Designing Machine Learning for DVC Studio



Read how we helped build design and frontend for DVC Studio: a platform for tracking, visualization, and collaboration on Machine Learning experiments. DVC is a flagship product from Iterative.ai—a company that focuses on developer tools for ML and embraces the open source and Commercial Open Source Software. Both Machine Learning and COSS are part of Evil Martians’ DNA, so the project quickly became personal: we helped build a tool that we would use ourselves.
Merging Open Core and Machine Learning
In recent years, Deep Learning techniques have greatly improved accuracy in a whole family of Machine Learning tasks, making previously experimental technologies reliable enough for use in production. What used to be cutting-edge academic research is now an established industry with mature infrastructure and highly available tools that make building end-user solutions more straightforward than ever before.
One of the ways Machine Learning tools become available to businesses is a COSS (Commercial Open Source Software) model. It’s an open core that anyone can freely use and modify with an option to adopt commercial features and priority support—something that makes more economical sense for larger customers than relying on purely open source contributions. At Evil Martians, we have embraced the same approach for our OSS products: both imgproxy and AnyCable now offer commercial versions.
DVC (stands for Data Version Control) from Iterative.ai is a Git-based version control solution for Machine Learning engineers that follows the same COSS principles: free open core for individual developers and paid plans for teams and enterprises.
Martians helped the company rethink its web presence and shape the UI and frontend for sophisticated user-facing product Iterative.ai has—the DVC Studio.
Business on data
DVC was built for data scientists by data scientists: started in 2018 by Dmitry Petrov and Ivan Shcheklein, Iterative.ai is built on the experience both founders have acquired while working for companies like Microsoft, Node.io, Yandex Labs, and Google.
Remote-first and based in San Francisco, California, Iterative.ai raised a $20M Series A round in 2021, which brought the company’s total funding to over $25 million.
Rise of the versioning
Machine Learning models are different from “traditional” software products. Their success depends not only on planning and execution but also on training: a highly complicated process where even the slightest deviation in one of many parameters can make or break the outcome. There’s a strong demand to track all the inputs to the model and version the training variants: so that expensive CPU cycles don’t go to waste and a team can easily select the “winning” combination from a plethora of experiments. There were many approaches to that: from storing results in Python notebooks to having REST-accessible databases, but there was no standard, vendor-agnostic, lightweight toolchain to maintain data version control and model performance monitoring. Not before DVC came into play.
The DVC team believes that ML models should be treated in the same way as “traditional” code when it comes to versioning. And they decided to build upon a toolset that every software engineer out there is familiar with: Git.
Git-based Machine Learning
DVC is an open source infrastructure for data management and versioning of training results. It’s a console tool that runs on top of any Git repository and is compatible with any standard Git server or provider (like GitHub or GitLab). For a developer, DVC operates like Git and uses basically the same workflow: you push and pull files to and from a remote location.
DVC is for organizing data science and ML workflows—you write a configuration to describe the experiments’ results—metrics, parameters, graphs, failures, etc. The platform can read and visualize them and build deltas.
Machine Learning engineers can train models and see how they perform, whether they do better or worse, correctly store them with all related code, data sets, and results. DVC works with any modern storage: Amazon S3, Microsoft Azure Blob Storage, Google Drive, Google Cloud Storage, Aliyun OSS, SSH/SFTP, HDFS, HTTP, network-attached storage, or on-premises hardware.

