What could Go wrong with a mutex, or the Go profiling story


Imagine your Go service has somehow become stuck: requests are no longer being served and the metrics remain constant. Something’s gone wrong! But how can you solve this puzzle? If no profiling tools were included in the build, the first thing which comes to mind is to generate and then analyze a crash dump file. Does that sound like yet another puzzle for you to solve? No worries. Just stay tuned, because in this article, I’ll show you how to do just that!
The Go ecosystem provides plenty of profiling tools to help you identify performance bottlenecks and localize potential bugs. I can’t imagine working on a Go project without having pprof and gops in my toolbelt. They help me a lot whenever I’m developing in a local environment. In production, however, we usually don’t include profiling agents. And of course, sometimes weird things manage to occur exclusively in the real world.
Recently, we performed stress testing for a production AnyCable installation (our powerful WebSocket server for Ruby apps written in Go). Everything went according to a plan (alerts were triggered, pods auto-scaled, and so on). But, while examining the metrics after one of our test runs, I noticed some suspicious behavior:

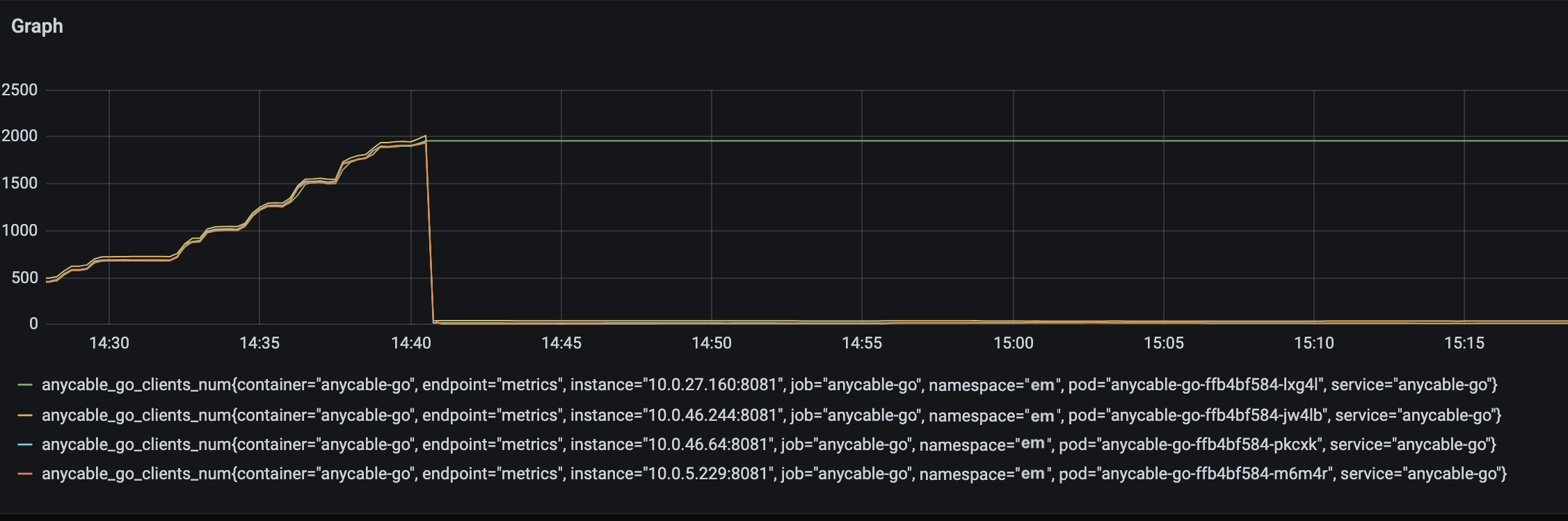
AnyCable Grafana dashboard
The test had finished, but one of the pods was still reporting a huge number of connected WebSockets. And this number wasn’t changing. Why?
I looked at the other metrics and found even more anomalies: no outgoing messages were being sent and no broadcasts were being transmitted. It’s as if someone had just pushed the pause button. Or, as it turned out, a deadlock had occurred as a result of improper usage of sync.RWMutex.
There is no Go without mutexes
Before talking about the actual profiling, let me provide a simplified example of the code in question.
