The complete guide to multi-tenant SaaS, part 1: collaboration



Until recently, realtime collaboration was just this shiny new thing: some of our consulting clients wanted it, but it was expensive to implement and the payoff wasn’t always crystal clear to them. In any case, the projects we had that saw us implementing collaborative features inspired us enough to go deep into building realtime tooling (see AnyCable, Logux). Flash forward to today, and realtime collaboration has become the centerpiece of a business model, the multi-tenant (or multiplayer) SaaS, which has proven extremely efficient for devtools, professional, and creative tools. And now, as a matter of fact, many of our clients are opting for this model.
In this series of posts, we’ll provide an experience-backed overview on just what it takes to add a Multiplayer/Multi-tenant SaaS mode to an existing product. The goal is to provide some guardrails for any team who might choose to go down this path in their future–so, read on!
Multiplayer as a business model
The essence of the multiplayer model is that you have a product free for individual usage which becomes paid when users form a team and start collaborating; the service is paid for by an organization, usually the employer.
The model has some important benefits worth noting:
- Adoption by free-tier individual users is a key source of growth.
- The ability to invite collaborators is a source of discovery and viral growth.
- Free users drive a “bottom-up” B2B sales movement, advocating for the product within their organizations.
- It’s an efficient monetization strategy–and this has been proven by products like Figma, Notion, Google Workspace and more.
Now, practically speaking, to implement a multiplayer mode in your product, two key components are necessary:
- You must enable collaboration: this means allowing multiple users to edit shared resources and view each others’ edits.
- You need to add support for user roles, permissions, and other enterprise-grade features.
There will be more to come, but in this initial post of the series, we’ll focus our discussion on that first point: collaboration.
However, before we go any further–you must ask yourself an imperative question.
A question you must ask—and how to find the answer!
There is a key question you must absolutely ask before proceeding:
”Will this model fit my product?”
To answer this critical question, take stock of your product and look for signs that collaboration is already taking place, at least with some of your users. If not your product, look for these signs in competing products or alternative solutions to the same problem. Examples might include:
- Screen sharing. Are users utilizing a screen share mode when working with your product? Examples: pair programming and Tuple.
- In-person collaboration: Are people meeting in conference rooms or other physical spaces while using your product (or alternatives). Example: in-person brainstorming sessions and Miro.
- Google Docs or Notion: Are users leveraging Google Docs or Notion in the process of working with your product.
- File exchanges: Are they sending files back and forth within the organization or externally? (These files might often be named something like
projectSpec_version 3_revised_final.docx.)
Of course, it’s your product, and you can always bet on multi-tenant SaaS, regardless of if you see the signs or not–but it’s always better to work with an existing need.
Once you’ve answered that question, there are two key factors we’ll mention that will affect the complexity of the solution, (as well as the value it will ultimately bring to users).
The first one of these factors is the collaboration flow, or how the process of collaboration is designed and used. In this post, we’ll look at pros and cons of each approach for implementing this flow, and how that implementation will affect two other factors:
- The conflict resolution strategy, or how to define the state of a resource when multiple people are making different edits.
- History management, or how to handle access to the revision and reversion of edits.
The second factor to consider is the potential need for an offline mode, or what happens when a person loses a connection.
You’ll quickly see that there is no one-size-fits-all when it comes to collaboration, and you’ll need to make your own choices. And that means that weighing your options is certainly worth the time. Ready?
Collaboration flows
Take a look at the image below for an overview, then let’s begin our tour with the most simple approach: baseline.

