Building FEED: the tech behind the app


Topics

We’ve already told the story about how we created the FEED social mobile application. And in this article, we’ve decided to reveal the technologies that we were able to dive into thanks to this project—from Swift and TimescaleDB to the newest machine learning discoveries and other sophisticated and cutting-edge solutions.
Holistic approach
The FEED project started, as usual, with a targeted design sprint. Together with the FEED creative team we designed the first versions of the app’s main screens and brought consistency to the design from the beginning.
Design concept
FEED’s creative team had arrived with their own design concept featuring all the main screens and details on the key mechanics. They determined that the application would be centered on a video feed based on users’ interests. They shaped the overall theme, main colors, and the vibes of the interface, centered around themes like: leisure, fun, clubbing, and featuring bright colors.
We partnered with FEED’s creative team to improve iOS interface patterns, design consistency, and the navigation scheme. Together, we incorporated their colors trying to capture the right vibe, assembled the first version and came up with several more interesting things along the way. For instance, a user watching the event feed can apply the iOS pinch-to-zoom-out gesture to the event card and see the event in relation to other events.

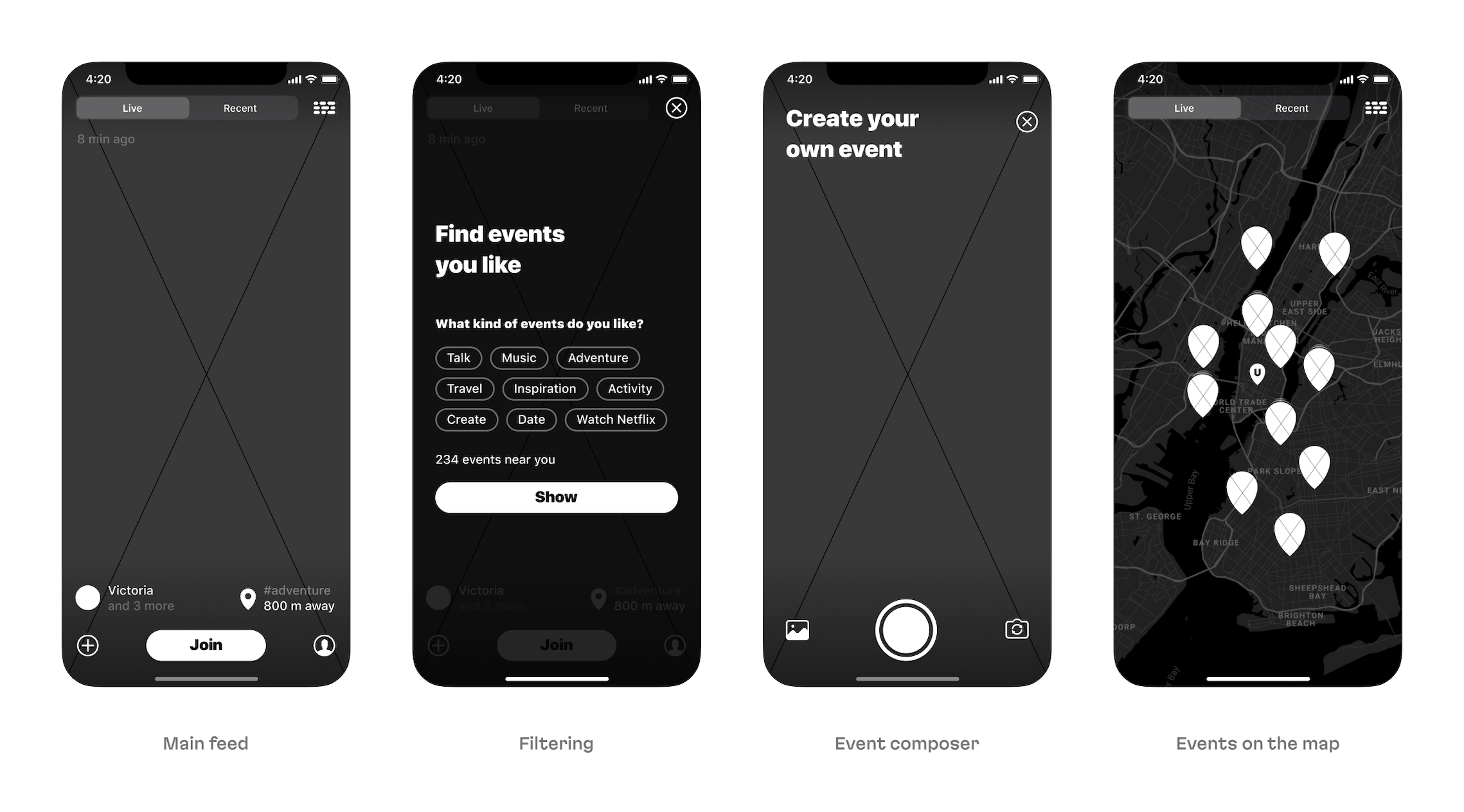
The first sketches we prepared while designing the navigation system
The system
To bring consistency to the design, the FEED and Evil Martians designers assembled all the layouts using components and reused them everywhere to create a unified experience. All the icons had the same bounding boxes and were interchangeable. The FEED team also created a single color palette and text style and we helped them streamlined all the screens. Later, the FEED designers changed the UI colors to make the overall theme more calming and convenient.