There is a single point of failure unit in the AnyCable server, Hub, which is responsible for routing messages to connected clients. Every client has a unique ID and a list of subscribed streams. In any particular stream, whenever a message appears, we should get a list of its associated clients and then send the message to their sockets. We use a Go map to store the stream-to-clients mapping, and since clients’ subscriptions and data broadcasting are happening concurrently, we need a mutex to avoid race conditions when accessing this map. Finally, we know that we read from this map more often than write into it, so the read-write mutex (sync.RWMutex) is used:
type Hub struct {
// Maps client IDs to clients.
clients map[string]*Client
// Maps streams to clients
// (stream -> client id -> struct{}).
streams map[string]map[string]struct{}
// A goroutine pool is used to do the actual broadcasting work.
pool *GoPool
mu sync.RWMutex
}
func NewHub() *Hub {
return &Hub{
clients: make(map[string]*Client),
streams: make(map[string]map[string]struct{}),
// Initialize a pool with 1024 workers.
pool: NewGoPool(1024),
}
}
func (h *Hub) subscribeSession(c *Client, stream string) {
h.mu.Lock()
defer h.mu.Unlock()
if _, ok := h.clients[c.ID]; !ok {
h.clients[c.ID] = c
}
if _, ok := h.streams[stream]; !ok {
h.streams[stream] = make(map[string]map[string]bool)
}
h.streams[stream][c.ID] = struct{}{}
}
func (h *Hub) unsubscribeSession(c *Client, stream string) {
h.mu.Lock()
defer h.mu.Unlock()
if _, ok := h.clients[c.ID]; !ok {
return
}
delete(h.clients, c.ID)
if _, ok := h.streams[stream]; !ok {
return
}
delete(h.streams[stream], c.ID)
}
func (h *Hub) broadcastToStream(stream string, msg string) {
// First, we check if we have a particular stream,
// if not, we return.
// Note that here we use a read lock here.
h.mu.RLock()
defer h.mu.RUnlock()
if _, ok := h.streams[stream]; !ok {
return
}
// If there is a stream, schedule a task.
h.pool.Schedule(func() {
// Here we need to acquire a lock again
// since we're reading from the map.
h.mu.RLock()
defer h.mu.RUnlock()
if _, ok := h.streams[stream]; !ok {
return
}
for id := range h.streams[stream] {
client, ok := h.clients[id]
if !ok {
continue
}
client.Send(msg)
}
})
}The implementation of GoPool is beyond the scope of this article. It’s enough to know that pool.Schedule blocks if all workers are busy and the internal pool’s buffer is full.
Take a closer look at the Grafana chart above. You can see that the problem occurred when we disconnected thousands of connections simultaneously (in this particular situation, it was because an out-of-memory exception had crashed our benchmarking client 💥).
I pulled the same Docker image we used in production. Then, running locally, I started attacking it using the same k6 scenerio. After a long siege, I managed to reproduce the bug, and my AnyCable server became unresponsive.
One goroutine dump, please
Here’s a question: how can we see what’s happening inside an arbitrary Go process? Or, more precisely, how can we see what all the goroutines are doing at any given moment? If we could crack that, it could help us figure out why they’re not processing our requests.
Luckily, every Go program comes with a solution out of the box with the default SIGQUIT signal handler. Upon receiving this signal, a program prints a stack dump to stderr and exits.
Let’s see an example of how it works:
// example.go
package main
func main() {
ch := make(chan (bool), 1)
go func() {
readForever(ch)
}()
writeForever(ch)
}
func readForever(ch chan (bool)) {
for {
<-ch
}
}
func writeForever(ch chan (bool)) {
for {
ch <- true
}
}Let’s run this program and terminate it by sending a SIGQUIT via CTRL+\:
go run example.go
// CTRL+\
^\SIGQUIT: quit
PC=0x1054caa m=0 sigcode=0
goroutine 5 [running]:
main.readForever(...)
/path/to/example.go:15
main.main.func1()
/path/to/example.go:7 +0x2a fp=0xc0000447e0 sp=0xc0000447b8 pc=0x1054caa
runtime.goexit()
/path/to/go/1.17/libexec/src/runtime/asm_amd64.s:1581 +0x1 fp=0xc0000447e8 sp=0xc0000447e0 pc=0x1051f41
created by main.main
/path/to/example.go:6 +0x70
goroutine 1 [chan send]:
main.writeForever(...)