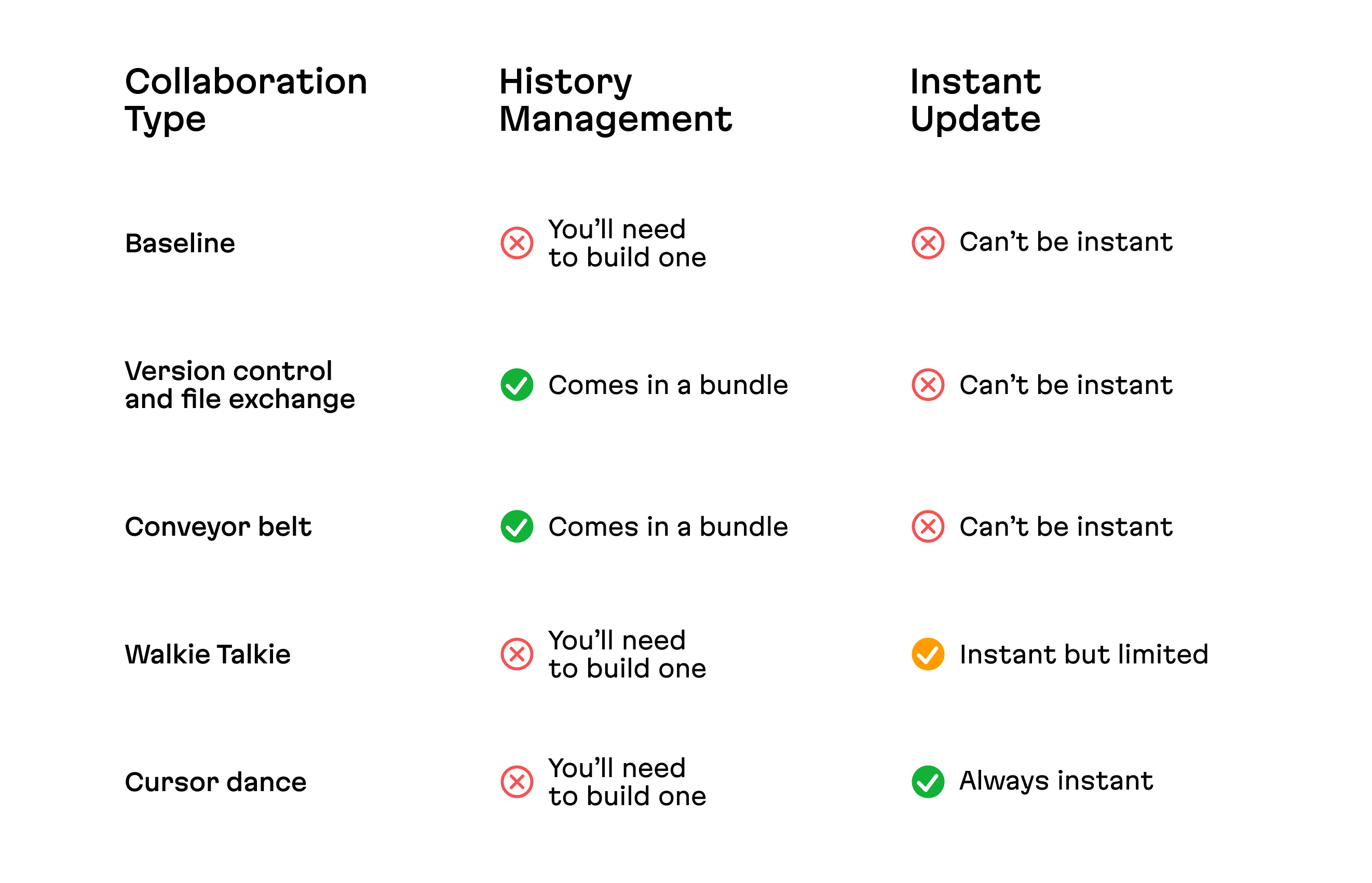
Baseline
Collaboration simply implies that several people can edit shared resources and view those edits. This can take various forms: it could be a simple CRUD UI, a file upload/download mechanism–or something else, without any “special” realtime functionality. This flow comes naturally for SaaS products, and building a file exchange for desktop applications is sometimes the most simple way to test out the need for collaboration.
The conflict resolution strategy in this case is a simple “the last change wins”, meaning that whoever is able to push an update last will override all other edits. Of course, this is also not the ideal approach: for instance, when people edit data before they’ve viewed the latest edits, they’ll override each other’s work–this can be quite disastrous for everyone’s productivity.