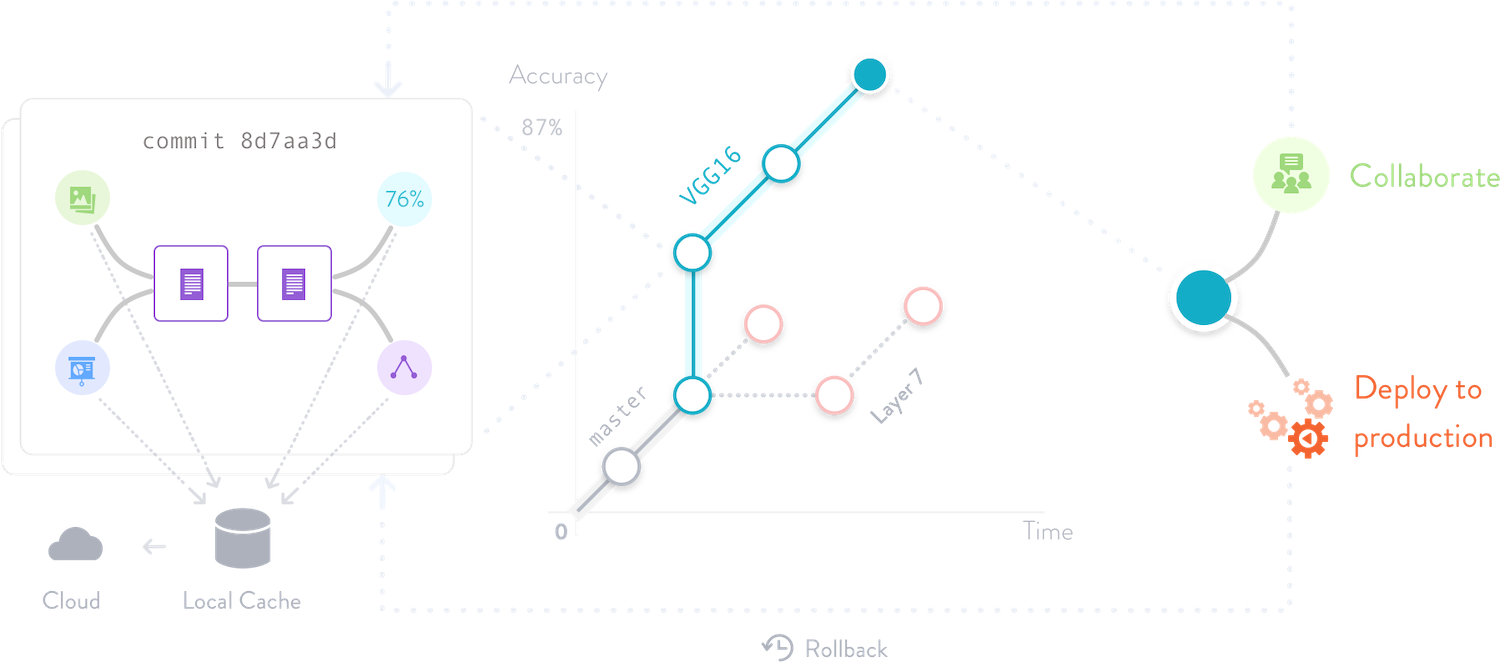
This guarantees reproducibility and makes it easy to switch back and forth between experiments, keeping the full history of every ML model evolution. All the collaboration is done through Git, leveraging the muscle memory of seasoned developers.
Improving web presence
Collaboration with Evil Martians came to be through a vivid and committed DVC community. One of the community resources is the documentation website, and the DVC team was quite meticulous about it. The platform required some improvements to make its interface clear and well-structured.
Arranging DVC documentation
DVC’s documentation is built on a custom engine that was in need of a frontend refresh. We have redesigned and rethought navigation and routing, used SSR for speedier delivery, improved the search engine, debugged the platform, and updated dependencies. Then we brought some SPA interactivity to the admin area, so maintaining the knowledge database became easier for moderators.

Docs repository
Refining the Community page
The Community page is an important gateway between DVC’s core team and the open source contributors. One of the interesting frontend challenges was collecting and displaying dynamic content updates on the fly: things like announcements of the latest blog posts, chat questions, events, and new documentation pages. We spent some time on API integrations to make the otherwise static site more dynamic, collecting and displaying data from external sources.
We have designed the layout and icons, built the frontend part, implemented Sentry-based error tracking, and, eventually, released the new community page.

Community page with dynamically updated blocks
Reworking the DVC blog
The DVC team needed to refine the company’s blog and optimize its images. For this purpose, it had to be migrated from Medium to Gatsby. One of Gatsby’s benefits is image optimization without being bound to a particular hosting service. Gatsby generates images for all types and scenarios with its built-in resizer and optimizer, providing responsive pictures with automatically generated Retina-ready image sizes for different resolutions.
During the migration, it was critical to transfer all the content to the new platform and ensure that all Medium’s custom options for content formatting and design were available on Gatsby. Those were things like text blocks that could be expanded or collapsed, the special design of links and sidebars, automatically expandable Reddit feeds, and other features. We needed to keep article sources as .md files, but at the same time, we didn’t want blog editors to write in raw Markdown. So we wrote special plugins for Gatsby to generate Markdown.
Then we adjusted some deployment settings and created a design system for a new blog.

The refreshed blog
Migrating to Gatsby
Gatsby scored high on the satisfaction scale, so DVC entrusted us to migrate both the Community and the main landing page—dvc.org—to the new stack. At the same time, we were tasked with redesigning the website for iterative.ai.

