Unparser: real life lessons migrating Ruby tools from Parser to Prism



Ruby 3.4 ships with Prism, a new built-in parser that’s faster, more portable, and designed to be the foundation for the coming generations of Ruby tooling. This shift affects everything that works with Ruby’s syntax: linters, formatters, IDEs, analyzers, and more. We’ll explore some weird Ruby, what Prism brings to the Ruby ecosystem, then use Unparser to show what the transition from Parser to Prism looks like in practice. The good news: the transition is doable. The catch: navigating API differences, new AST shapes, plenty of edge-case syntax, and testing thoroughly!

Hire Evil Martians
We join amazing startups on Rails like bolt.new, Whop, Teleport and many others to speed up, scale up and win!
Ruby’s quirks in action
Before talking about Prism, it’s worth seeing why Ruby parsers have such a difficult job. Ruby’s syntax is extremely expressive and developer-friendly, but this comes at a cost: maintaining the infrastructure to handle it (most notably the parsing system) is challenging.
Let’s see some Ruby that pushes the edges of the language’s grammar. These are cases of “legal” Ruby (not typos or “code golf”).
#1: We can construct ranges using the lhs..rhs and lhs...rhs syntax, but can we build ranges with range bounds?
1.....2Apparently we can: for example, this expression is a range from 1 to ..2:
$ ruby-parse --33 -e '1.....2'
(erange
(int 1)
(irange nil
(int 2)))#2: The flip-flop operator is extremely rare by itself, but have you seen a flip-flop without the LHS or RHS?
$ ruby-parse -e '!(1..)'
(send
(begin
(iflipflop
(int 1) nil)) :!)
$ ruby-parse -e '!(..1)'
(send
(begin
(iflipflop nil
(int 1))) :!These incomplete flip-flops are so rare that RuboCop would fail when run against one.
#3: When rescuing an exception via rescue => <expression>, Ruby internally performs <expression> = $!. This means the target of the rescue can be more than just a local variable like rescue => e; it can be a constant (rescue => A, rescue => ::Object), a method call (rescue => foo.bar), or even an indexed assignment:
begin
rescue => array[42]
end
begin
rescue => hash['error']
endSince you can redefine #[] with any arity you want, Ruby is fine with a zero-arity indexed assignment:
object = Object.new
def object.[]=(value)
puts "Received `#[]=` with #{value.inspect}"
end
begin
raise 'oops'
rescue => object[]
end
#=> Received `#[]=` with #<RuntimeError: oops>We had to patch Prism’s Parser translation layer to support this kind of syntax.
These edge cases may look absurd, but they’re perfectly valid Ruby. Thus, parsers (and the tools that depend on them) must be able to handle them.
A quick recap: what are ASTs and parsers?
So we’ve seen Ruby’s syntax can get weird. How do tools make sense of code like 1.....2 or rescue => object[]? The answer is parsers and ASTs. Let’s take a quick step back.
An AST (Abstract Syntax Tree) is a hierarchical, tree-structured representation of source code. Each node corresponds to a syntactic construct (like a method definition, keyword, operator, or literal) and encodes its type and value. Parsers transform raw source text into this structured form, allowing programs to analyze, transform, or compile code without directly processing unstructured strings.
For example, check this Ruby code:
def greet
if 👽
puts "It's cool on Mars!"
end
end…that code might turn into an AST that looks like this:
(def :greet
(args)
(if
(send nil :👽)
(send nil :puts
(str "It's cool on Mars!")) nil))So, why does this matter? Well, once code is in AST form, tools can analyze, transform, or lint it without having to deal with raw text.
Different parsers use different AST representations. Generally, syntax-specific things like whitespaces, comments and indentations are omitted. Some parsers might also normalize different operators (like and and &&) since the only difference between them is precedence, and this can be encoded in the order of the tree’s nodes:

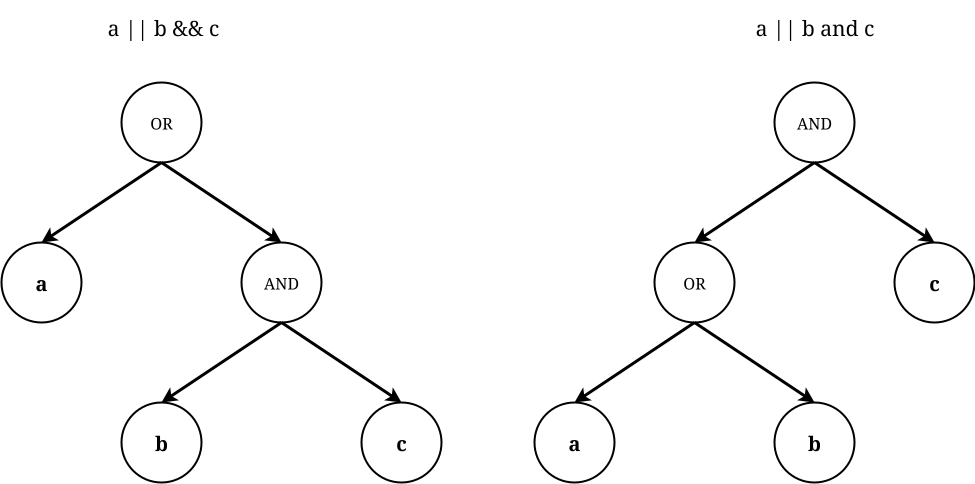
Both operators might be represented by the same node, as long as AST encodes operators precedence.