One simple way to improve the situation a bit is with hot reloading: broadcasting each edit to all viewers as soon as possible, without an explicit page refresh–this reduces the risk that a user will start editing a stale version. But this doesn’t solve all the problems…
Let’s look at another case: imagine a “second” editor has started editing a version of a document before it has had updates applied from a “first” editor. So, this “second” editor pushes their edits, and in the process, they override the work of the first editor. Boom! Things can get messy here.
Moving on from conflict resolution strategy to our second promised point of discussion, in terms of history management, here’s what we could theoretically build:
- Simple undo/redo controls which are limited to the user’s own actions, only one text field, and function only until they submit an edit. For instance, this feature is built-in for browsers.
- Extended undo/redo controls: these are still limited to the user’s own actions, but apply to all interactions with the UI on a screen; this can be built using state machines.
- Version history, stored on a server, and ordered chronologically according to the time the server receives each update; users can review and restore each version.
- Change history: this one is similar to the previous option, but in this case, only the changes are stored, and they can be reviewed, approved, or reverted (in a Git-like manner).
That said, in reality, most applications will not bother with any special history management in this scenario–but this will be an important consideration as we move on to our next options.
While this setup is often used to “try things out”, it’s not really going to be easy to actually learn something from this trial. What are the product metrics that will indicate simultaneous edits in a standard CRUD UI? The default Google Analytics events are not going to be sufficient.
You may choose to add custom server logic to track simultaneous edits of the same resource by different users within a certain window of time–seconds for small inputs, but arguably minutes for large text inputs. Or, in other words, if Alice started editing a resource before Bob has submitted his update. Now Alice sends her update, and because she did not receive the version updated by Bob, she will override his changes.


