The scenic route: lessons building an IntelliJ IDEA plugin for Luau



I’ve been a JetBrains die-hard my whole life, someone who recoils at even the slight thought of using VSCode, and I’ve even been called a “JetBrains junkie”. So, when I learned their IDEs didn’t support Luau, I ventured on a quest to build a plugin for it. No matter your language, this post will guide you through the process of adding custom language support to JetBrains IDEs, pains, parsers, and all.
First of all, let’s mention you can check out the intellij-luau plugin here.
By the end of this post, you’ll have the foundations of custom language support in a JetBrains IDE. You’ll know how to register a file type, write a lexer and parser with JFlex and GrammarKit, and see how those pieces generate a PSI tree that the IDE can navigate. Along the way, we’ll also touch on syntax highlighting, basic navigation, and some debugging tips, more lessons drawn from battle.
You don’t need to be a compiler expert to follow along, but a little Java or Kotlin experience, familiarity with IntelliJ IDEA or any other JetBrains IDE, and a willingness to experiment will help. If you’ve used VS Code with a language server, that background will make some comparisons easier, though it’s not required.

Hire Evil Martians
Need help adding language support or creating or extending plugins? Evil Martians are ready!
Understanding the pipeline
Let’s quickly map how an IDE thinks about code.
An IDE starts with plain text. The lexer chops that text into tokens (keywords, numbers, symbols). The parser arranges those tokens into an Abstract Syntax Tree (AST), a blueprint of the program’s grammar. On top of that, JetBrains builds the PSI (Program Structure Interface), which is the AST plus extra powers for editing, navigation, and refactoring.
If you’ve used VS Code with an LSP, here’s the key difference: the PSI is the IDE’s editable blueprint, while an LSP is more like an external consultant. That gap explains why JetBrains developers often need both.
The LSP way vs. the “joy of learning” way
When adding language support to IntelliJ, you have two main paths: writing native support or integrating with a Language Server (LSP).
Native support gives you full control over how the IDE handles your language—from syntax highlighting to navigation and refactoring—but it requires building everything from scratch and learning a lot of things about the language.
An “alternative way” is to use LSP. LSP is a more general-purpose protocol that lets editors communicate with a standalone language server. Making it faster to get basic features like autocomplete and diagnostics working, because they are already implemented by someone else, the language team, or another developer.
Over the last couple of years, JetBrains has added support for LSPs in their paid IDEs (and now PyCharm). This means it’s a matter of ~30 lines of code to have something up and running.
So what should you choose?
Well, this isn’t a serious question, you take both!
Many IntelliJ platform features still require native language support. As far as I understand, any feature requiring custom code manipulation or analysis requires native support, because LSP doesn’t give you the whole parsing tree even for the open file. This is because serializing and sending the whole tree would be too expensive. So LSP returns only coordinates in the file with the additional metadata where the inspections or highlighting should be applied. This means you have to build your own parser.
But you can offload some complicated stuff like reference resolution or type inference to LSP. In my case, LSP can get this from the analyzer built into the compiler, so it’s definitely more precise.
This post intentionally takes the “scenic” route. We’ll touch on all of the above as we go through the sometimes frustrating (but endlessly rewarding) process of building native language support from scratch.
We’ll cover things like crafting lexers and parsers, wrestling with soft keywords, PSI trees, and error recovery. This guide walks through the real stuff.
Prepping for battle
Before we jump in, let’s note that this isn’t my first rodeo when it comes to building language plugins for IDEs. My first attempt was building an IntelliJ plugin for CWL, a YAML-based language used to build pipelines. YAML is perhaps the mightiest data serialization language of all time, it gives me the shivers to think of what it might take to support all of its quirks.
Following in the footsteps of the best developers, I ended up writing a custom parser. Sadly, I lost that battle, and after working on it for some time, I capitulated to the beastly CWL. Anyway, writing everything as raw text didn’t feel like the right approach, and the visual editors being explored by other teams seemed more promising (though they all eventually faded away too).
I chose an “easier” opponent for my next match and built a toy plugin to add a hedgehog icon and check syntax for Browserslist files. In hindsight, this was a relatively smooth project. I’ve since forgotten most of the WTF grammar issues and JavaScript integration headaches (which, to be fair, still aren’t fully solved).
After this quick win, my desire to write more plugins laid dormant …until just recently.
This time, I’ll tackle JetBrains support for Luau. Luau is a fast, gradually typed embeddable scripting language derived from Lua, a language known for its use in game development, embedded systems, and config scripting. That said, this guide is going to be useful no matter what your language of choice.
Getting started
To create a plugin, you have to solve one of 2 hard problems in computer science: naming a thing (another two being cache invalidation, and off-by-1 errors).
Thankfully, JetBrains got you covered with the guidelines.
Next, you create a new plugin from the template with one click, and with all the boring parts done, you can enjoy implementing all the features the IDE gives you.
The foundation of every language support the lexer and parser. The lexer breaks raw text into tokens (like keywords, strings, and symbols), while the parser turns those tokens into a structured tree that an IDE can work with (this is known as the Program Structure Interface, or more commonly, PSI). PSI is the IntelliJ platform-specific abstraction that sits on top of the AST (Abstract Syntax Tree), adding IDE-oriented capabilities like navigation, refactoring, and inspections.
So, we’ll want to start with these basics, registering the file type and writing the lexer and parser. In theory, you could use whatever you wanted for both of these, but the easiest options in terms of integration are JFlex and GrammarKit.
Notes on writing the lexer
The lexer takes your raw source code (text) and breaks it into tokens. This process prepares the code so the parser (which comes next) can understand the structure.
The JFlex lexer is based on the DFA state machine (also used by some regular expression engines) generated from a grammar. In this grammar you describe which symbols are allowed in which state, state transitions, and the tokens to return.