This collaboration fueled some ideas on systematic approach: for instance, a screen template that indicated where the iOS safe areas were located and a template to display video card behavior on each screen (since the video has fixed proportions and must be scaled correctly).

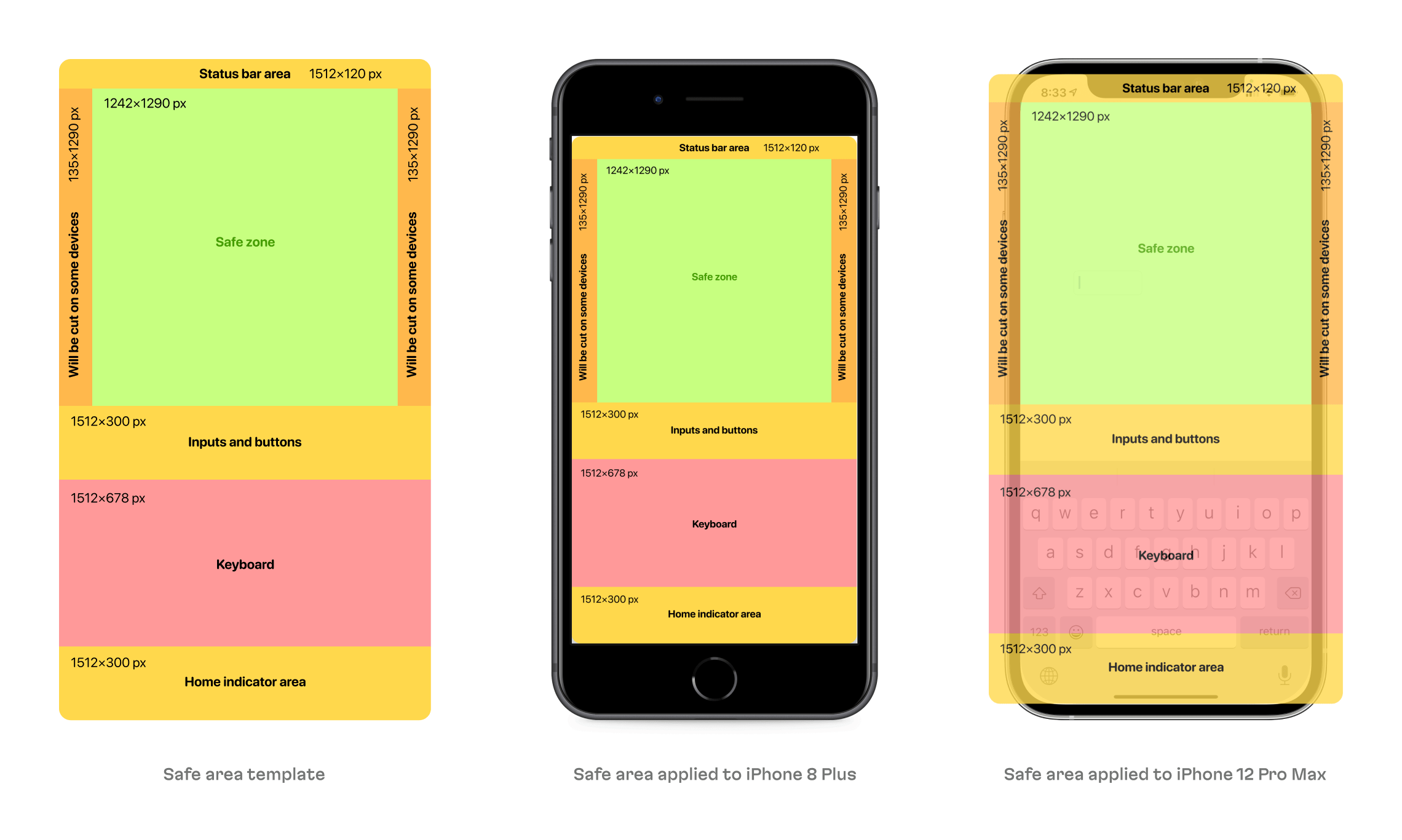
iOS safe areas
Mobile development
On the mobile frontier, users needed to be able to work with media, video, and sound, and to be able to download all of them via 3G and LTE using high-efficiency formats to ensure video quality while keeping data size under control. We were discerning when utilizing SwiftUI in practice, using it only where it was best suited. We also adopted some Clean Architecture ideas across the entire application, covering both SwiftUI and the UIKit components.