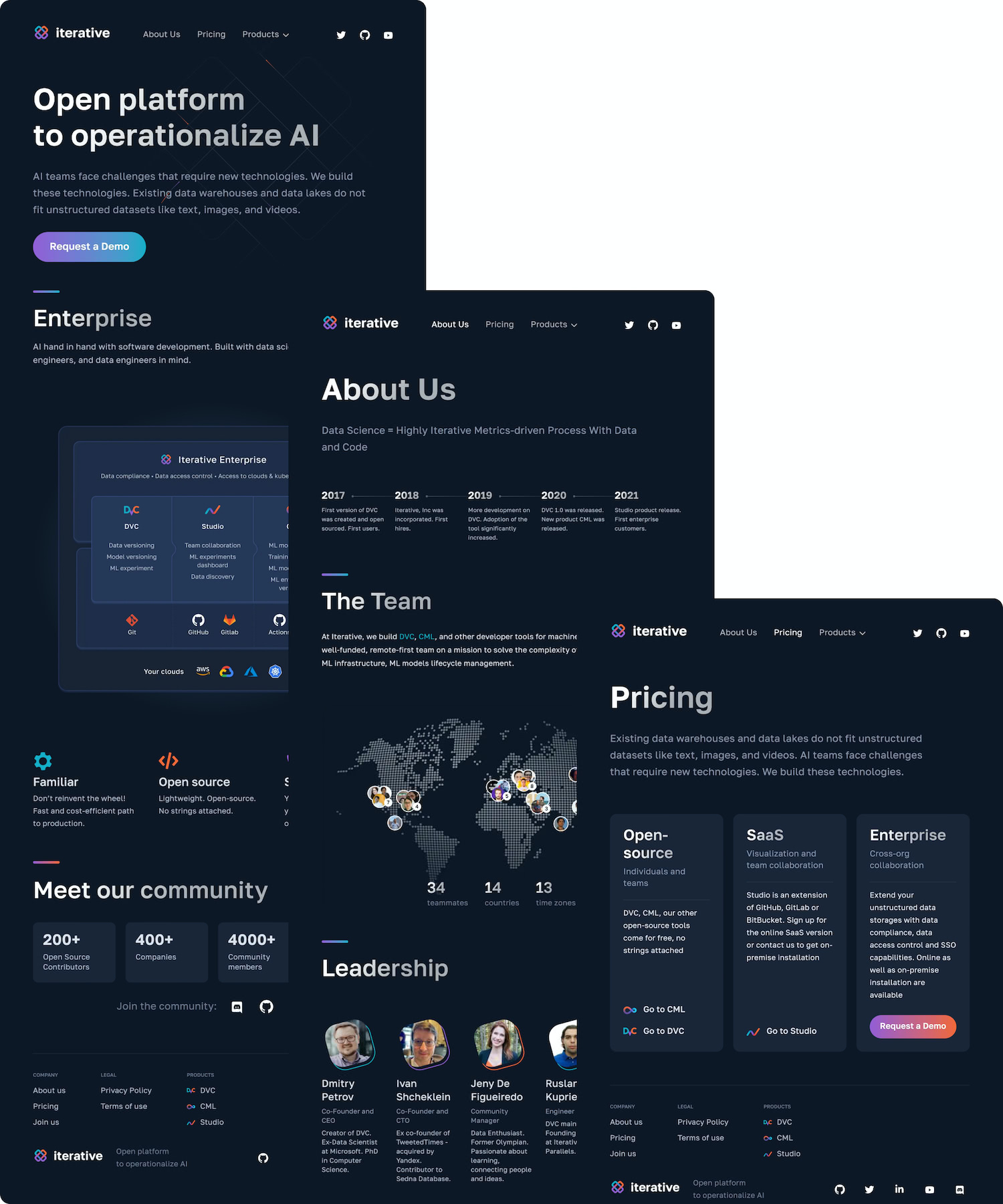
First, it was necessary to improve its structure, highlighting three main pages: the Homepage with products, the corporate page with the team and “about” content, and the product section that compares Free and Enterprise versions of software and hosts the contact form.
The second task was to “lighten up” the interface by:
- Getting rid of the block structure in design, keeping the corporate style
- Shortening a long landing page and providing more visual details to let users eyes dwell on them
- Making all icons bright and outstanding
- Selecting a smart font that distinctively reads in different type sizes
- Aligning design elements by location and brightness.
Shipping DVC Studio
The next important step in the project was shipping Studio—DVC’s first-ever SaaS solution targeting ML engineers—together with the DVC core team.