%%
// Generated boilerplate and most of the content is, of course, skipped
// Define regular expressions, usually to match literals and line ends
EOL=\n|\r|\r\n
LINE_WS=[\ \t\f]
WHITE_SPACE=({LINE_WS}|{EOL})+
// Define possible states
%state xTEMPLATE_STRING
%state xTEMPLATE_STRING_EXPRESSION
%%
// Define rules for several states at once
<YYINITIAL, xTEMPLATE_STRING_EXPRESSION> {
{WHITE_SPACE} { return TokenType.WHITE_SPACE; }
// Process keywords
"and" { return AND; }
"break" { return BREAK; }
// Switch to a different state
"`" { yybegin(xTEMPLATE_STRING); return TEMPLATE_STRING_SQUOTE; }
[^] { return TokenType.BAD_CHARACTER; }
}
// Define rules specific for a state
<xTEMPLATE_STRING> {
"{" { yybegin(xTEMPLATE_STRING_EXPRESSION); return LCURLY; }
"`" { yybegin(YYINITIAL); return TEMPLATE_STRING_EQUOTE; }
// Do not forget to process all the input
[^] { return TokenType.BAD_CHARACTER; }
}Dealing with the lexer part of things is mostly straightforward, and you just follow the language spec. So, if the language supports trailing underscores in the numbers, allowing you to write 10__.__, you do it. The most complex things are those that require a bit of state and manual code. In Luau, these turn out to be mostly strings.
String interpolation
Luau introduced string interpolation similar to what we can find in other languages.
Nested string interpolation like this { "inter" .. `{"po" .. `{"lation"}`}`} requires you to track the number of braces, as well as the level of nesting. The most straightforward way to achieve this is to add a bit of manually written functions to the lexer, adding this information along with the state.
private static final class State {
final int nBraces;
final int state;
private State(int state, int nBraces) {
this.state = state;
this.nBraces = nBraces;
}
}
private final Stack<State> stack = new Stack<>();
private void pushState(int state) {
stack.push(new State(yystate(), nBraces));
yybegin(state);
nBraces = 0;
}
private void popState() {
State state = stack.pop();
yybegin(state.state);
nBraces = state.nBraces;
}
private int nBraces = 0;The next hardest thing is attentively reading the docs. For instance, interpolation strings in Luau allow comments, which I completely missed during the first iteration:
local a = `{
1
-- adds nine
+ 9
}`Handling multiline strings and lexer errors
Luau has a couple of ways to write multiline strings. First up are [[]] strings, to avoid conflicts with [[ inside them, Luau allows using additional = signs:
[=[Hello
[[world!]]
]=]So, the lexer should track number of = to correctly identify the end of the string, which we can solve similarly by adding the state. As a bonus, there is a format of documentation strings that uses a similar structure within comments. This is usually handled by a separate lexer.
Similar to Python, Luau also allows line breaks inside strings if they’re explicitly escaped:
local multiline = "Only\
In Your\
Wildest\
Dreams\
"I initially made the lexer return an error token upon reaching the first unescaped newline inside the string. This turned out to be a typical mistake. The IDE will look fine except for a red mark near the scrollbar, and this will drive you mad because you won’t see any errors in the source code. A slightly better solution is to mark the entire string as an error token. Doesn’t look great, but at least it’s visible.
From what I’ve seen, you can’t display custom error messages like “incomplete string” at the lexer level. If you want a meaningful error message, it needs to be handled either in the parser or through an annotation.
Having required escapes, though, makes things easier for the lexer. Compare that to a language like Haxe, where line breaks don’t need to be escaped. There, if a string is missing a closing quote, the lexer is free to treat the rest of the file as part of the string—breaking highlighting, autocomplete, and error reporting:
var str = "Line one
Line two
Line three";This is mitigated by automatic insertion of the closing quote when you enter the opening one in IDE.
Soft keywords
When designing a language, you can’t predict which keywords you’ll need in the future. At some point, you may need new keywords already in use by developers as variable names. In those cases, your only real option is to make the keyword context-sensitive, a “soft keyword”, which only behaves like a keyword in specific situations.
For example, Python added pattern matching in version 3.10, which required two new soft keywords. We can also see that Kotlin uses many soft keywords (although clearly not all of them are intended to avoid breaking code). They even treat some Java keywords, like import, as soft keywords.
Let’s take a look: there is no continue statement or keyword in Lua (goto with labels was added in 5.2 as a general purpose alternative), but one was added to Luau along with export , typeof , type and in the most recent versions, read and write . All these names can already be used as identifiers, and to avoid breaking backwards compatibility they have to be soft keywords. That means that this program is valid:
local typeof = 1
local export = 1
local type = export + typeof
local continue = type + 2So, unlike regular keywords (which are easy for the lexer to recognize), soft keywords require coordination between the lexer and parser. Depending on how much flexibility or control you want, there are a few common tricks to know about.
#1: Return the specific tokens even for the soft keywords. However, we would have to specify in the parser that these keywords can be a part of the identifier. This is what a Haxe plugin does:
// KFROM ('from') and KTO ('to') are only keywords for abstracts and can be used as identifiers elsewhere in the code (KNEVER ('never') is only used for getters/setters)
private identifierWithKeywordName::= 'from' | 'to' | 'never'This ends up wrapping each identifier token into an identifier PSI element.
#2: The TypeScript WebStorm lexer uses a different kind of magic, and both type and string are keywords in any context. Also, there is no extra wrapping, unlike in Haxe.

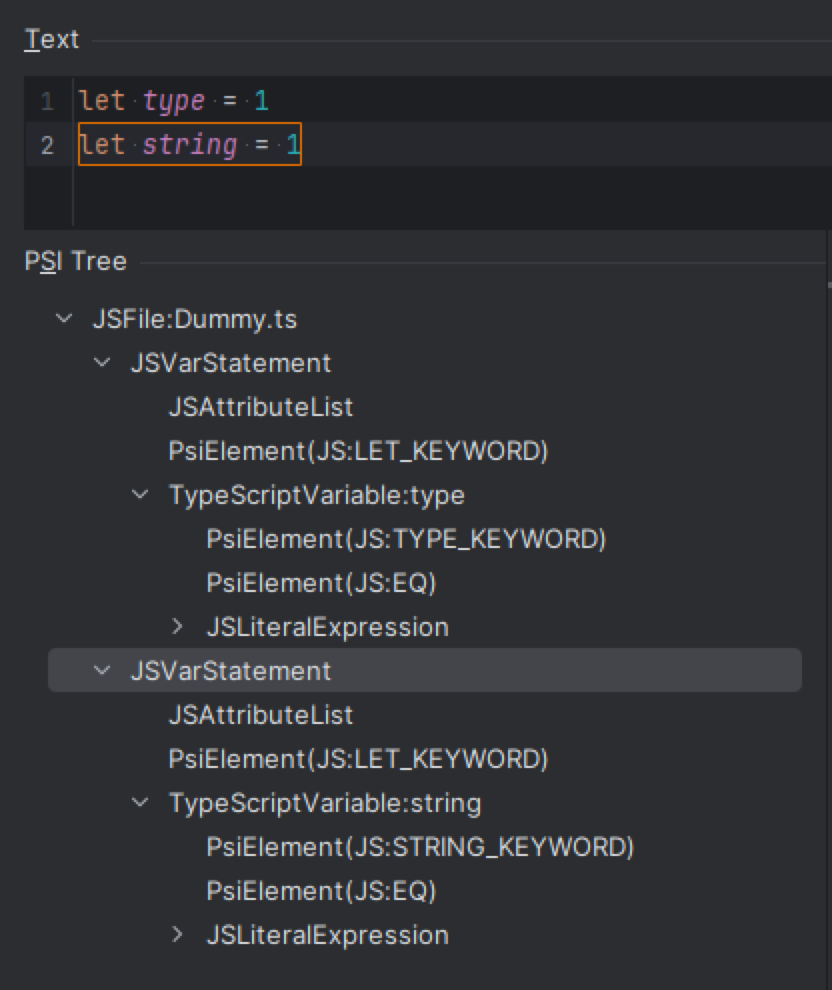
#3: The third way is to lex soft keywords as identifiers and then assign a keyword element while parsing.