For downstream tools like linters, it’s usually much easier to analyze the AST, since it excludes unnecessary information.
Introducing Prism: Ruby’s modern parser
For many years, there have been multiple Ruby parser implementations. CRuby itself includes a built-in parser (parse.y) and exposes it through Ripper, but Ripper’s API and AST are notoriously difficult to work with, and it only supports the syntax of the currently running Ruby version (a critical limitation for tools like RuboCop that must analyze code across different Ruby versions).
However, many of these 3rd-party implementations tended to lag behind the latest Ruby syntax. Eventually, Shopify recognized the need for a modern, reliable parser that could serve as a standard. They invested in developing Prism to fill this gap.
This is where Prism shines: its design is grounded in extensive fuzzing and a massive test corpus that includes exactly this kind of oddball code. Incorporating tests from established gems like parser, unparser, and ruby_parser to ensure comprehensive coverage.
Prism was designed to be superior in several key areas.
- Performance: Benchmarking parsers is quite tricky, but this excellent blog post by Benoit Daloze reports that Prism parses Ruby code to MRI bytecode 1.46x times faster than parse.y.
- Reliability: Prism is thoroughly tested, including fuzzing and large-scale evaluation against real-world Ruby codebases.
- Maintainability: It was designed to be easier to maintain and evolve than parse.y.
- Portability: Prism is implemented as a standalone C library with no Ruby runtime dependency, making it embeddable in diverse environments. This is especially crucial for alternative Ruby implementations like JRuby, which can now adopt a standard parser without architectural constraints. As a result, Prism ships first-party bindings for JavaScript and Rust, with Java support included directly in the repository.
Another important aspect is error-tolerant parsing. LSP implementations are gaining more and more attention, and for modern parsers, it’s no longer enough to simply accept a program (and produce a corresponding AST) or reject it. Instead, the parser must also provide helpful diagnostics in case of syntax errors. This is so that the developer can still benefit from features like autocompletion, go-to-definition, or inline error highlighting, even while their code is in a broken state.
Prism’s maintainers have invested heavily in error recovery and diagnostics. Compare this parse.y output and Prism output for a truncated method definition:
$ ruby -c --parser=parse.y -e 'def foo'
-e:1: syntax error, unexpected end-of-input
def foo
bin/ruby: compile error (SyntaxError)$ ruby -c --parser=prism -e 'def foo'
bin/ruby: -e:1: syntax errors found (SyntaxError)
> 1 | def foo
| ^ unexpected end-of-input, assuming it is closing the parent top level context
> 2 |
| ^ expected an `end` to close the `def` statementThe second output clearly provides better feedback for a developer when forgetting to add a closing end in the middle of a large script.
An interesting side-effect is that, since Prism is capable of recovering from some syntax errors, it can also output warnings, while parse.y does not:
$ ruby -Wc --parser=parse.y -e '42; def foo'
-e:1: syntax error, unexpected end-of-input
...ruby -Wc --parser=prism -e '42; def foo'
-e:1: warning: possibly useless use of a literal in void context
bin/ruby: -e:1: syntax errors found (SyntaxError)
...For a deeper look at Ruby’s parser landscape, check out Kevin Newton’s overview of Prism from 2024. Additionally, if you’re interested in its design and implementation, you can explore The Advent of Prism blog post series.
It’s Ruby 3.4 time now, which parser to use?
As noted in Parser’s README, it only supports Ruby syntax up to version 3.3. If you need to work with modern Ruby code (specifically Ruby 3.4 and beyond) you’ll want to use Prism.
But there’s a catch: Prism’s AST format isn’t compatible with Parser’s. This means you can’t just swap in Prism and expect your existing AST-processing logic to keep working.
To bridge this gap, the Prism team introduced a Translation Layer. As the name suggests, it translates Prism’s native AST format into the structure used by Parser (there are actually multiple translation layers for multiple supported parsers). This enables tools that depend on Parser’s AST to continue functioning—now powered by Prism under the hood.