Now, let’s move on to more interesting options!
Version control and file exchange
With a version control approach, we batch edits made by a user into a “commit” and then send them to a server upon user action: this action could be a button press, a CLI command, et cetera. On the whole, this is similar to Git flow.
But, that said, Git is not the most widely used application of this idea: a simple file exchange over email embodies the same approach. The aforementioned projectX_spec_version134_final_final.docx is the most popular application of this idea, and this is despite all the manual work involved, any hiccups as conflict management must be performed by hand, and the ready availability of collaborative alternatives like Google Docs.
Despite all of the above issues with file exchange, lawyers, bankers and many other high-level professionals strongly prefer this way of working! Why?

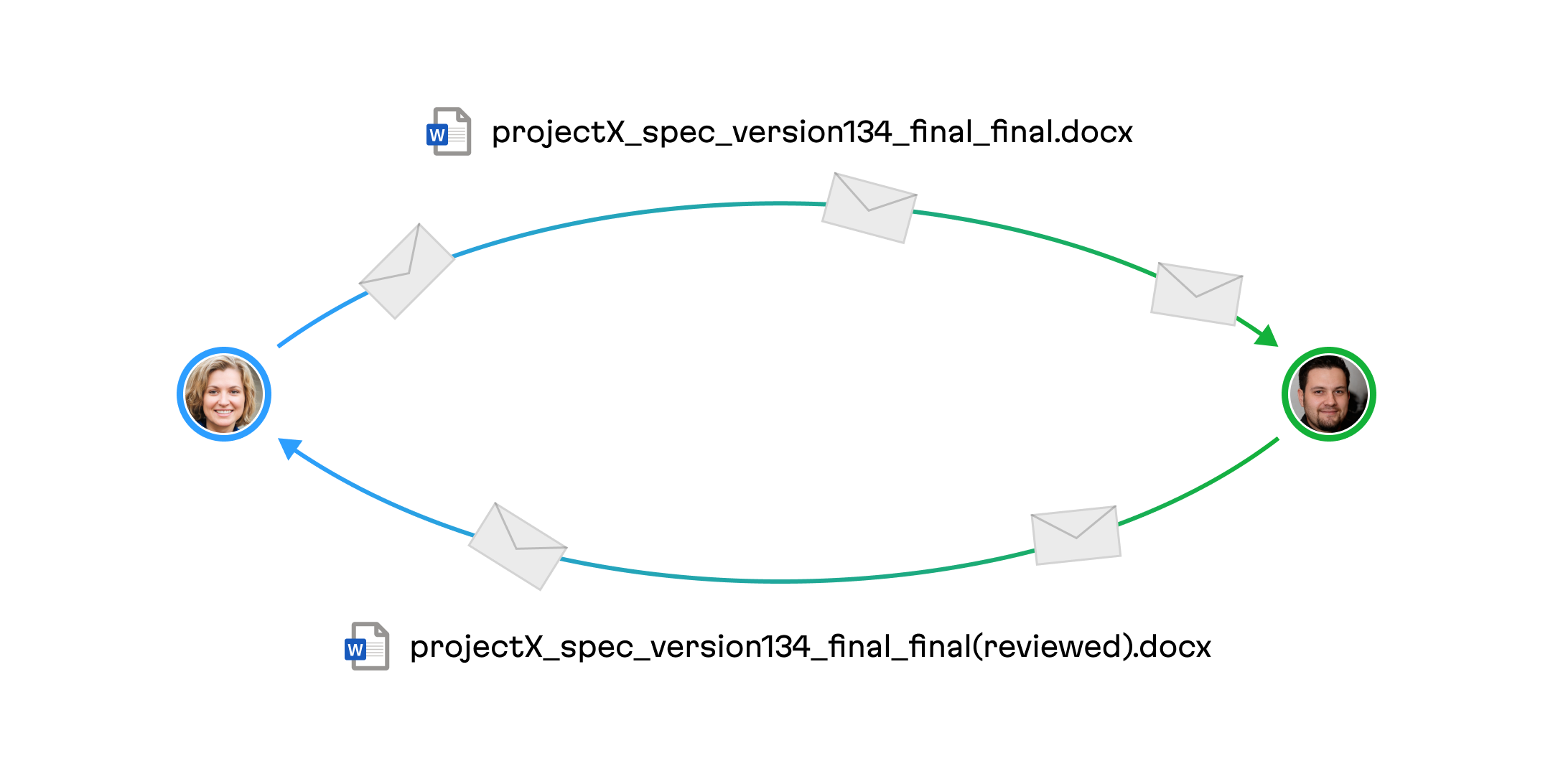
The key reason to use this flow lies in the fact that the editing history itself is placed in the center of attention, and each edit needs to be approved by several sides. Thus, the need for revision and reversion of the work provides the motivation to use this design. It is precisely the absence of true realtime editing that allows access to this history. And, as you will see, atomic edits which are the result of realtime flow, are hard to track and it’s impossible to navigate thousands of tiny edits.
Now, the obvious downside is the speed of the feedback. This is why this model doesn’t fit the synchronous style of a collaboration when all agents take action at the same time. But it’s often the best option for async work, which is in most cases preferable for productivity reasons.
Conveyor belt
This is a subtype of the above version control, except with this model, each “commit” moves the document down a predefined chain of states. Crucially, at each state, only users with certain permissions can work with the document (and their actions at each stage can be different and limited too).