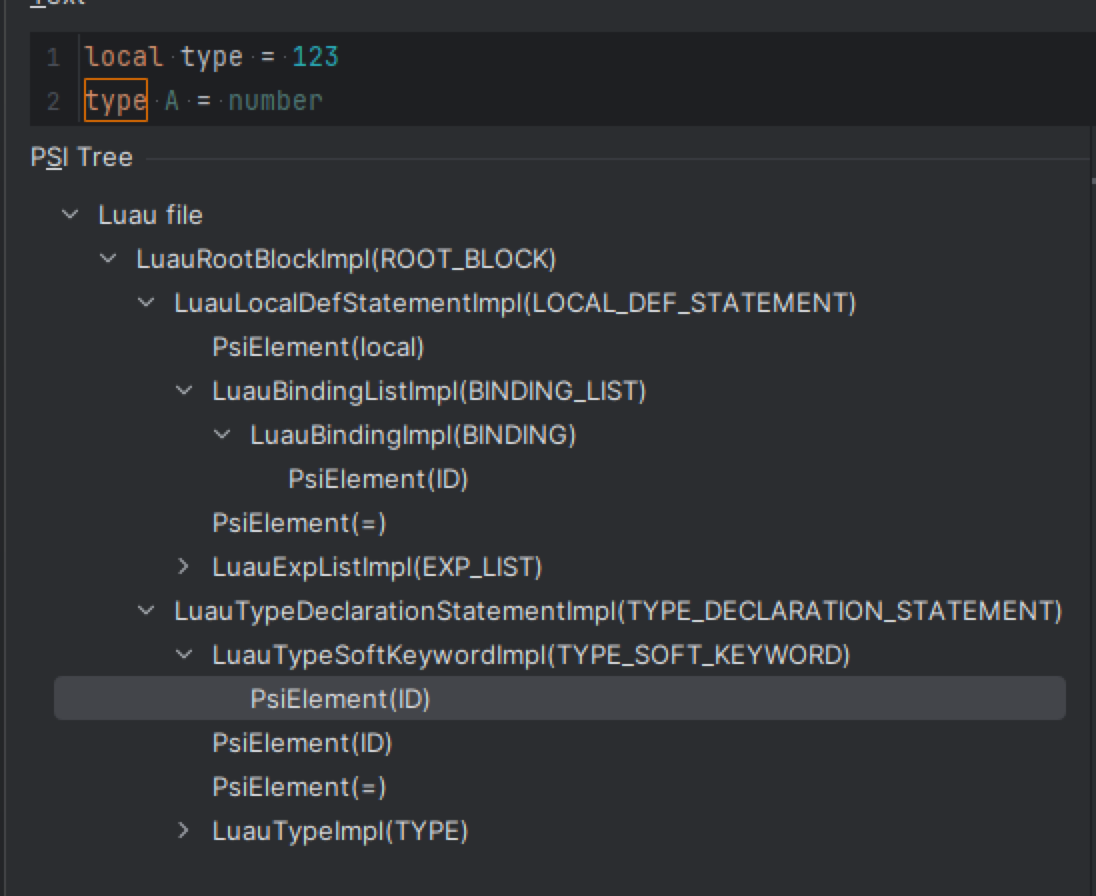
#4: Rust also lexes soft keywords as identifiers but then remaps the tokens while parsing, generating no extra wrappers.