One of the most notable syntax changes in Ruby 3.4 was the introduction of the itblock. In earlier Ruby versions, you had to explicitly declare it in blocks:
# Ruby 3.3: requires explicit block argument
42.tap { |it| puts it }
# Ruby 3.3: this raises an error: `it` is undefined
42.tap { puts it }But in Ruby 3.4, the block implicitly gets an it parameter:
# Ruby 3.4: this works just fine, no need to declare `it`
42.tap { puts it }Since Parser does not support this new syntax, here’s how it attempts to parse the code using its latest available grammar (Ruby 3.3):
$ ruby-parse --33 -e '42.tap { p it }'
(block
(send
(int 42) :tap)
(args)
(send nil :p
(send nil :it)))Technically, this is a valid AST from Parser’s point of view, but semantically incorrect for Ruby 3.4. The it is treated as a method call rather than a block-local variable.
Now, let’s see what the Prism Translation Layer produces for the same code:
$ bin/prism parser -e '42.tap { p it }'
Parser:
s(:block,
s(:send,
s(:int, 42), :tap),
s(:args),
s(:send, nil, :p,
s(:send, nil, :it)))
Prism:
s(:itblock,
s(:send,
s(:int, 42), :tap), :it,
s(:send, nil, :p,
s(:lvar, :it)))Notice the key difference: the Prism AST correctly recognizes this as an itblock and treats it as a block-local variable lvar instead of a method call.
In other words, even though Parser hasn’t been updated to understand Ruby 3.4 features, the Translation Layer ensures the AST you’re working with still makes sense, and tools like RuboCop can operate on it correctly (provided they also support this translated format).
Migrating Unparser: a case study
For many years, Unparser was built on top of the Parser gem, providing a reliable way to transform ASTs back into valid Ruby code. Since we rely on Unparser in our own projects (particularly for tools like ruby-next) the Ruby 3.4 transition presented a challenge: we needed Unparser to work with Prism’s parser and its new syntax features.
Rather than wait for someone else to tackle this migration, we contributed directly to the Unparser project, adding Prism support while maintaining backward compatibility with older Ruby versions. This work ensures that Unparser can continue serving the ecosystem while taking advantage of Prism’s improvements in performance and error handling.
From parsing to unparsing
Now that we know how to parse arbitrary Ruby programs, let’s explore the reverse process: unparsing.
As mentioned, different Ruby programs can produce the same AST. This means we can’t reliably reconstruct the exact original source code from an AST. However, in most real-world scenarios, that level of fidelity isn’t required. What matters is regenerating a program that produces the same AST, and thus, which behaves identically at runtime (let’s ignore self-introspecting programs). Anyway, in practice, the output will often look very similar to the original.
So, why would we want to unparse an AST? Here are a few real-world projects that rely on Unparser:
ruby-nextuses Unparser to regenerate Ruby code after performing AST-based transformations for backporting modern syntax.mutant, perhaps the most well-known mutation testing engine, uses Unparser to generate mutated source code. (In fact, Unparser was originally created to support Mutant.)proc_to_astis a thin wrapper around Unparser that extracts the source of aProcat runtime.- Many other tools are among Unparser’s reverse dependencies. If a project performs unparsing, it’s probably doing something clever or unconventional; this isn’t something boring programs usually do.
But what exactly does “unparsing” mean? Recall that many distinct Ruby programs can share the same AST. For example, consider these two functionally equivalent snippets:
def greet
if 👽
puts "It's cool on Mars!"
end
endAnd:
def greet
puts "It's cool on Mars!" if 👽
endBoth generate the same AST, despite their different appearances.

An infinite number of programs can share the same AST, but for a given AST and fixed unparsing algorithm we can reconstruct only one program.
So what does it mean for unparsing to be successful? The formal criterion is round-tripping: if we parse some Ruby code, unparse the resulting AST, and parse it again, we should end up with the same AST:
parse(unparse(parse(ruby))) = parse(ruby)Note that this is not the same as:
unparse(parse(ruby)) = rubyThis stricter condition would mean we can restore the exact original program, down to the formatting, comments, and syntax choices. But because the AST normally doesn’t retain that level of detail, such perfect round-tripping isn’t possible—only the semantic structure is preserved.
Adopting the Translation layer
Parser’s design separates parsing Ruby code from representing its structure. The Builder class provides an API to configure how different nodes should be represented, making it possible for tools such as rubocop-ast (which powers RuboCop) to parse Ruby code into their own AST representations.