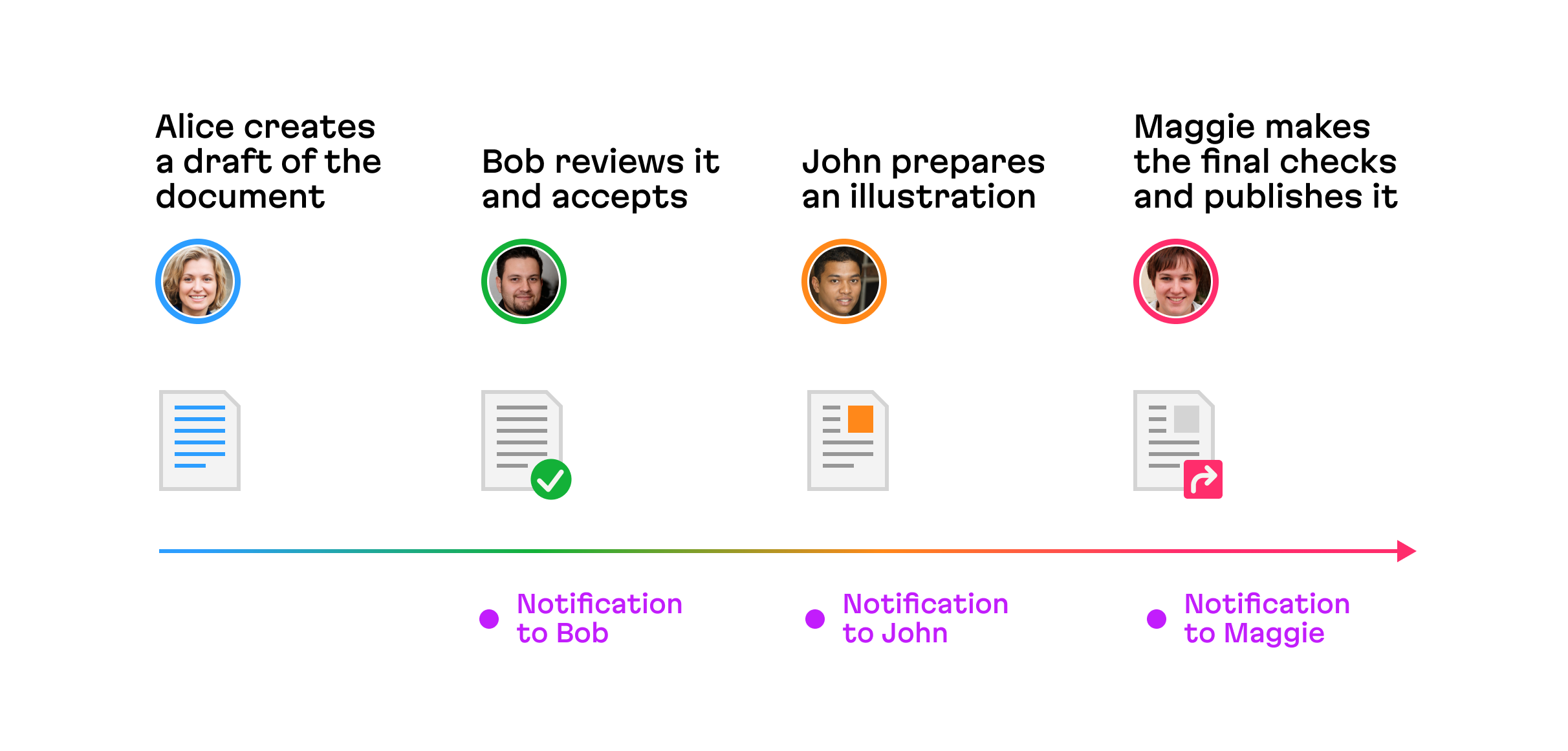
A good example of this type of collaboration is CI/CD pipelines: a series of steps that must be performed in order to deliver a new version of software. At each step, such as development, review and testing, production and monitoring, certain actors must perform certain actions.
The key benefit of conveyor belt is that it helps structure a complex collaborative process, where different people need to take action at specific stages. Users can benefit from useful automatic notifications–exactly when their input becomes needed.
Overall, the conveyor belt pipeline ensures that the wheels of the process are humming along smoothly.
This type of collaboration is best suited for vertical SaaS products that are tailored to specific and known business processes.
General-purpose or multi-purpose products cannot be structured in such a way–or even if they can, the vast majority of the work is still going to happen within one stage, so it won’t affect anything too much.
Walkie Talkie
Users can view all edits in realtime as they’re being made, but they cannot edit the same text field, input, or element, at the same time. At any moment, each element has only one editor, and for other users the editing is locked. When one user begins editing an element, it locks it for everyone else. When the edit is submitted–upon a button click, focus-out event, or inactivity timeout–the lock is lifted, and the element can now be edited by someone else.


This implementation provides a lot of flexibility and value for realtime collaboration, while avoiding the addition of unnecessary complexity into the system.
With this locking mechanism, there’s no need for conflict management, although, depending on the particular implementation there could be corner cases that require manual conflict resolution.
History management is tricky because the edits are atomic, not batched, so the history itself is hard to navigate, and the locks may prevent even simple undo/redo actions.