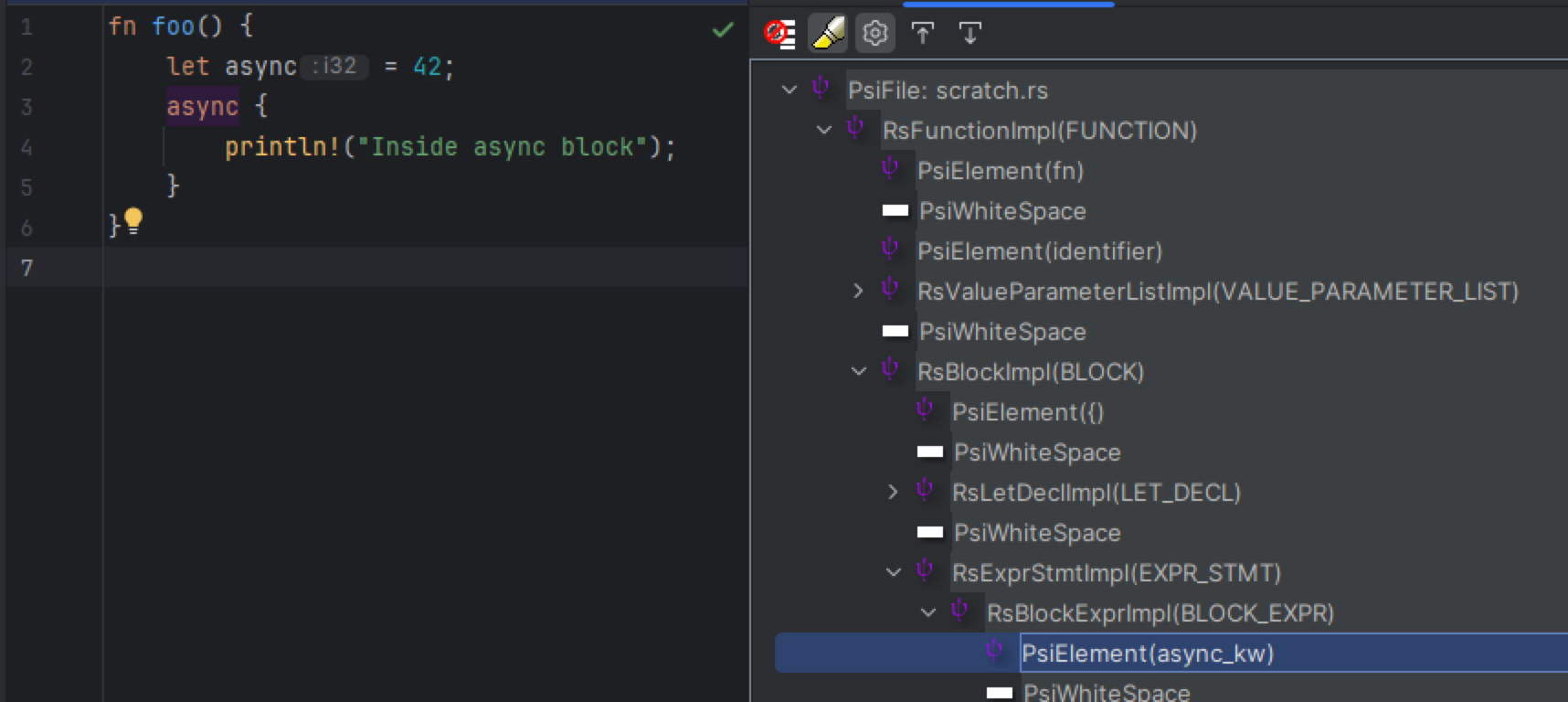
One can ask what are the advantages/disadvantages of these? Usually, the fewer PSI elements you have, the better. Ranked using this metric, option 2 with TypeScript and option 4 with Rust win.
That said, remapping tokens is slightly tricky (it’s one method call, and you shouldn’t use these token rules in recovery logic, source).
I believe there are more complicated parts of the lexer I didn’t have to deal with. For example, supporting multiple language versions. And with that happy note, let’s move to the parser.
Parser
Writing a good parser is an iterative process. It took me quite a number of iterations to make something useful, and there are still occasional bugs. (Just a week ago, I found a situation where my recovery rule led to incorrect parsing for a rare case that I hadn’t encountered for a year).
That said, our goals when crafting a good parser are straightforward. We want something that is:
- Correct.
- Resilient to errors. For instance, it should not make the rest of the file invalid if you made a typo.
- Fast. You won’t reach the speed of a new frontend framework development, but you can at least try.
- Well-structured for all future PSI manipulations as almost all features rely on the PSI tree.
There are several resources that may help you:
- The GrammarKit docs and plugin. Especially the “how to”, it’s somehow more informative than the tutorial itself.
- The official grammar of your language, if there is one. I was lucky!
- Examples in languages with similar features (see the languages mentioned in the GrammarKit README).
As with the lexer, I won’t dwell on the whole process, but rather, I’ll highlight the things I found interesting or confusing.
First of all, I strongly recommend that you start writing tests as soon as you’ve reached the point of parsing the average program (or earlier). Setting up tests takes 4 lines of code, but it saves a lot of time when you start refactoring or fixing your grammar. If you fail to do this, it’s easy to miss when fixing one part of your code breaks another (this happened to me several times). For my part, I split tests into three categories: correct code, incorrect code, and recovery rules.
The order you write the rules is important
Here’s a simple but important rule: when multiple grammar rules share a common prefix, the longer one should come first.
For instance, if you have T and T... as two different types of nodes, never put T first. Though this is an obvious thing, I managed to shoot myself in the foot several times. At one point, I wrote this masterpiece to parse generic arguments with defaults:
generic_type_list_with_defaults ::=
generic_type_pack_parameter_with_default (',' generic_type_pack_parameter_with_default)*
| ID '=' type (',' generic_type_list_with_defaults_only)?
| generic_type_pack_parameter (',' generic_type_pack_parameter)* (',' generic_type_pack_parameter_with_default)*
| ID (',' generic_type_list_with_defaults)?
private generic_type_list_with_defaults_only ::=
generic_type_pack_parameter_with_default (',' generic_type_pack_parameter_with_default)*
| ID '=' type (',' generic_type_list_with_defaults_only)?The rules are simple:
- Type pack (
D…) with defaults can only be followed by other type packs with defaults. - Usual defaults can only be followed by other defaults.
- Type packs without defaults can only be followed by other type packs or type packs with defaults.
- Regular types (no defaults, no packs) can be followed by anything.
The most complete example is like this:
type A<B, C=U, D...=...E> = UDid you spot the error in the rule I gave? I didn’t. At least not until I wrote a test. (And yes, the rule names are awful, ha!) The issue is in the third branch. Here’s a simplified version (if rule names can have not only letters and underscores, the world would be better):
"A..." (',' "A...")* (',' "A...=...A")*I wrote it that way because I wanted to avoid adding more branches, and it reflected the exact order in which the types are allowed. But here’s the catch: we already know the parser doesn’t backtrack once a rule matches. So if you feed it B..., D...=...E, it happily parses B..., D... and commits the result, then starts complaining that = is unexpected. Which, to be fair, is exactly what I told the parser to do.
The fix was to add branching and try the defaults first. Was it the best fix? A better approach would probably be to ignore these cases in the grammar and handle them later by analyzing the PSI. The original grammar doesn’t enforce the order anyway, and the errors really belong at the type level. I was just being stubborn trying to catch them in the grammar.
When you need to do manual parsing
There are times when you’ve battled with the parser grammar for so long that it seems easier to write a custom parser rule. And you can be right. Personally, I tried to leave as much basic stuff to the parser I didn’t want to go too deep with understanding the parser and its internal implementation magic. (I did spend quite some time debugging the parser, and the number of cases handled there is …impressive).
So, as an example, one case where I gave up on the grammar is with expression statements. Most languages are fine with your writing a line consisting only of an expression 2 + 2 (e.g. Python), but the only expression allowed as a statement in Lua(u) is a function call.