We’re quite proud of the complexity and the advanced level of features that we helped create. Let’s review some of them:
Video composer
This video production feature is just one of the app’s key sections that could’ve been a fully-fledged, standalone market product. It allows users to record videos and perform a huge number of operations with video clips: adding various filters and re-recording. Video composer was one of the app’s most sophisticated features and we put a lot of effort into its engineering—with many optimizations and user behavior research.

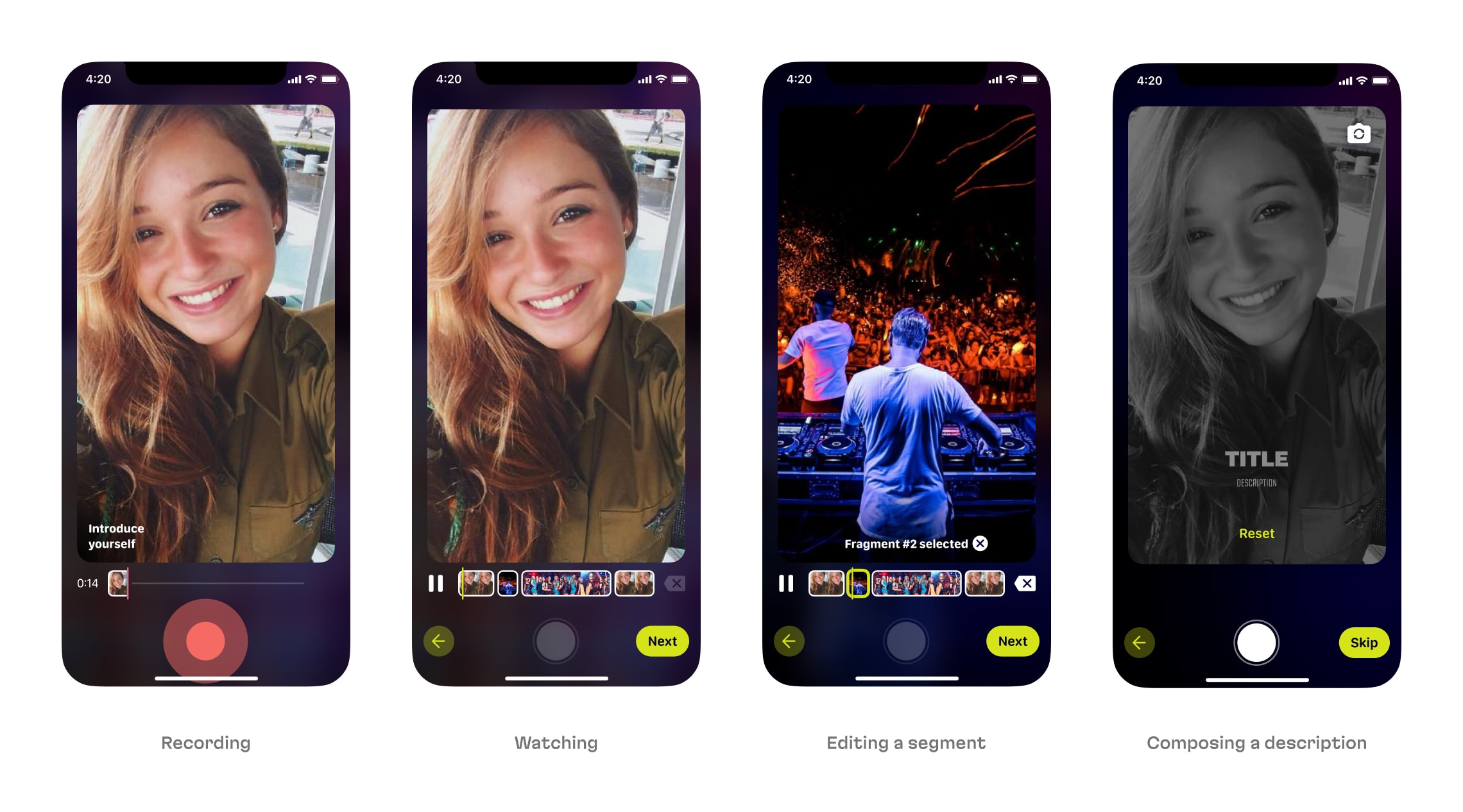
Video composer
Film
The film feature is a collection of the most popular videos that appeared in a certain feed. We implemented statistics for videos—we needed to see views, skips, number of replays, and so on. Then, based on this data, we were able to determine the most popular videos and compose a six-minute film that users can share with friends.