All that said, the main downside with this approach is that not every UI can be split into small inputs–and users may need the full freedom to edit any part of any resource at any time.
Cursor dance
Finally, we come to the fully instant and simultaneous collaboration, and this is what many people visualize when you say “multiplayer mode”. It’s the image of a smooth and elegant dance, where the instantaneous movement of cursors and elements is a beautiful and constant reminder that the hands moving them might be separated by thousands of miles.

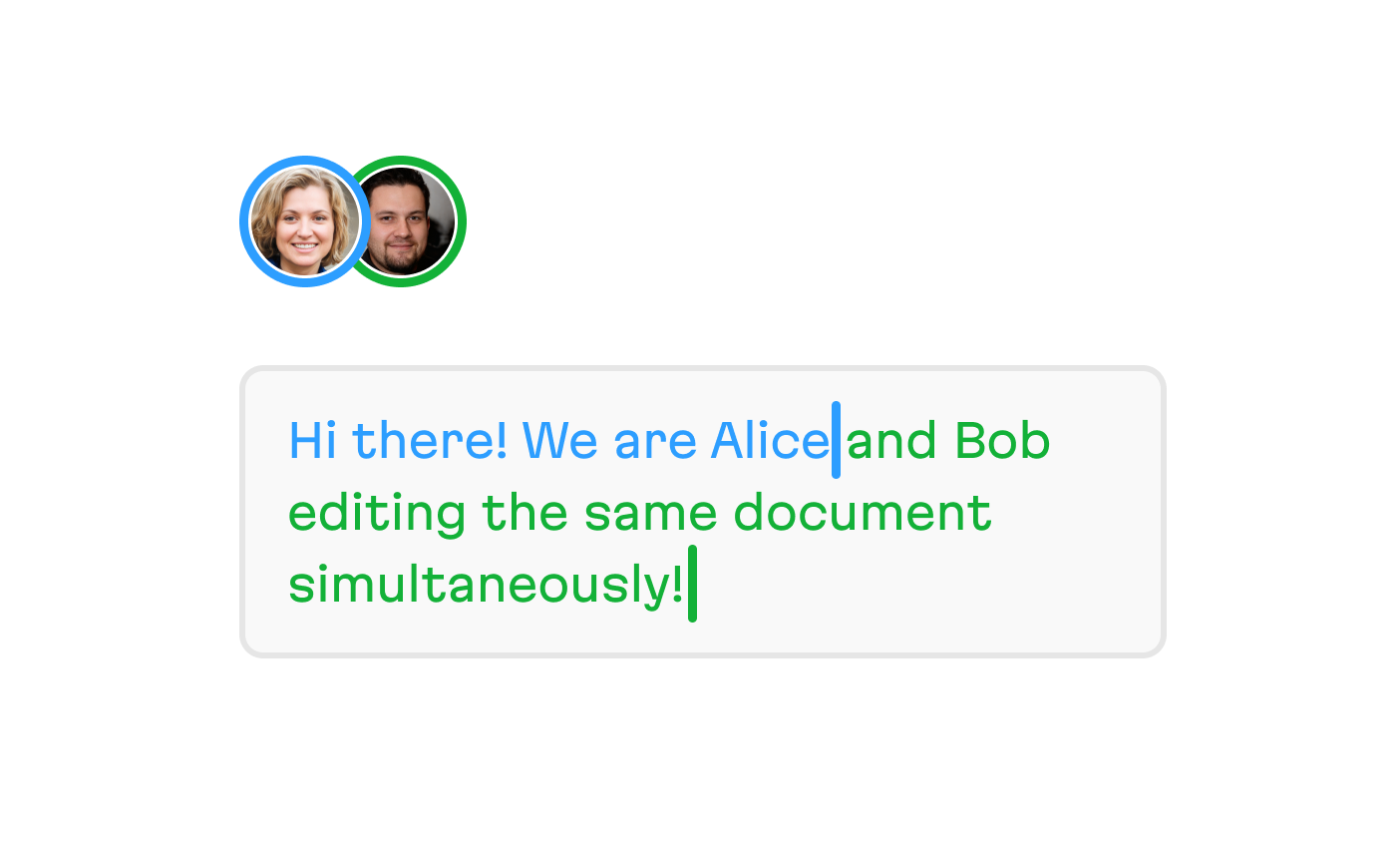
This is full-blown realtime collaboration, where every person can edit anything they want at any time, and all their edits are immediately synchronized, with any conflicts automatically resolved.