This rule makes sense as a way to prevent errors where you just forgot to call the function or assign the result to a variable. But it doesn’t simplify parsing.
I went through a long process building out expression parsing in general. I started with a naive approach that closely followed the language grammar, then kept tweaking it until it more or less worked. Eventually, I ended up implementing a proper solution that compiles down to a Pratt parser under the hood.
This is what I wanted to end up with:
expression_statement ::= func_call
expression ::= func_call | index_access | other_expressionsOnly a function call should be allowed as a statement. We can start simple and try to write two rules like this:
func_call ::= base (index_access_postfix | func_call_postfix)* func_call_postfix
index_access ::= base (index_access_postfix | func_call_postfix)* index_access_postfixDoes it work? Nope, because the parser is greedy, so it will eat all the segments of the expression and find nothing for the last part and match neither of these rules. If we make the last segment optional, then it will always parse the one that goes first. There are people who think that parser may work like regexes and say: but we have a non-greedy modifier, it should make parser to match everything and then backtrack and try to match the last part of the rule as well.
func_call ::= base (index_access_postfix | func_call_postfix)*? func_call_postfix
index_access ::= base (index_access_postfix | func_call_postfix)*? index_access_postfixDoes it work? Again, nope. The parser isn’t a sophisticated regex engine, it’s much simpler in that aspect, and it doesn’t support non-greedy matching. Does it generate a valid parser? Yes. It just throws away everything starting from the ?, leaving you with two identical rules. (This was a real “bug” in another language parser, which was hidden because these two rules were merged into the func_call_or_index_access ::= func_call | index_access anyway.)
So, where does that leave us? Maybe there is a clever trick I haven’t found, but for now, I ended up with a solution that also resolves two other problems. The first one is that both index access and function call have a lot in common:
local a = a[1][2]()[23]
-- Magic: () turn the whole chain into a function call
local a = a[1][2]()[23]()When we have two separate rules for the cases above, the parser will try them one by one. It will parse almost the entire expression, be satisfied that it found index access, and then error out because a function call is required. After that, it will start over from the beginning and try to match the function call instead. This might not seem like a big deal, but in some situations, it can lead to an exponential number of retries. I’ll go into a specific example later.
The second problem is scope selection. Remember, I mentioned that many features are built on top of the PSI. The scope selection I’m used to requires each new index access or function call to be nested inside the previous one. Since both operations are left-associative, the rightmost part should contain the entire left-hand side as a separate node, along with the arguments.
document.body.appendChild(script)
# The call above generates the following tree
JSCallExpression
JSReferenceExpression:appendChild # document.body.appendChild
JSReferenceExpression:body # document.body
JSReferenceExpression:document
PsiElement(JS:DOT)
PsiElement(JS:IDENTIFIER) # body
PsiElement(JS:DOT)
PsiElement(JS:IDENTIFIER) # appendChild
JSArgumentList # (script)A parsing rule like this gives you a plain structure, which causes scope selection to first select the identifier and then the entire expression.
func_call_or_index_access ::= (index_access_postfix | func_call_postfix)*The rule below gives you a right-associative structure (no surprise there):
func_call_or_index_access ::= (index_access_postfix | func_call_postfix) func_call_or_index_accessHowever, left recursion is not allowed, so this approach won’t work for left-associative constructs. In this case, we’ll have to beg for the modifiers’ help. left enters the scene, it takes the node on the left and becomes its parent, which is exactly what we need here:
private index_or_call_expr ::= base (index_access | func_call)+
// These are postfixes. Not actual access and call, but since they are left and take over the index_or_call_expr above the names suit it well
left index_access ::= '['index']'
left func_call ::= '('args')'The last problem to solve is the one we started with, we need to allow only one of these two. Manual parsing it is:
expression_statement ::= <<parseExprStatement index_or_call_expr>>fun parseExprStatement(builder: PsiBuilder, l: Int, indexAccessOrFuncCallParser: Parser): Boolean {
val result = indexAccessOrFuncCallParser.parse(builder, l)
if (result && !isFunctionCall(builder)) {
builder.error("Expected function call, got index access")
}
// Since there are no other rules to try if it's parsed as func call or
// index access we just return the original result
return result
}It’s unclear if this is the “correct” way to report the error, but it seems to work fine so far!
Wrapping up the manual parsing section—it’s quite widespread. Almost every plugin does it, whether for cases similar to mine, to add custom error messages, to reparse tokens (as discussed in the soft keywords section), or to implement lazy parsing of expressions. (That last one is looming over me; I have a feeling I’ll need it, but I’ve yet to dig into how it works.)
Parsing performance
Luau, as a typed language, supports type casts written like value :: Type. When I was rewriting my expression parser, I split type casts into a separate rule that looked like as_expr ::= subset_of_expressions :: type. I placed this rule before the one for parsing simple expressions, based on the “the longer rule should come first” principle we discussed earlier.
At first, it seemed to work fine. But later, while writing tests involving deeply nested tables, I noticed that adding a new table caused a noticeable slowdown. So, using the Early Access Preview of IntelliJ IDEA (since the profiler requires the paid version), I ran a performance test on the plugin—and got quite a beautiful result.

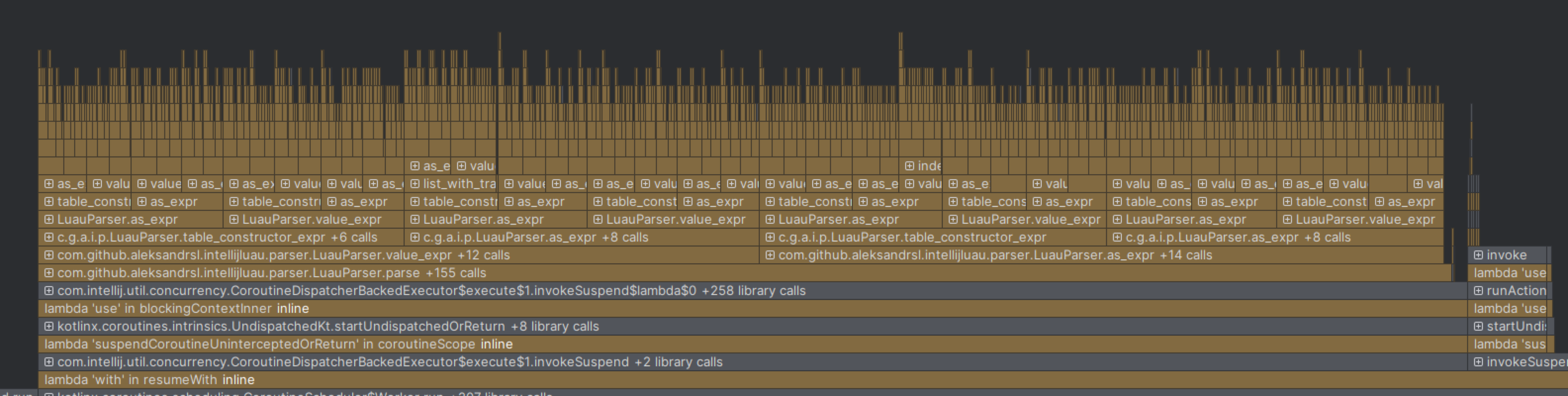
The problem is the one that I mentioned when talking about parsing function calls.