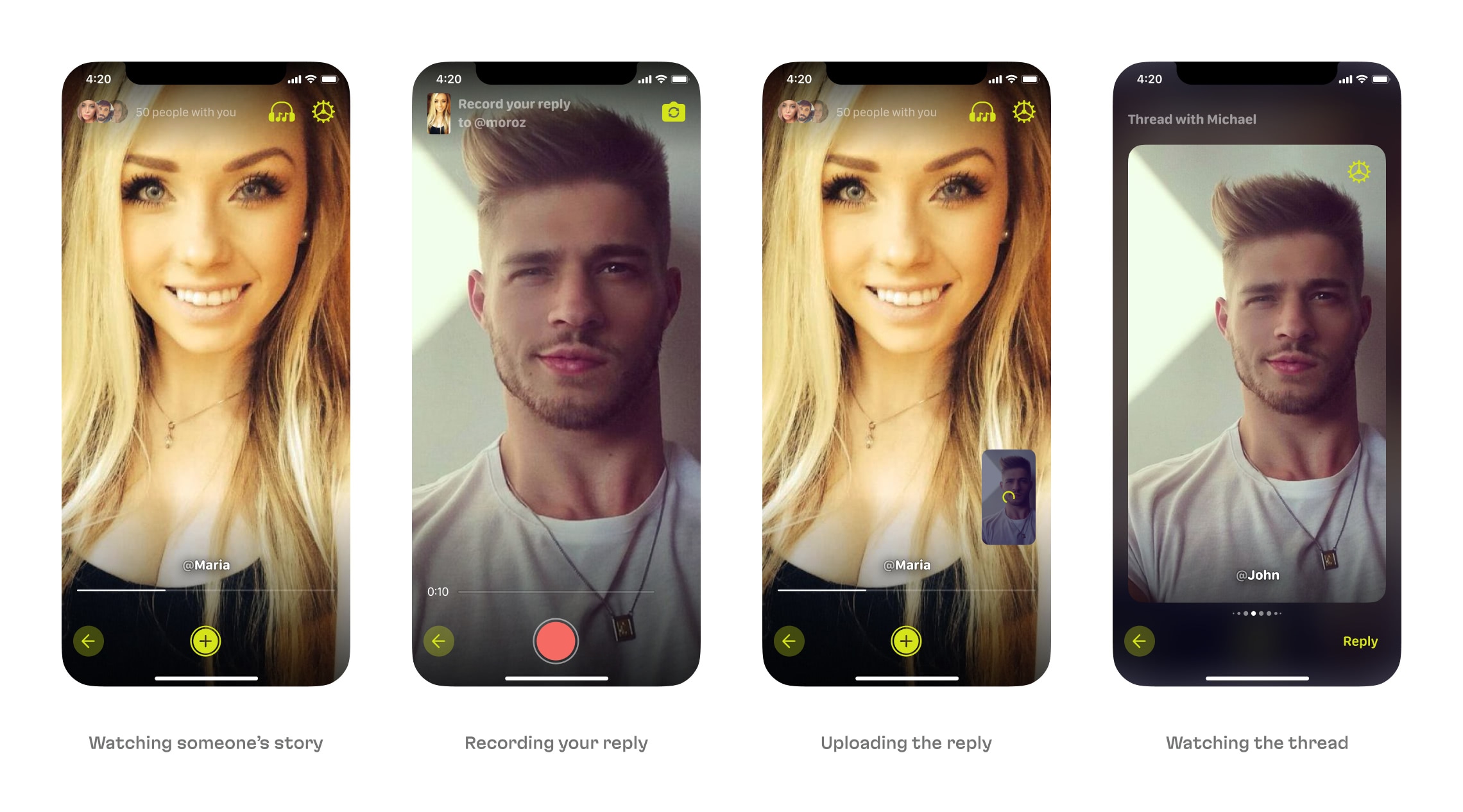
Creating a film
Onboarding
As part of the user onboarding process, we built screens for registration, login, phone number input, and an international phone code picker. We also implemented registration state persistence, saving and restoring the point when users close and open the application to continue the registration process from the same place.
