from_now.to_formatted_s(:rfc822)
+ }
# Force all access to the app over SSL, use Strict-Transport-Security, and use secure cookies.
- # config.force_ssl = true
+ config.force_ssl = trueBonus: SEO-unfriendly apps
Do you want your staging and review apps to be scraped by web crawlers and put into a web search index? Doubt so.
✅ Make sure your staging and review apps are non-indexable.
The default Rails robots.txt file allows crawlers to index your website. We can simply add Disallow: / to it to “hide” our applications. But what if we want to index our production website? We have to generate robots.txt dynamically.
I do that by mounting a minimal Rack app into Rails routes:
# config/routing/robots.rb
module Routing
module Robots
def self.call(_)
response = Rack::Response.new
response["Content-Type"] = "text/plain"
response.write "User-agent: *\n"
# Cache for 1 day, so we can turn on/off SEO quickly
cache_for = "86400"
response["Cache-Control"] = "public, max-age=#{cache_for}"
# This is where we use our configuration object again
unless MyAppConfig.seo_enabled?
response.write "\nDisallow: /\n"
end
response.finish
end
end
end
# routes.rb
Rails.application.routes.draw do
# ...
require_relative "routing/robots"
get "robots.txt", to: Routing::Robots
endUnfortunately, that’s not enough: if a crawler finds a link to our staging/review app somewhere in public, it would attempt to index it without looking at robots.txt. We can prevent indexing by adding a specific header to our responses—X-Robots-Tag. Let’s do that:
# config/application.rb
unless config.my_app.seo_enabled?
config.action_dispatch.default_headers.merge!({ "X-Robots-Tag" => "none" })
endFinal touches and further reading
There are a couple more things to consider before going live which I’d like to quickly mention.
✅ Don’t forget about
rack-timeout.
First, make sure you have added the rack-timeout gem, so you don’t hit H12 errors.
✅ Enable Preboot for zero-downtime experience.
Then, consider enabling Preboot for your production application to avoid downtimes during deployments. Be careful: with Preboot, it’s easy to hit database or Redis connection limits, make sure you’ve done the math before enabling it (or use this calculator from Rails Autoscale).
Finally, check out our Big on Heroku article to learn about what awaits in the future.


And one more thing: if you have a problem or project in need, whether it’s Ruby related, team related, or anything else under the sun, Evil Martians are ready to help! Get in touch!