Since the Translation Layer is intended as a drop-in replacement for Parser, in most cases all you need to do is use Prism::Translation::Parser::Builder instead of Parser::Builders::Default:
BUILDER =
if Gem::Version.new(RUBY_VERSION) < Gem::Version.new('3.4')
require 'parser/current'
Parser::Builders::Default.new
else
require 'prism'
Prism::Translation::Parser::Builder.new
endIf you want to configure Builder’s behavior, you can simply define a subclass dynamically:
if Gem::Version.new(RUBY_VERSION) < Gem::Version.new('3.4')
require 'parser/current'
class Builder < Parser::Builders::Default
modernize
def initialize
super
self.emit_file_line_as_literals = false
end
end
else
require 'prism'
class Builder < Prism::Translation::Parser::Builder
modernize
def initialize
super
self.emit_file_line_as_literals = false
end
end
endNext, define a parser using Prism::Translation::ParserCurrent or Parser::CurrentRuby:
PARSER_CLASS =
if Gem::Version.new(RUBY_VERSION) < Gem::Version.new('3.4')
Parser::CurrentRuby
else
Prism::Translation::ParserCurrent
end
parser = PARSER_CLASS.new(Builder.new)This approach ensures compatibility with Ruby versions older than 3.3, and avoids warnings when Parser::CurrentRuby is used on Ruby 3.4 or newer.
If your goal is simply parsing Ruby code through the Parser Translation Layer, this setup is sufficient. However, some low-level APIs are not compatible between Prism and Parser. If you need them, you’ll have to add conditional logic.
Parsing is stateful
Let’s take a look at this simple Ruby program:
a = 0
puts aAt first glance, you might think parsing the entire program is the same as parsing each expression independently and concatenating the results. But it’s not. When a parser encounters a = 0, it registers a as a local variable. Then puts a correctly references the local variable instead of invoking a method a (which technically might be defined somewhere).
Parsing a = 0; puts a produces:
$ bin/prism parse -e 'a = 0; puts a'
@ ProgramNode
├── locals: [:a]
└── statements:
@ StatementsNode
└── body: (length: 2)
├── @ LocalVariableWriteNode
└── @ CallNode (location: (1,7)-(1,13))
├── message_loc: (1,7)-(1,11) = "puts"
├── arguments:
│ @ ArgumentsNode
│ └── arguments: (length: 1)
│ └── @ LocalVariableReadNodeWhile parsing only puts a independently produces:
$ bin/prism parse -e 'puts a'
@ ProgramNode
├── locals: []
└── statements:
@ StatementsNode
└── body: (length: 1)
└── @ CallNode
├── name: :puts
├── arguments:
│ @ ArgumentsNode
│ └── arguments: (length: 1)
│ └── @ CallNode
│ ├── name: :aNOTE: the bin/prism output has been minified to show only relevant information.
Note the difference: in the second AST, locals is empty, so a is treated as a method call (CallNode). Meanwhile, in the first, it’s correctly treated as a local variable.
Takeaway: parsing is stateful. Many Ruby parsers maintain a static environment (symbol table) while parsing so they can decide whether a bare name is a local variable or a method call. This is why parsing a = 0; puts a (the parser has recorded a as a local) yields different AST nodes than parsing puts a in isolation (where a is parsed as a method call).
Handling local variables across parsers
To support this, you can implement parser-specific logic:
PARSER_CLASS =
if Gem::Version.new(RUBY_VERSION) < Gem::Version.new('3.4')
Class.new(Parser::CurrentRuby) do
def declare_local_variable(local_variable)
static_env.declare(local_variable)
end
end
else
Class.new(Prism::Translation::Parser34) do
def declare_local_variable(local_variable)
(@local_variables ||= Set.new) << local_variable
end
def prism_options
super.merge(scopes: [@local_variables.to_a])
end
end
endThis is because Parser uses a static_env object to track local variables, while Prism relies on a prism_options hash. Both these approaches allow tools to maintain scope information consistently during partial or incremental parsing.
You can see the full implementation combined in the original umbrella pull request.
Testing beyond unit tests
When you’re building tools that work with ASTs, unit tests alone won’t cut it. You’ll want to test against massive corpora of real code.
This typically means two things:
-
First, test against parser test suites like Prism’s corpus, which contains thousands of programs designed to stress-test parsers. This consistently uncovers bugs that handwritten tests miss.
-
Second, validate against real-world codebases. Public Ruby repositories expose your tool to production coding patterns, catching issues that curated test suites might miss.
Why bother? Because even if most developers never write these edge cases, your tool needs to handle them when they appear.
Wrapping up
The Prism GitHub repository maintains an incomplete list of software that has already adopted it. Alongside multiple Ruby implementations, this list includes ecosystem heavyweights like RuboCop, Rails (for features such as Action View’s template dependency tracking), Sorbet, and Ruby LSP.
Migrating Unparser showed us that the transition is doable, though you’ll need to handle API differences carefully and test thoroughly. If you maintain a Ruby parsing tool, it’s worth starting to think about your migration path, whether that’s using the Translation Layer for now or going straight to Prism’s native AST.