It was one of two new products DVC planned to launch to let customers build the full cycle of Machine Learning development and continuous improvement with the DVC platform’s core. These were Continuous Machine Learning (CML) built by the DVC team and “UI for DVC” or DVC Studio, designed by the joint force of DVC and Evil Martians. CML helps clients run tests on their ML models whenever they change, while Studio allows them to collaborate and view those models’ performance, including test results from CML, to pick the top-performing ones.
Continuous Machine Learning and DVC Studio were supposed to spur business growth—they were two missing pieces of the puzzle founders believed were crucial to start end-to-end enterprise client support. Their full stack should be open source and available to deploy as a SaaS service and on-premise on clients’ private hardware to be compliant with corporate security policies.
The Studio connects to the existing DVC Git repositories on GitHub or GitLab (or can be extended to work with either local Git repositories or other VCS). It provides a toolset to visualize experiments’ inputs and performance, compare them to each other, and visualize this comparison as tables or charts. The web GUI version on top of the platform’s core connects to the Git repository, searches for DVC files with params and metrics among commits, builds a table and diagrams reflecting how metrics change over time.

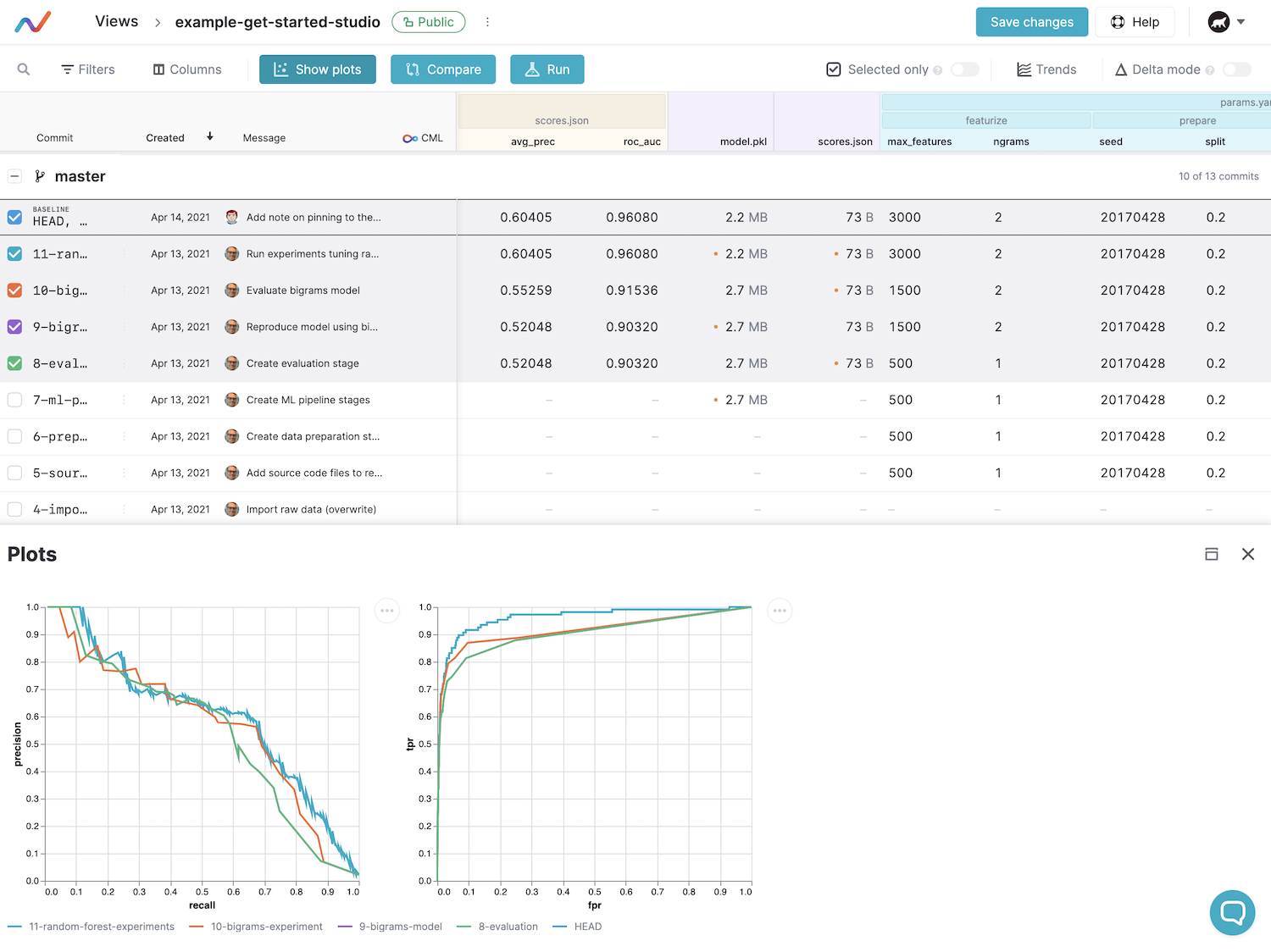
DVC Studio interface
Building DVC Studio frontend: tools to watch
Since we joined at the onset of the project, together with the core team, we could select technologies that would perfectly fit the task in production. The main challenge was optimizing the architecture and ensuring that the core frontend engineers can work on different features in parallel. We also had to be careful about experiments’ results stored in Git and external storage like AWS or Google Cloud or share different types of storage. Many integrations meant many points of failure, and we needed to make sure we minimized the risks.