The benefits are clear: huge productivity gains are possible by enabling people to collaborate and co-create as if they were in the same room, working on the same canvas, whiteboard or blueprint.
But is it easy to implement? This challenge has been rolling around in the minds of computer scientists for decades, and there are notable and complex algorithmical solutions, each of which come their own unique quirks: the OT (operational transformations), CRDT (conflict-free replicated data types, implemented by Y.js, Logux and other tools), and, notably, Figma’s own take on CRDT with centralized server-side order. We’ll talk about these solutions in our next article.
But despite any challenges, thanks to multiple innovations in realtime tooling, implementing this design is becoming more and more affordable and easy to build with each passing day.
With respect to history management, full realtime is similar to the realtime with locks discussed above. Popular applications with realtime collaboration mode either provide limited to no history tools, or it comes in the form of history snapshots. This means it’s pretty difficult to learn what’s been changed or to review those changes when you return to work after some time off (or, even maybe just after a good night’s sleep).
To illustrate, with Google Sheets, you can view detailed edits of each cell of each spreadsheet, but you need to know where to look. Basically, it seems to be unfeasible from a design perspective to efficiently review arbitrary realtime changes in complex resources.
We’ll cover the technical aspects of implementing this design in more detail in the next chapters of this series!
But we’re still not done with this post, because we need to consider that other key factor that will play a big role in how your solution is implemented: offline mode.
Offline mode
When working with a file, what should the experience of using an app be like when a person loses their connection with the server–or with the Internet altogether? As a fellow web technology consumer, you’d probably answer that everything should remain in place, no white screens, no UI freezes, and the entire application needs to remain operational until the moment you go back online.
But is that what you must have? In fact, while there are cases when an offline mode is a must, implementing it is quite expensive, and thus, most applications will decide not to go down this path.
Let’s explore this. For an application to remain fully functional without Internet connectivity, it needs to do 2 big things–both of which have clear considerations that come with them:
- All the data and logic need to be stored on the client side. This will quickly turn an innocuous browser tab into a RAM-devouring monster, and will likely slow down startup time (unless you use something like Qwik).
- Your app needs to be able to resolve any conflicts that will have accumulated from offline edits. This potentially massive amount of edits can come as quite a big surprise for other editors.
So, implementing an “offline mode” isn’t just an afterthought–it’s a fundamental design principle that will ultimately affect your choice of tech stack.
Having said that, offline applications are incredibly useful as more and more people are working on unstable networks around the world, from devices while riding on the subway, and of course, proprietary servers and the servers of our providers do not have an uptime of 100% (or even 99.999%).
Best of both worlds?
Now that we’ve covered the landscape at length, we want to invite you enter a fantasy world with us–for just a minute–and imagine a new kind of design, one which actually may not even exist yet, but which embodies the benefits of both the benefits of version control with async collaboration, and full realtime with its fast feedback.
Can you imagine commits in Google Docs, separating the sending of edits and streamlining history controls, while also showing all draft edits in real-time, as they are being drafted? Can you imagine realtime previews of other people’s work, PRs or even commits that are not pushed yet, in IDEs? Or, how about AI batching realtime updates into cohesive commits?
Best for your product…
Think about the possibilities! Then come back to reality and let’s talk about what will work best for your product! If you’re building a multitenant SaaS product, there are many ways to design and build collaboration into it. Hopefully, the options we discussed above will help you envision and plan out your own product strategy. And we are here to talk and help you from many sides: product, design and development, taking into account your goals, priorities and risks. Use the link below to schedule a conversation!

And we’ll see you in the next chapter of this series, where we’ll cover more aspects of multitenant and multiplayer SaaS plus further choices to consider: organizations, permissions, administering access controls, and more!