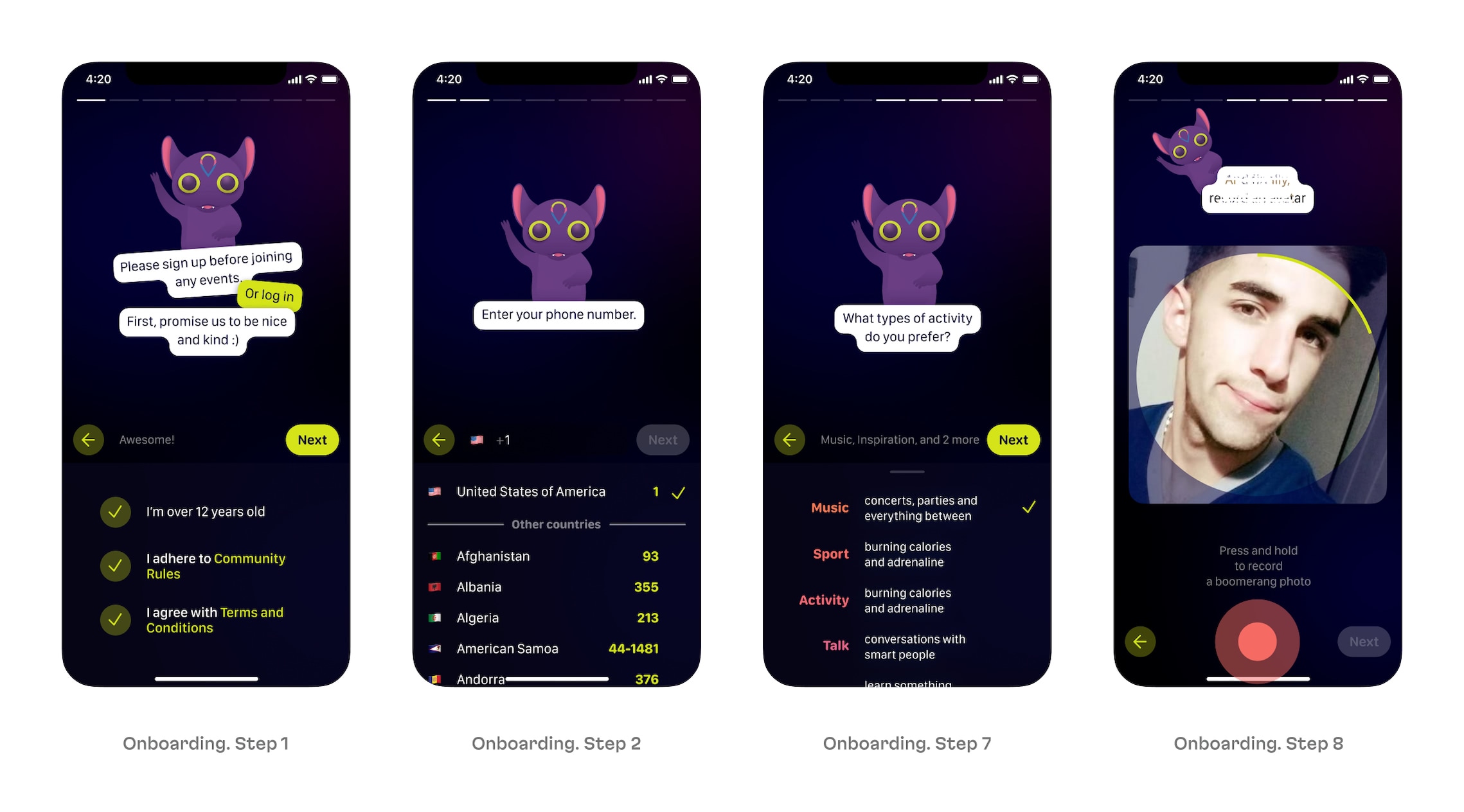
Registration and onboarding process
Feed navigation
This feature allows users to switch between different videos within a feed or a film made from that feed.
The app backend
We covered all of the FEED’s API and the app’s architecture on the backend. Here we continued implanting the modular architecture (aka Rails Engines). All the business logic was spread between the key domains: core, authorization, events, chats, machine learning integration, and the admin dashboard. Communication between them was facilitated through Event-Driven Architecture using the Publish-Subscribe pattern to decrease component coupling.
The backend required a lot of app and database optimizations to prepare for upcoming high loads and to organize the incremental scaling.
Squeezing video to the last byte for performance
We were given an interesting backend technical task to implement custom 6-min user films: we needed the app to compose them from different video clips with overlays naturally embedded into the video. In addition, we needed to apply effects and transitions between the videos. This was a time-consuming operation: film compilation could take as long as 30 minutes. When building an automatic compilation feature using FFmpeg, we tried a ton of different codecs and presets before choosing the perfect combination with Android and iOS support and which offered perfectly compressed video files.
We experimented with video size and found a suitable combo that gave us the best resolution with the smallest file size. First, we opted for Full HD H.265 (HEVC) with the optimal file size. But it didn’t fit the tech requirements and compressed videos slowly. So we chose 960x540 H.264 for better compatibility and did a lot of fine-tuning to get high quality while keeping file sizes small.
We added a process to create small in size, downsampled videos with reduced resolution in advance so that users with a poor connection could also watch them.
APIs everywhere
Any mobile application has to deal with dozens of APIs on the backend, so a significant part of the mobile backend development consists of implementing these APIs. For instance, users needed them to select their basic interests. Using the Interests API, we display up to 70% of the content in the main feed according to these interests; users can immediately see something relevant to them even when they’re just logging in for the first time. Users can add feeds or films to their “favorites” with the Bookmarks API in order to watch them later. With the Viewed Films API, users can monitor the films they have not watched yet in their profiles.