/path/to/example.go:21
main.main()
/path/to/example.go:10 +0x85
// some Assembly registers
exit status 2We can see that one goroutine is executing readForever while another one is sending data to a channel within writeForever. No surprises.
If the running Go process doesn’t have a terminal attached, we can use the kill command to send the signal:
kill -SIGQUIT <process id>For Docker, we need to send SIGQUIT to the running container. No problem:
docker kill --signal=SIGQUIT <container_id>
# Then, grab the stack dump from the container logs.
docker logs <container_id>For the minimal example above, the Dump (yeah, capital “D”) only contained a couple of goroutines and a dozen lines of text. However, with the production project we’ve been looking at, the file contained 4663 goroutines and ~70K LOC—that’s not exactly something that’s easy to digest with just a quick once-over. Let’s find a robot to help us with that.
Introducing goroutine-inspect and digging into RWMutex internals
After a quick GitHub search, I was able to find a tool called goroutine-inspect. It’s a pprof-style interactive CLI, which allows you to manipulate stack dumps, filter out irrelevant traces, or search for specific functions.
Using goroutine-inspect
Below is the list of actions I performed, and the final couple of goroutines, which finally shed light on the problem:
# First, we load a dump and store a reference to it in the 'a' variable.
> a = load("tmp/go-crash-1.dump")
# The show() function prints a summary.
> a.show()
\# of goroutines: 4663
IO wait: 7
chan receive: 1029
chan send: 2572
idle: 1
select: 12
semacquire: 1041
syscall: 1One of the most useful features of goroutine-inspect is the dedup() functions, which groups goroutines by their stack traces:
> a.dedup()
# of goroutines: 27
IO wait: 5
chan receive: 5
chan send: 1
idle: 1
select: 8
semacquire: 6
syscall: 1Wow! This time we ended up with just 27 unique stacks! Now we can scan through them and delete the irrelevant ones:
> a.delete(...) # delete many routines by their ids
# of goroutines: 8
chan send: 1
select: 2
semacquire: 5After dropping all the safe goroutines (HTTP servers, gRPC clients, etc.), we ended up with the final eight. My eyes caught multiple traces containing the broadcastToStream and subscribeSesssion functions. Why hadn’t they been deduped? Let’s take a closer look:
> a.search("contains(trace, 'subscribeSesssion')")
goroutine 461 [semacquire, 14 minutes]: 820 times: [461,...]
sync.runtime_SemacquireMutex(0xc0000b9380, 0x8a, 0xc0035e9b98)
/usr/local/Cellar/go/1.17/libexec/src/runtime/sema.go:71 +0x25
sync.(*Mutex).lockSlow(0xc000105e68)
/usr/local/Cellar/go/1.17/libexec/src/sync/mutex.go:138 +0x165
sync.(*Mutex).Lock(...)
/usr/local/Cellar/go/1.17/libexec/src/sync/mutex.go:81
sync.(*RWMutex).Lock(0x8d27a0)
/usr/local/Cellar/go/1.17/libexec/src/sync/rwmutex.go:111 +0x36
github.com/anycable/anycable-go/node.(*Hub).subscribeSession(0xc000105e00, {0xc003f83bf0, 0x15}, {0xc0021c8b40, 0x478f5e}, {0xc00364b790, 0xc5})
/Users/palkan/dev/anycable/anycable-go/node/hub.go:281 +0x85
goroutine 88 [semacquire, 14 minutes]: 1 times: [88]
sync.runtime_SemacquireMutex(0xc005e6bb60, 0x0, 0xc002e9d1e0)
/usr/local/Cellar/go/1.17/libexec/src/runtime/sema.go:71 +0x25
sync.(*RWMutex).Lock(0x8d27a0)
/usr/local/Cellar/go/1.17/libexec/src/sync/rwmutex.go:116 +0x71
github.com/anycable/anycable-go/node.(*Hub).subscribeSession(0xc000105e00, {0xc003716138, 0x15}, {0xc00231e640, 0x478f5e}, {0xc0035911e0, 0xc5})
/Users/palkan/dev/anycable/anycable-go/node/hub.go:281 +0x85Here, 820 (❗) routines are trying to acquire a write lock, and that’s all fine. But what is the lone routine in rwmutex.go:116 doing? Let’s take a look at the source code of RWMutex:
// Wait for active readers.