So, since I had rules similar to this:
expression ::= as_expr | value_expr
as_expr ::= value_expr '::' typeThis meant the parser would always try to match a type cast (as_expr) first. When it encountered a nested expression, it would again try to parse it as a type cast, and this would repeat as deeply as the nesting went. At the deepest level, the type cast would fail, so the parser would fall back to value_expr and reparse that part.
So far, that’s fine; only a small piece of code gets reparsed. But then, going up one level, the parser tries as_expr again, fails, and reparses the same child expression as value_expr, discarding the previous result. This means the same code gets reparsed four times. As you go up more levels, the same thing happens again and again, leading to an exponentially increasing number of reparses.
The fix for cases like this depends on the situation. Here it was trivial, I should have used the left modifier that had already saved me once before:
expression ::= value_expr
value_expr ::= value as_expr?
left as_expr ::= '::' typeWith this, no more reparsing, and we just parse the value. Also, if there is a type cast at the end, the parser will wrap the resulting node with it.
I later found two more similar performance problems, one was union/intersection types, and the second was the parsing of function types and parenthesized expressions.
With algebraic types I used almost the same approach using linear parsing instead of recursive and setting the wrapping PSI element with an upper modified. Function types: (number, number) -> ()- and parenthesized types: (number, number) have the same prefix as well, but in this case using the left modifier on -> (). Wrapping the parenthesized part felt too weird, because they are unrelated, so I ended up writing a custom parsing function that checks that the -> token follows a closing ). This is not necessarily a great approach, but it is definitely more performant than exponential reparsing in the worst cases.
Error recovery
The next important feature is error recovery.
Error recovery allows parsers to keep working even when the code being parsed contains syntax errors. So, instead of giving up at the first sign of trouble, the parser tries to recover by skipping parts of the input so it can continue building a usable structure from the rest of the file.
While it’s easy to mark everything after the first error as invalid, that approach isn’t very useful—neither for compilers nor for IDEs. In fact, it’s even worse for IDEs, because, as you’re typing, one small mistake can cause the rest of the file to be flagged as broken, even if most of the code is fine.
Error recovery in IntelliJ parsers relies on two main mechanisms: pins and recovery rules. Both are simple in concept, but it takes time to get used to how they work. Pinning a rule at a specific element means that once the parser reaches that element, it won’t go back and try to parse another rule, it will commit the current one and show an error.
Usually, a parse function looks like this:
// '(' type ')'
public static boolean parenthesised_type(PsiBuilder b, int l) {
if (!nextTokenIs(b, LPAREN)) return false;
boolean r;
r = consumeToken(b, LPAREN);
r = r && type(b, l + 1);
r = r && consumeToken(b, RPAREN);
return r;
}Here, each token is matched in sequence, but if any fail, the entire rule fails, and the parser backtracks to try a different rule. However, in many cases, we can be fairly certain that the user is attempting to write this specific construct. In those situations, it’s more helpful to report an error related to this rule instead of trying other alternatives.
For example, when we are parsing type declaration where the user has entered the type keyword, we are 100% sure that this has to be a type declaration (funny enough, I’ve just realized there are cases where a statement starting with type doesn’t mean type declaration, but let’s pretend it’s a correct assumption). Then, we pin the rule on the type keyword and the code generated for it looks like this:
public static boolean type_declaration_statement(PsiBuilder b, int l) {
boolean r, p;
r = type_declaration_statement_0(b, l + 1);
r = r && type_soft_keyword(b, l + 1);
p = r; // pin = 2
r = r && report_error_(b, consumeToken(b, ID));
r = p && report_error_(b, type_declaration_statement_3(b, l + 1)) && r;
r = p && report_error_(b, consumeToken(b, ASSIGN)) && r;
r = p && type(b, l + 1) && r;
return r || p;
}See that the conditions to parse the tokens following the pinned one do not depend on the result (r) as in the code above, but rather use the pin (p) check. Thus, if we type type 243 would be ID or function expected, got 234 and not something random after trying to match the rest of the rules we have in the grammar and giving the error for the last one.
recoverWhile is also dead simple, as it’s said in the docs: “it matches any number of tokens after the rule matching completes with any result”.
The any result part is the most important. It means that even if the rule has been parsed successfully, the error recovery still kicks in. Most of the time rules for recovery are predicates with negation, as seen here:
private statement_recover ::= !('local' | 'ID' | function | ';' | 'end' | 'until' | 'elseif' | 'else' | ... )
This will match all the tokens except for the ones mentioned and won’t consume them, they still can be used by other rules.
Taken together with the rules like this:
root_block ::= (root_statement_with_recover ';'?)*
private root_statement_with_recover ::= !('return' | <<eof>>) statement { pin = 1 recoverWhile = statement_recover }…we get the following behavior: if a rule has been successfully parsed (or parsed with an error and has a pin) we will continue skipping all the tokens until the recovery rule matches, in our case until we reach a token that is mentioned inside the rule.
So, with these rules, the following code will show the error in the first statement at ) then skip 123 and the second statement will be parsed completely normally:
local error = )123
local normal = 123Without error recovery, everything after the = wouldn’t be parsed into meaningful structures and kept as tokens instead.
The main problem here is the possible incompleteness of the recovery rule. If you skip something that marks the beginning of the next rule, you lose. For example, if you miss the end token from the recover rule for the statement, you make a lot of your code incorrect; let’s take the following snippet:
local function test()
local test = 213
end
local normal = 123When the parser processes local test = 213 inside the function, it successfully parses the assignment statement. However, the recovery rule still kicks in, and the parser starts scanning the following tokens against the recovery rule. Since end isn’t included, the parser flags it as unexpected and moves on. When it reaches local, which is in the recovery rule, it stops recovery and starts parsing a new statement.