We also had to solve various problems with APIs along the way. For example, with the API for logs that let users see the events of other users in their profiles. The trickiest issue was dividing time and grouping users. With participants in time zones all around the world contributing content at varying frequencies, sometimes we needed to compile a log within the range of a week, or even within a month. Also, we needed to consider the time zone of the user watching the event—10:00 p.m. in one time zone might be the next day in another one. As a result, we created a sophisticated SQL query with many analytical aggregates that worked fast despite its size.
Another complex task was notifying users that their friends had registered in the application and showing a recommendation to follow them. For this, we needed to upload contacts from users’ phones to the server (with their permission, of course). This required some API work since we had to provide both privacy and safety, like including the option to disable phone number search in other people’s contacts.
TimescaleDB
To estimate user ratings based on the number of event views, we used TimescaleDB to calculate how many events a user had created in the previous two weeks. Previously, we used a weekly rollup of views for each event; this feature is built into Timescale. To calculate the statistics for the entire time of each event, we needed to sum up all the weeks in which it received views. Generally speaking, this was a non-typical task for time-series databases. But we migrated to the new Timescale 2.0 and could write our own rollups based on the user actions feature, which the built-in scheduling system launched according to a specific timetable.

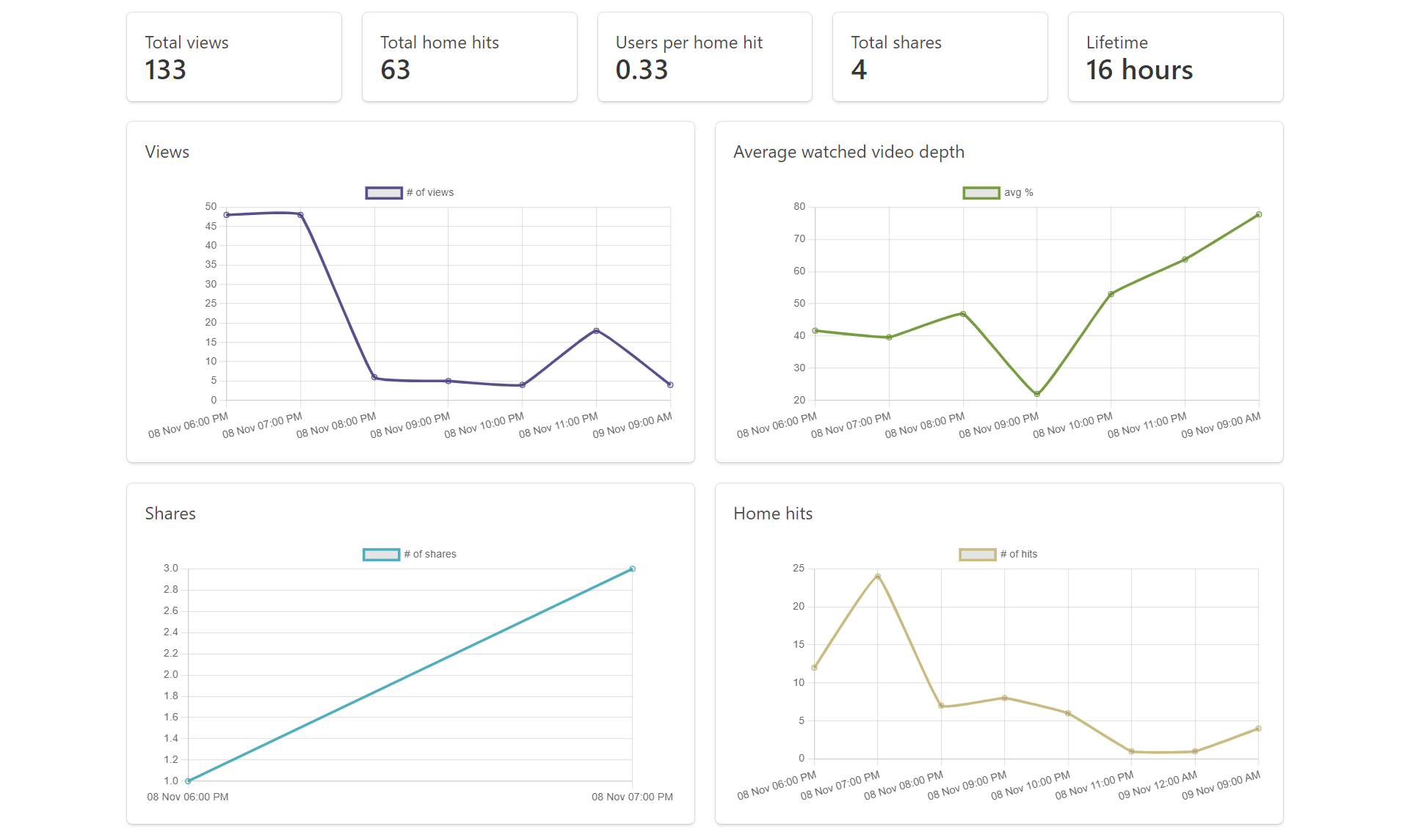
Elasticsearch
The ranking algorithm in the main feed is a critical feature, so we worked extensively on this and we also revised it a few times to ensure quality implementation. The major challenge was to display a feed which would be equally composed of new, popular, and user-interest targeted content. To expand the scope of the feed, we also needed 15% of the feed to come from topics that were not in the user’s interest list.