if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 {
runtime_SemacquireMutex(&rw.writerSem, false, 0)
}It’s waiting for active readers. 🤔 But why don’t our readers release the lock? It’s time to take a look at the broadcastToStream function:
> a.search("contains(trace, 'broadcastToStream')")
goroutine 515 [semacquire, 14 minutes]: 13 times: [515, ...]
sync.runtime_SemacquireMutex(0xc0004e0de0, 0xc0, 0xc0010de318)
/usr/local/Cellar/go/1.17/libexec/src/runtime/sema.go:71 +0x25
sync.(*RWMutex).RLock(...)
/usr/local/Cellar/go/1.17/libexec/src/sync/rwmutex.go:63
github.com/anycable/anycable-go/node.(*Hub).broadcastToStream.func1()
/Users/palkan/dev/anycable/anycable-go/node/hub.go:355 +0x8b
github.com/anycable/anycable-go/utils.(*GoPool).worker(0xc0001fc1b0, 0x0)
/Users/palkan/dev/anycable/anycable-go/utils/gopool.go:106 +0xa8
created by github.com/anycable/anycable-go/utils.(*GoPool).schedule
/Users/palkan/dev/anycable/anycable-go/utils/gopool.go:94 +0x12f
goroutine 418 [select, 14 minutes]: 1 times: [418]
github.com/anycable/anycable-go/utils.(*GoPool).schedule(0xc0001fc1b0, 0xc001e2ff20, 0xc00231e000)
/Users/palkan/dev/anycable/anycable-go/utils/gopool.go:88 +0x94
github.com/anycable/anycable-go/utils.(*GoPool).Schedule(...)
/Users/palkan/dev/anycable/anycable-go/utils/gopool.go:78
github.com/anycable/anycable-go/node.(*Hub).broadcastToStream(0xc000105e00, {0xc00231e000, 0x0}, {0xc0023bc3c0, 0x0})
/Users/palkan/dev/anycable/anycable-go/node/hub.go:354 +0x278
github.com/anycable/anycable-go/node.(*Hub).Run(0xc000105e00)
/Users/palkan/dev/anycable/anycable-go/node/hub.go:114 +0x32e
created by github.com/anycable/anycable-go/node.(*Node).Start
/Users/palkan/dev/anycable/anycable-go/node/node.go:102 +0x68If you look long enough at the output above, you might spot the difference: node/hub.go:355 and node/hub.go:354. For our simplified example, that would be the following lines of code:
func (h *Hub) broadcastToStream(stream string, msg string) {
h.mu.RLock()
defer h.mu.RUnlock()
if _, ok := h.streams[stream]; !ok {
return
}
h.pool.Schedule(func() { // 1 -> hub.go:345
h.mu.RLock() // 2 -> hub.go:346
defer h.mu.RUnlock()
// ...
})
}Wait, what? Hub blocks itself by calling mu.RLock() before entering the pool! But we’re calling RLock everywhere, so why is it blocking now? Multiple readers should work just fine. Well, unless a writer is pending:
if atomic.AddInt32(&rw.readerCount, 1) < 0 {
// A writer is pending, wait for it.
runtime_SemacquireMutex(&rw.readerSem, false, 0)
}Despite using RLock in the broadcastSession, we also introduced another potential blocking call—pool.Schedule. And this call happens within the lock! Our good habit of deferring Unlock has failed us here. It’s simple enough to fix, let’s do it like so:
func (h *Hub) broadcastToStream(stream string, msg string) {
h.mu.RLock()
- defer h.mu.RUnlock()
if _, ok := h.streams[stream]; !ok {
+ h.mu.RUnlock()
return
}
+ h.mu.RUnlock()
h.pool.Schedule(func() {
It only took a couple of lines of code to fix the bug, but the long and winding road while tracking them down was full of surprises and discoveries. Analyzing stack dump files could be a helpful strategy in cases where other profiling tools are unavailable or aren’t showing the full picture. Just remember, don’t panic, and good lock! 🔒
Talk to us! If you want to supercharge your digital products (built with Go or Ruby), we’re ready to make it happen. Let us help—we’ll improve the development experience for your team!