Here is a brief overview of the technologies we chose together:
React
The tables’ management in the product interface involved a huge amount of dynamic updates since they needed to be filtered, sorted, and support search functions on the fly. It clearly argued for the SPA architecture to update targeted parts without reloading the whole page. We opted for React, choosing it from many SPA frameworks for its high popularity and a ready-made infrastructure built around it, including tools and libraries that could implement everything we needed.
Next.js
Next.js can implement “backend” routing and keep the desired page state after reload. This is necessary for search engine indexing and making sure key routes of the application load faster. Even though the application we worked on was not visible from the “outside” (it’s for authorized users only), Next.js still fit our needs in simplicity and reliability. It also allowed us to pre-process data on the server and send only the relevant portions to the client.
GraphQL or REST? Both!
Going with server-rendered pages worked well for most of the pages, with one notable exception: the repository page that visualized data from external Git providers like GitHub or GitLab. Processing all that information on the server proved to be troublesome, as searching and filtering through external information would require many network requests that rely on third-party systems.
Therefore, we decided to process everything on the client side in real-time: after loading the page, we made a massive initial request to the external repository, then stored it locally to allow querying without hitting the server. It also required finding a balance between GraphQL (easy to make dynamic queries) and REST (more requests but more options to optimize them).
Redux Toolkit
The next challenge was to store the data and display it in the user interface. Initially, we thought filtering and sorting features would not require frequent updates. However, dynamic features required recalculating almost all of the results on a single click. For instance, if the sorting rules have changed, we need to account for all the values in every single line in a complex table.
The Redux Toolkit enables structuring, storing, updating, and redrawing all data at the edge more efficiently and thus faster. It’s a Redux wrapper that provides TypeScript types and built-in dev tools, optimizes the entire boilerplate code, and in general, allows writing compact and clear code. We would recommend it for any Redux project by default.
Tailwind CSS
Adopting Tailwind instead of CSS Modules or BEM allowed us to build 80% of the components without creating separate CSS files. Over 80% of JS files didn’t have a separate matching CSS file at all. Exceptions were for tricky animations and external style libraries. Thanks to PurgeCSS, we were able to keep the total size of project styles under 20KB.
Reach UI
This is a set of ready-to-operate basic components: lightboxes, dropdowns, selects, pop-ups, tooltips—all focused on accessibility. All the components implement keyboard controls and work correctly with screen readers.
Design for viewers
Although we had plenty of UI design practice for extremely complex multi-stage flows, Machine Learning was a fairly new topic for Martian designers. Therefore, we started by diving deeply into the topic and reading tons of articles and documentation about experiments, metrics, ML products, and DVC’s operation principles. We had to learn how to run experiments and worked together with engineers, aiming to make the flow as clear as possible and create a design system commensurable with frontend development and based on components that can be easily reconfigured later.
Only after getting to know the product deeply, we started to research the interface for end users. First, we learned how to read GitHub data as a table; then, we thought of all the things people do with tables: resizing, fixing and configuring columns, filtering, sorting, and building graphs. All this research went into mock-ups and the component system that we designed from scratch.
Web-version screens
The Studio’s web version’s main screens are the list of all models and the details of each model. Model data is stored in Git repositories.