We had already been using Elasticsearch for this project to search for feeds and users, and we decided then to use its advanced features—the Learning to Rank plugin—to filter/rank search results.
We also created a more advanced formula to equally promote fresh and popular feeds. We increased the size of the explore page to fit up to 576 feeds so fresh or popular content would have the chance to gain more momentum.
Machine learning
During this project, we built the primary machine Learning systems—with Pytorch, OpenCV, ONNX, Core ML, and other libraries and tools. This allowed us to implement more cool, smart, and complex features and at the same time, the product became smoother, smarter, and safer for the users. Here are just a few of them.
Spoken language recognition and classification
This feature was critical because the core team had devised an interesting advertising strategy: embedding ads for a targeted audience naturally in the app’s flow, according to a topic of conversation (for instance, if people were talking about a certain drink, we would display a corresponding ad within the feed).
To determine what people were talking about within the public conversations (all private content is excluded from this process), we needed to classify speech by certain topics and to highlight keywords. Since we first planned to launch into the large markets, English was one of our targeted languages (later, we would add more languages).
We built the solution on an open multi-language dataset from Mozilla. We trained the Spoken Language classifier on its small audio pieces—and the resulting model came out to be fast, so even in the production environment, we didn’t need a server with GPU to process data.
After language identification, we need to get text transcription. We used Vosk—a lightning-fast open source speech-to-text system provided under the Apache2 license, which allows us to use the software for business development. Their pre-trained models work with different languages, including the languages we needed.
After that, we needed to classify the text according to topic—whether it be IT, shopping, or drinks. It was a sophisticated problem since only a few datasets were prepared to train such models. You can easily find a Russian dataset since they have a very strong data science community that deals with such texts, but it wasn’t so easy to do it for the other languages.
As a result of working with so many languages, we had many complex models that were difficult to train and maintain. We ended up using Facebook’s open source LASER library, which translates text to embedding vectors (it represents text as a vector in an N-dimensional space, so the same text in a different language will be very close in that space). Their model turns text into a multidimensional vector, which is perfect for a multi-language classifier. They support 98 languages and it’s fairly good at defining small chunks of textSince we had 15-second video files that needed to be classified into one of a hundred categories, the task was simple. We adapted this library for our engineering: we wrote the code, wrapped it, simplified it, and eventually got the proper solution.
NSFW identification
We didn’t want to deal with any “not safe for work” content in the app, so we used a neural network to determine it in advance. We managed to reuse the face recognition pipeline, which quickly processed the video stream, cut frames, reduced their size, transformed, and integrated it into the network to check the content. We would mark the video as “checked” if everything was legitimate. Meanwhile, it would send suspicious content to moderators. If the neural network was fairly certain that there was restricted content present, it blocked the video, hid it from the stream, marked the user, and sent an urgent request to the moderation team to check the respective user and the video.
Audio denoising
We adopted an advanced C library, RNNoise, for audio denoising and built it into our processes, as it was very small and performed really well.
Optimizations
We created our machine learning system to be automatically retrainable, deployable, and scalable. We “squeezed” the model sizes to have sufficient quality and speed with regards to video content processing, and with no video card required—running several small Kubernetes pods with 4 processors was enough to handle everything.
To use the models inside our service, we first wrapped them in a web service. However, we soon realized that there was too much data to send over the web. Then we decided to use Faktory to run models as background tasks on a powerful engine. This is a background task processing product similar to Sidekick as used in the world of Rails, and it was built by the same author. It fit perfectly alongside our Rails code and Python-written machine learning features.
ML system scalability
Faktory allowed us to wrap everything in a Docker container which was deployed to a Kubernetes cluster. We gained scalability thanks to this since we could create as many workers as we needed by increasing the number of pods. And, as the FEED app runs on Google Cloud, we also had the benefit of working with more resources at our disposal—therefore, we could process a lot of videos in parallel.