In some places, recovery rules become so large that I sometimes wonder if it even makes sense to implement 😅. In fact, one of the latest bugs I ran into was caused by a recovery rule that forgot to include the elseif token. So be careful!
Let’s wrap up this section on parsing with one interesting technique I spotted in the Rust parser, which I found quite helpful when you have nothing else to pin …pinning with a negative predicate, which looks like this:
table_constructor ::= '{' field_with_recover* '}' { pin = 1 }
// Here 1 is the negative predicate
table_field ::= !'}' field (field_sep | &'}') { pin = 1 recoverWhile=rule }That means that until we encountered the closing } everything is considered a table field. Since IDEs usually insert parentheses or braces in pairs, this technique improves error handling inside the block and also keeps all the errors confined to that same block.
With the table field pin, the incorrect code below is parsed as a table with an incorrect field. The parser recovers and completes the table, giving a much better error message. Without it, the whole thing turns into a sloppy mess—table_field isn’t parsed, and since there’s nothing to pin, the parser backtracks and tries to parse other constructs:
local test = { a: 451 } -- should be { a = 451 }, but : is used in types and I always mistake themI’m sure there are many improvements I can make to my parser, not least of which are the error messages—since there is still work to do there.
Other features and IDE integration pitfalls + hints
This section walks through some more basic advice not as structured because I’m still working on these features.
Understanding reference resolution
We’ve spent so much time on the lexer and parser, not because they are hard, but because I was able to shape my understanding of them, while a lot of other features are ad-hoc.
So far, I’ve implemented basic reference resolution within a file for both types and variables, along with code completion based on them.
The “worst” part is that implementations start to depend heavily on your language and your goals. You can implement features however you’d like, as long as you implement the required methods from the basic interfaces. Looking at other plugins plunges you into depression, and you start thinking that you also need several thousand lines of code you don’t fully understand to make it all work. And yes, you also need this shiny custom cache for references because, for sure, Rust people know what they’re doing (Spoiler, you don’t need it).
Additionally, in reality you also don’t need a reference resolution if you have an LSP since it can do this work for you. I battled with it mostly out of sheer interest.
The main takeaways from the process are trivial: read the docs and ask the community.
Implementing PsiNameIdentifierOwner
Whenever you place the cursor on a variable-like element, the IDE highlights its usages. This mechanism is more advanced than what VSCode offers—it doesn’t just highlight matching words. For this to work, the reference resolution must be implemented. (Remember when I said you don’t need it if you have an LSP? Well, for this feature, you do need it 😹—or at least, I haven’t figured out how to configure it through LSP.)
The first step is declaring PSI elements that introduce new variable names. The relevant interface is PsiNameIdentifierOwner. Once you read about it in the docs, you can go ahead and implement it—it’s straightforward. Just override the required methods and fill in a couple lines of code.
Later, I discovered that function usages were highlighted when the cursor was placed on the local keyword—but not when it was placed on the function name itself.

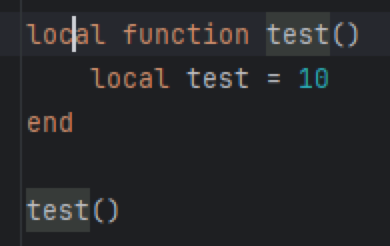
Fixing highlight bugs with getTextOffset
Now it’s time to read the docs and surprise surprise, the docs for thePsiNameIdentifierOwner interface code say this:
Implementors should also override PsiElement.getTextOffset() to return the relative offset of the identifier token.
The names of the interface methods were so descriptive I never opened the interface docs. Apart from highlighting, this method is also responsible for placing your cursor in the correct position when you hit go to definition. Once you implement getTextOffset, everything starts working fine.
Performance pitfalls and file listeners
I was integrating a standalone tool to help the LSP resolve references and got confused about whether to use BulkFileListener or the newer AsyncFileListener. I asked for help on the JetBrains platform and got not only the answers I needed, but also an extra performance tip: file.fileType can be slow, as it uses multiple mechanisms to determine the file type. In performance-critical code running on the UI thread, FileTypeRegistry.getInstance().getFileTypeByFileName(file.getPath()) is usually faster. This is mentioned in the documentation—but only if you read it carefully.
Using languages as language injections or not
Speaking of reading the docs, study the examples closely. The custom language support tutorial is written for the language that integrates into Java, so for instance, the reference contributor is using a specific mechanism to get references from other languages. If your language is standalone, you likely don’t need it.
Code formatting
Formatting was another challenge. I still don’t get what is so smart about Indent.getSmartIndent and every other plugin uses it and the normal indent seemingly random. I ended up writing a formatter that’s at least tolerable and also integrated a standalone formatter that’s popular in the community. That wasn’t trivial either—you can look at how the Prettier plugin works or how the Rust plugin handles integration with rustfmt as an example.
Integrating the LSP and managing plugin settings
We’ve come the full circle to the LSP mentioned in the beginning. This section covers how I approached LSP integration, user settings, and the quirks I ran into—plus how I worked around them.
Choosing how to bundle your LSP
So, how does one integrate their LSP? If it is a Node package, and you’re building a plugin for WebStorm, you can reuse the infrastructure created by its team: com.intellij.lang.typescript.lsp.LspServerPackageDescriptor. Otherwise, you implement the standard com.intellij.platform.lsp.api.LspServerSupportProvider.
You also need an LSP executable. When you have an LSP that runs cross-platform, you can bundle it into your plugin files. If it’s a binary that should be chosen based on the platform, you’ll need to decide how to handle that. The easiest way is to bundle all the versions, but this has the cost of increasing the weight of your plugin and requires frequent updates to keep in sync with LSP. Alternatively, you can either ask users to provide the path for the LSP binary or implement an auto-download system.
I’ve chosen the first way, and it worked fine for a year as the plugin is still in closed beta. However, it’s not the best UX, since most JetBrains plugins work out of the box. This is why I eventually implemented the download system.
Building the UI for download and version control
As you’ve probably realized by now, I don’t always choose the easiest route. I thought: instead of just always using the last version, what if I want to let users pick the LSP version—but also offer the option to always stay on the latest one? I don’t want to download extra files unnecessarily (limited mobile traffic traumatized me), so I should prompt the user first.