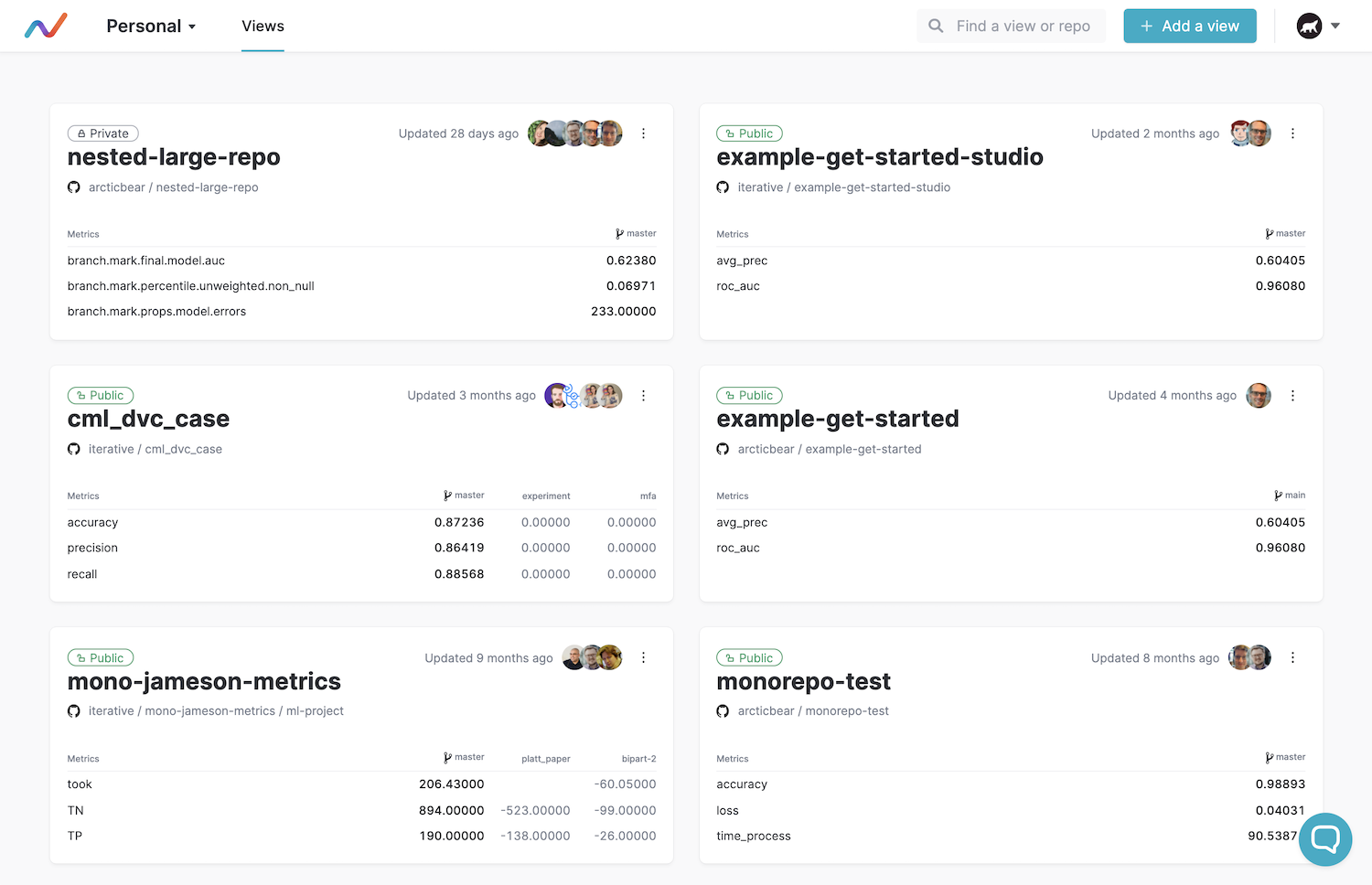
Projects dashboard
The list consists of sheets that lead to the model page. The sheet shows the key metrics of a certain reference ML model (typically, the HEAD commit of the master branch) and the difference between two experimental ones (HEAD of other branches).