Retraining
We saved all the data we collected to the database (face vectors for re-identification, intermediate training results, etc.) Once a week, data was gathered into a CSV (comma-separated values) file, uploaded to Google Cloud Storage (GCS), and we ran a retraining task in the Faktory worker. The file from GCS was put to a training stack (this used different technologies than the production stack: the latter used weights, compressed in ONNX format, and the training stack ran the model training PyTorch framework).
The training stack downloaded the data and checked if it had changed (since some data went to moderators to review the proper classification). We then trained the models and used the final validation metric to check their performance against previous versions of this model. We compared it with the previous one and loaded the updated model to S3 only when the metrics were improved. We launched the consecutive containers with elevated models.
Infrastructure optimization and deployment
The next stage was the project’s production. Obviously, an app like a video social network is prone to extreme fluctuations with regards to processing power demand and it also must be scalable—as in, auto-scalable 🤖. Thus, we had to use cloud infrastructure, and what better and more controllable way to do that than with Kubernetes? We chose Google Cloud Platform (GCP) for the cloud and its managed Google Kubernetes Engine (GKE) service.
Everything, besides managed databases, deploys and runs on Kubernetes.
Kubernetes is a complex platform that requires deep hands-on experience. Though GitOps is not without drawbacks, it is still one of the better ways to manage infrastructure. We rely on Terragrunt to manage the objects of GCP itself. For managing Kubernetes clusters’ objects we use Argo CD setup. Our default Argo CD setup brings all of the essentials a project might need: a carefully polished Prometheus monitoring setup (and it’s prepared to handle application monitoring, too), logs aggregation, a couple of Ingress controllers, and some operators.
A load of load testing
The interesting challenge was load testing. There were three sub-challenges here: the aforementioned video processing, the app’s stress tests, and dealing with network delays. Did we mention auto-scaling before? Here’s where it really got the chance to shine! This was the perfect moment to prepare and test the application’s scalability. Google Cloud can scale your node pools up and down, but it can’t do the same with your app’s Pods. Kubernetes handles this in the blink of an eye thanks to its Horizontal Pod Autoscaling. Still, it takes a real engineer (a Martian one, in our case) to decide what metric is the best to rely on.
Incidentally, were you aware that if you’re not operating as a “widely-known” person or service, you may—literally—run into limits? Cloud providers have actual quotas for different kinds of cloud resources: nodes, CPUs, memory, storage, etc. These differ not only from region to region, but from customer to customer. That’s why we recommend being careful with the situations when you reach quotas for load testing and actual scalability testing because Google can reject you during the default quota increase procedure. For instance, we held a number of lengthy video-call negotiations with the Google Cloud team to validate why we needed so many nodes.
Cloud providers have a lot of node type options, and many of them are shared, so there is always the possibility you might not get full performance from a virtual node from time to time. But we had to be certain that our video processing time would be controllable and fast, and it had to be so without burning money like rocket fuel. We did a number of stress tests to determine which configuration was the best and the most predictable based on the budget.
Once the project started to reach the pre-release state we began the stress testing process with the help of k6 by Grafana Labs. This was done to ensure that our app and the infrastructure we built could deal with the rush of new users. The goal for the initial release was to handle at least 300,000 RPM. There is no silver bullet for such a test, but we invested a lot of time to create a realistic user behavior profile to generate the load.
Here came the network delays—and more tuning. FEED is a social app, so it’s pretty demanding. We noticed that some PostgreSQL and Redis requests were taking more time to complete than expected. Here we had to dig into the code and thoroughly benchmark the network speed and delays between the different node types. It turned out there was room for improvement in both directions.
Solving the database issue
We also bumped into one more cost vs. value problem along the way: TimescaleDB. It’s actually the only database we host inside Kubernetes. Why is that so? The quick answer is that the managed version of TimescaleDB was too expensive for our load profile. The longer and more interesting answer involves a discussion on just how the managed version of TimescaleDB is configured. It has a very limited number of connections, even with rather large node types, but our project is ready to run hundreds of nodes and Faktory workers any time the load comes. Because of how we were working with TimescaleDB data, we needed hundreds of connections rather than hundreds of GBs of memory. Thus, we decided to host TimescaleDB on our own. And it turned out the TimescaleDB team had done a great job making and publishing a Helm chart for just that—kudos to them!
This project was another great learning experience for our team. We believe it’s proven once again that—with talented developers and a concentrated effort—even when a project utilizes sophisticated technologies, it doesn’t mean it must have a sophisticated or complex architecture, a difficult and protracted engineering process, or expensive solutions. Thanks to the FEED project, we’ve shown we can implement a solution quickly, and with cost-effectiveness in mind.

All that we’ve accomplished, plus the hard work of the FEED core team, resulted in the creation of one of the most eye-catching social apps, based on a really fresh concept. To date, FEED has launched in 35 countries on the App Store, including the USA, Canada, and most of Europe.
If you want to build a mobile application with sophisticated and cutting-edge technology, you know where to find us.