I spent quite a bit of time figuring out the UI settings. Building a customized dropdown wasn’t straightforward (to save you some time: use GroupedComboBoxRenderer in older versions of IntelliJ, or com.intellij.ui.dsl.listCellRenderer in the newest ones).
I ended up with a UI that downloads the LSP when you click the download section. To keep things simple, I also show the user the folder where the LSP files are stored, in case they want to remove them manually:

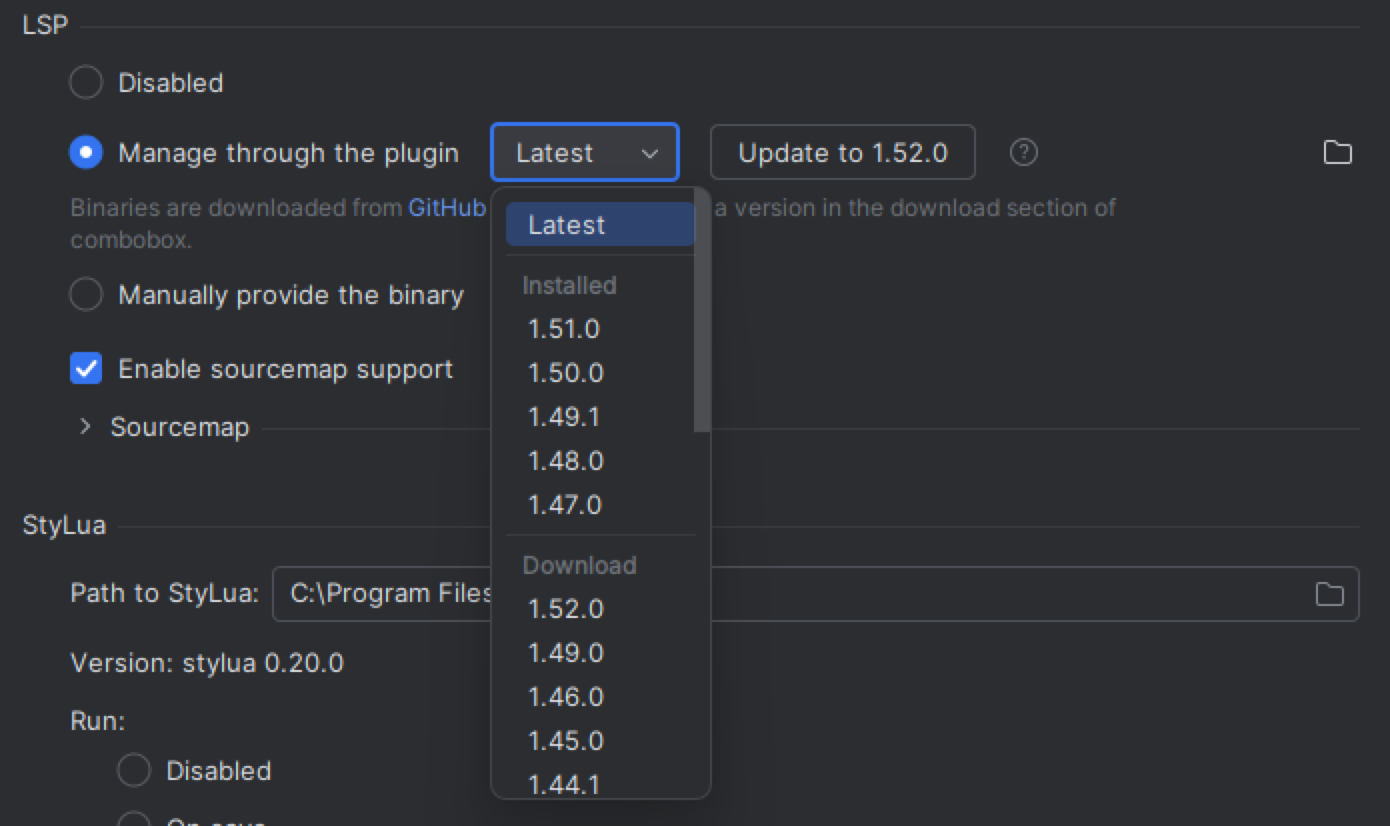
A note for React developers
Most of the settings UI examples I saw in other plugins are imperative, which can come as a shock to a React sweet summer child. There is a bunch of stuff around com.intellij.openapi.observable.properties that looks suitable for reactive UI updates, but I found little use for it.
Working around missing source access
Another funny obstacle was figuring out how to get the sources for LSP-related code. Most of the documentation is there, but the usual “Download Sources” button doesn’t always work for these specific classes (there are issues). So for a whole year, I thought what I was seeing was all that existed. You can imagine my surprise when I finally attached the correct sources and discovered the full documentation 😂.
Learning how LSPs work (by force)
When working with LSP, you just inevitably learn how they work. For example, you may need to configure it both with CLI arguments at startup or via the workspace configuration. You may even have to make your first proud contribution to the C++ codebase adding serverInfo which is a built-in way for the LSP to share its name and version after initialization to have this information appear in the IDE widget.
Beware bugs and silent failures
You’re not immune to random bugs either. After updating to 2025.1, the IDE stopped showing LSP errors. The issue boiled down to a minor change in the LSP default configuration. This was supposed to pave the way for the new better error retrieval mechanism, but since the feature is still experimental, it isn’t turned on. However, the configuration change signaled to the LSP that the old mechanism should be turned off. As a result, I stopped receiving any errors at all.
LSP as an optional dependency
Since LSPs are supported mostly in the paid IDE versions, it’s possible to have it as an optional dependency. If the LSP isn’t available, you can fall back to manual reference resolution and the contributions you’ve implemented.
Overall, working with LSPs and standalone tooling feels a bit different because it involves another platform infrastructure, coroutines, and services you’ll need to get comfortable with.
Finale
Summing things up: building a plugin is not that hard, and you have places to ask for help. There are sophisticated features, but there are features like breadcrumbs and sticky lines adding the real value and easy to implement. The hardest part was just figuring out what they’re called so I could find the documentation.


That’s what you get. The actual implementation? Around 20 lines of code.

Finally, here’s a guide on how to publish the plugin.
Don’t be put off on building your own plugins! (But if you still are, reach out to Evil Martians!)