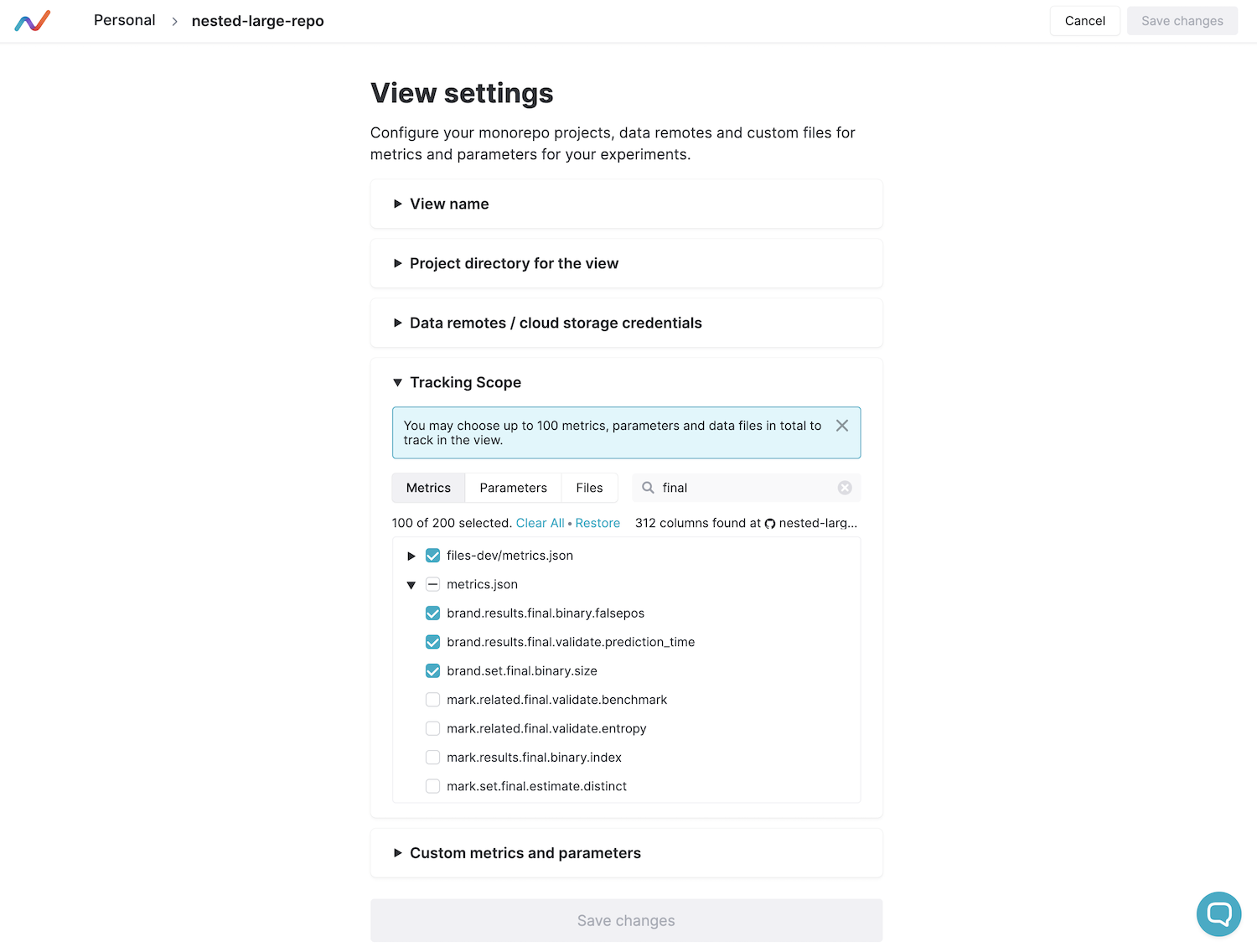
Metrics settings
A model is a table with data. Besides the reference model, there are experimental models on the screen to compare. Users can customize metrics and parameters to display and apply filters and sorting.

