Catch a batch: Making Mayhem 5 times more responsive



Milliseconds matter: that’s equally true for Olympic champions, online gamers, and gaming startups. Even little breakdowns in an online platform backend like excessive database calls or in-memory data manipulation can severely slow down the gaming servers’ response.
We have a solution how to save milliseconds or even seconds for your application’s speed—a thorough analysis of the performance map and a couple of freshly invented optimization tools can accelerate all requests fivefold. By the way, this optimization also reduced the number of resources required for database maintenance that allowed cutting the cost of cloud storage. These are the lessons we learned during a two-month project with the gaming startup Mayhem.
Founded in 2017, Mayhem focuses on automatic game tracking, leaderboards, and a global chat to bring gamers together in tournaments, leagues, and other real-time community-driven events. The project raised a $4.7M round from Y Combinator and Accel.

Mayhem website
What does the “real-time” feature mean for the tournament-based games hitting the industry, with thousands of leaders competing in the same game simultaneously? They demand a quick setup, no high lags or noticeable delays, and have little tolerance for unscheduled downtimes.
Therefore, performance is crucial, and milliseconds can mean the difference between success and failure, not only for players but for game-tracking apps as well.
GraphQL for satisfying gameplay
The project we recently finished required the optimization of GraphQL API performance, with two Martian backend developers orchestrating workloads to hit the performance goal. It’s a good example of a seriously interesting performance optimization task, as we had to not only detect all the bottlenecks but build a solution to resolve them on our own.
For the last couple of years, Martians have been increasingly practicing GraphQL for customers’ production applications. In many scenarios, building applications with GraphQL is more time-saving and high-performing in comparison with building with REST APIs.
Evil Martians engineering team has an open source-centric approach. On this path, we’ve already designed several open source tools that help developers improve critical areas of their Ruby and Rails applications. In this project with Mayhem, we had a chance to use and enhance them further (more on that later). On top of that, we added some brand-new open source solutions addressing GraphQL-on-Ruby performance that can be helpful for the ecosystem, as they already brought Mayhem some application performance improvements.
Here are some results and highlights that reveal how we nailed the task.
Profiling for a true picture of resource usage
How do you optimize something you see for the first time in your life? Detailed profiling typically gives an accurate, full picture of all the requests and functions, the number of resources they consume each time, and the speed of operations they require. Unfortunately, the GraphQL library for Ruby had no specific instrument for profiling.


GraphQL profiling
While many developers would typically guesstimate the root of problems without a specially designed toolkit, this approach is absolutely out of the question for Martians. A special profiling toolkit provides accurate and thorough research to detect troublemakers and measure the impact on performance for every change in code. Keeping with the Martian “research-and-run” approach, we decided to build a proper GraphQL-on-Ruby profiler. In the meantime, while the full-scale Ruby gem for profiling is under construction, you can find a pretty good example of the implementation here.
Dispensing with specific profiling for GraphQL, we designed a couple of tools to help us catch the slowest and most resource-consuming areas. First, we could already spot a problem of excessive batch loading, meaning the technique that collected the programs and data together in a single unit (a batch) before processing to simplify it and define the sequence made it counter-productive. There was a process of gathering the batches for too many fields, including unnecessary ones.
To solve the issue, we designed a custom tracer to identify fields that truly needed to be batch-loaded and fields that only pretended they needed to be and optimized their code to do without batches. For the sake of saving CPU resources, all the unnecessary batch loading functionality was removed in 80% of the cases.
The rest 20% was set on the right Rails-based path by migrating the functionality to AssociationLoader, the data loader designed specifically for Active Record models. The tool uses an internal preloading mechanism, helping to avoid unnecessary join tables resolving and querying.
Caching for compute overhead elimination
The second challenge related to heavy data aggregation fields (such as counters or user scores). To eliminate the computing overhead of those fields, we implemented caching functionality, updating the current libraries in the process.
The Mayhem project gave us some ideas of further caching enhancing in GraphQL, so we continued to build OSS solutions in this field. The existing GraphQL libraries do not cache the graph nodes and only allow caching resolved values, which means having to validate and serialize data on our own. Since response parts caching is much more efficient, we’ve started to solve the problem with the “fragment caching” function for GraphQL.
We just made the first step towards this by adding raw values support and recently released this functionality as a gem: check out graphql-ruby-fragment_cache.
Martian open source: Action Policy
Almost every Martian customer project contains some open source inside. This time it was Action Policy—a “Swiss Army knife” type of framework for implementing authorization policies in Ruby and Rails applications. One of the key factors to introduce Action Policy for the project was its caching support because the problems in the authorization process maintenance had some impact on the overall platform performance. The second reason was the solution’s special plugin to integrate access control features into GraphQL APIs with a simple but powerful domain-specific language (DSL). Back then, Mayhem used only ad hoc permission checks instead of a full-scale authorization framework. Migration to Action Policy helped to eliminate the authorization problems.
Feel free to ask if we can help design any useful toolkit of this kind for your startup.
Training
When a third-party team becomes involved in the product design, the in-house developers often face the task of absorbing the new technologies and approaches brought into a project. The problem is that they are usually overloaded with their current development tasks and unable to spend too much time exploring all the new code, tools, and patterns introduced by the external team. Since Martians typically bring mostly new things within short time periods, we cover any gaps via offline courses and online educational webinars.