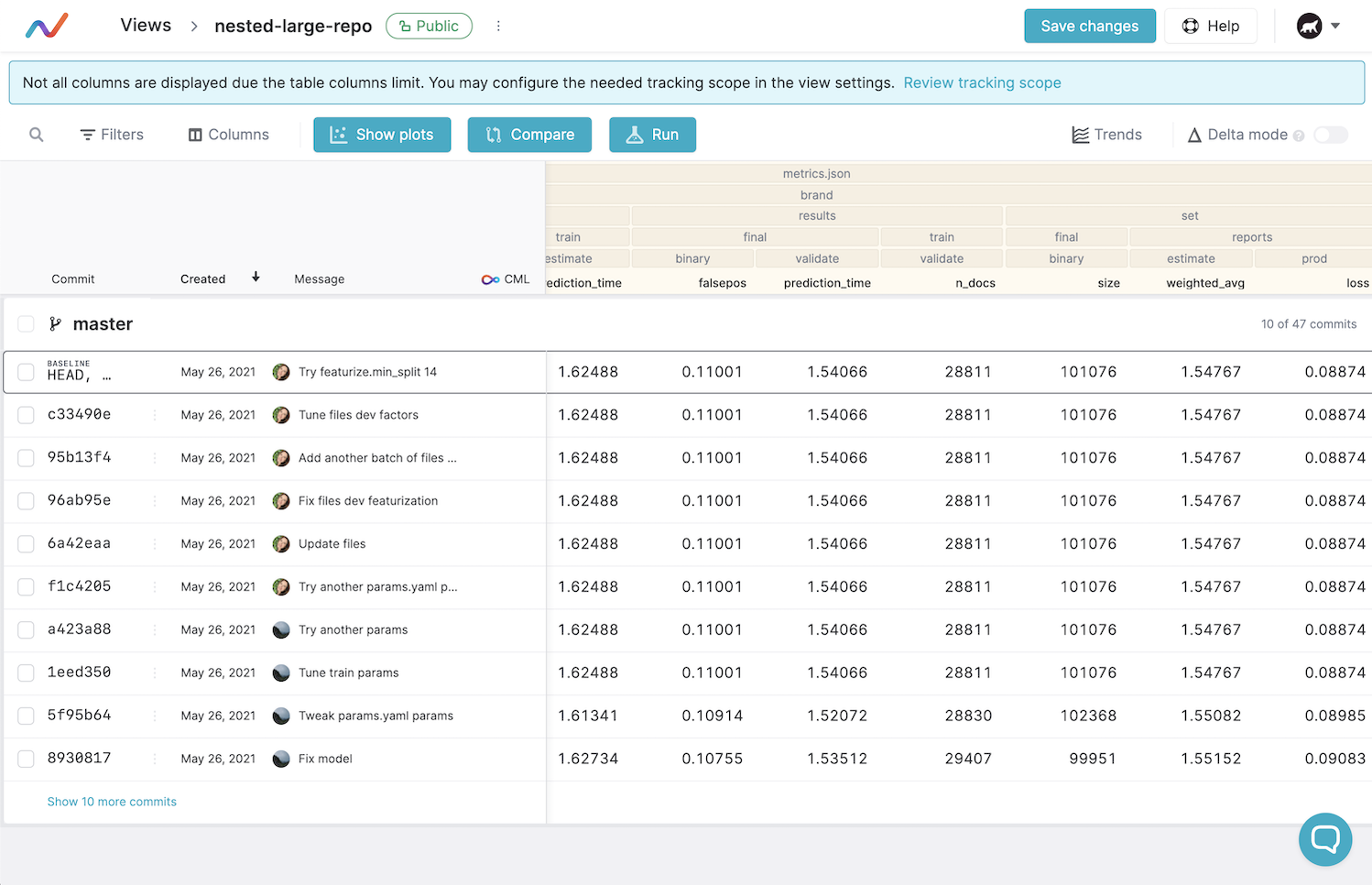
A table with model’s data
At the next stage, we designed the final scope of works for the DVC Studio Private Beta release—we had to showcase the tool to the first users and collect their feedback. Therefore, launching the product sooner was critical. However, long-term features were not thrown away: we drew a part of the design and the main flow so that the team could quickly launch them in the next Public Beta version.
It’s worth mentioning that we worked side by side with an in-house designer from Iterative. Hence, we refactored the entire final design system and moved elements and components into the brand-new Figma Variants approach to make it easier for DVC to built on that foundation further down the line.
Tinkering with API
The backend tech stack is a combination of Python, GraphQL, and Django. The previous API was pieced together from Django plugins that rendered HTML. We had to come up with a mix of GraphQL and REST endpoints to tailor to the more sophisticated, modern frontend.
We also came up with several optimizations for loading times. If metrics have not changed in a commit, we do not download them but take them from the previous one. Or download only the columns that are now included in the table, and reload the dataset if the columns’ combination changes.
We ended up rethinking and reimplementing many components of DVC’s web systems, and it was essential for us to make new practices adoptable by in-house developers and designers.
We have gradually reduced our contribution to the product, helped set up the hiring process by reviewing assignments for candidates, and helped organize in-house training for frontend engineers. From that point on, the DVC core tech team has been working on the frontend independently.

Working with Iterative felt right in many ways: at both companies, we believe in the power of Open Source and the viability of the commercial open source model—this helped us naturally align our priorities and launch a successful product.
In addition, we have already used the DVC’s tool that we helped design in one of our parallel customer projects: to version and store our datasets and models for speech recognition and text classification.
If you need any help with incorporating Machine Learning into your product at any project stage, whether it’s a proof-of-concept or a ready-to-operate business product, don’t hesitate to learn more about Machine Learning and other services we offer at Evil Martians and feel free to drop us a line.