Offline courses

Online courses
Almost ten years ago, we started a series of offline courses on Ruby on Rails and frontend technologies. Martians were keen to share the knowledge collected across dozens of customer and open source projects with skilled engineers that needed to enhance and put in order their experiences. The killer feature of each course was feedback sessions based on real customer cases from students—this highly popular event kickstarted customized in-house courses for our clients. Usually, we talk about all the significant changes in libraries and frameworks, explain the details for juniors, and educate project team newcomers on the application architecture. We answer every single question until all the in-house engineers have a full understanding of the way the application works and how the underlying technologies are designed. This time, we discussed authorization and Action Policy, GraphQL tests, and technologies to implement real-time functionality (like AnyCable).
5X Results
We started with profiling, continued with a lot of optimizations and refactoring and achieved a beautiful performance picture for the Mayhem platform, in which only those fields that are needed are requested. The response time of top-3 time-consuming requests that generated the most severe performance issues was decreased by 5X at the 95th percentile. Simply put, as their contribution to the application workloads was significantly reduced, and all other requests also became faster, the average response time cut five times thanks to the best practices and caching. For the platform with 1M+ transactions per day, it’s a big deal.

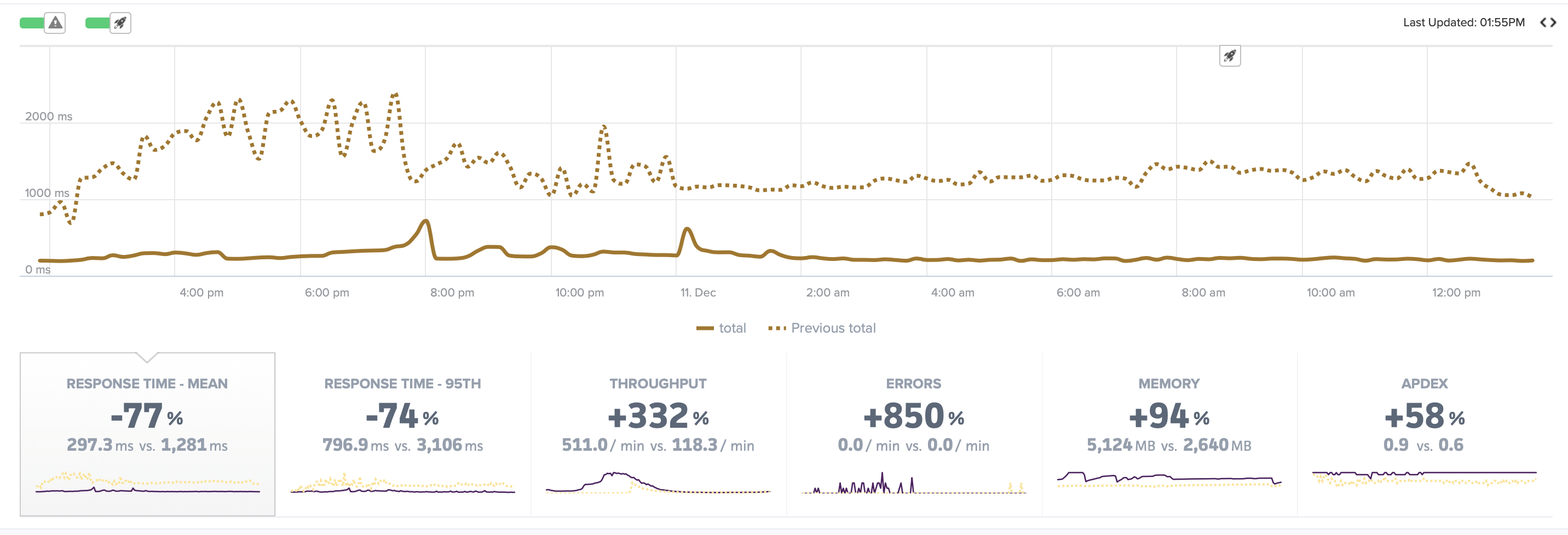
Average response time
After all the adjustments, the Mayhem team could reduce the number of running instances and change the plan for their database storage to a cheaper one to cut the expenses.
For gamers, these achievements mean faster response from the service and more satisfying user experience. For Mayhem engineers, a quicker reaction from the server means fewer resources to process and, potentially, fewer equipment requirements to maintain. For the community, the solutions we designed along the way have fundamentally enriched our extensive collection of open source projects.
Performance issues are nothing to be ashamed of, as they are typical bottlenecks experienced by almost all startups at their growth phase and not only the gaming ones. Does this sound familiar? Share your performance pains with us and call for a Martian intervention to bring things back on track.